How to Bypass Akamai With Playwright
Advanced Data Extraction Specialist
Akamai is a formidable barrier for web scrapers due to its advanced security measures, including bot detection and mitigation systems designed to protect websites from automated traffic. Playwright, a robust automation library, excels at rendering JavaScript-heavy pages and simulating user interactions, making it a favorite for web scraping. However, its base version often fails against Akamai’s sophisticated defenses. This article explores why base Playwright isn’t enough and details the best methods to bypass Akamai, with Scrapeless as the recommended solution. We’ll provide step-by-step guides with code examples, graphic descriptions, and a technical deep dive into Akamai’s detection mechanisms.
Why Base Playwright Isn’t Enough to Bypass Akamai
Playwright’s strength lies in its ability to control headless browsers like Chromium, Firefox, and WebKit, rendering dynamic content seamlessly. Yet, when scraping Akamai-protected sites, it encounters roadblocks due to Akamai’s multi-layered detection techniques:
- Browser Fingerprinting: Akamai checks properties like
navigator.webdriver(set totruein headless mode) to identify automation tools. - IP Analysis: It flags data center IPs or those with suspicious activity patterns.
- Behavioral Checks: It monitors mouse movements, click patterns, and navigation sequences to distinguish bots from humans.
To illustrate, let’s try scraping an Akamai-protected site like Zalando using base Playwright:
# pip install playwright
# playwright install
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
context = browser.new_context()
page = context.new_page()
page.goto("https://www.zalando.com")
page.wait_for_load_state("networkidle")
content = page.content()
print(content)
browser.close()Result: The request is blocked, and the output reveals an "Access Denied" page.
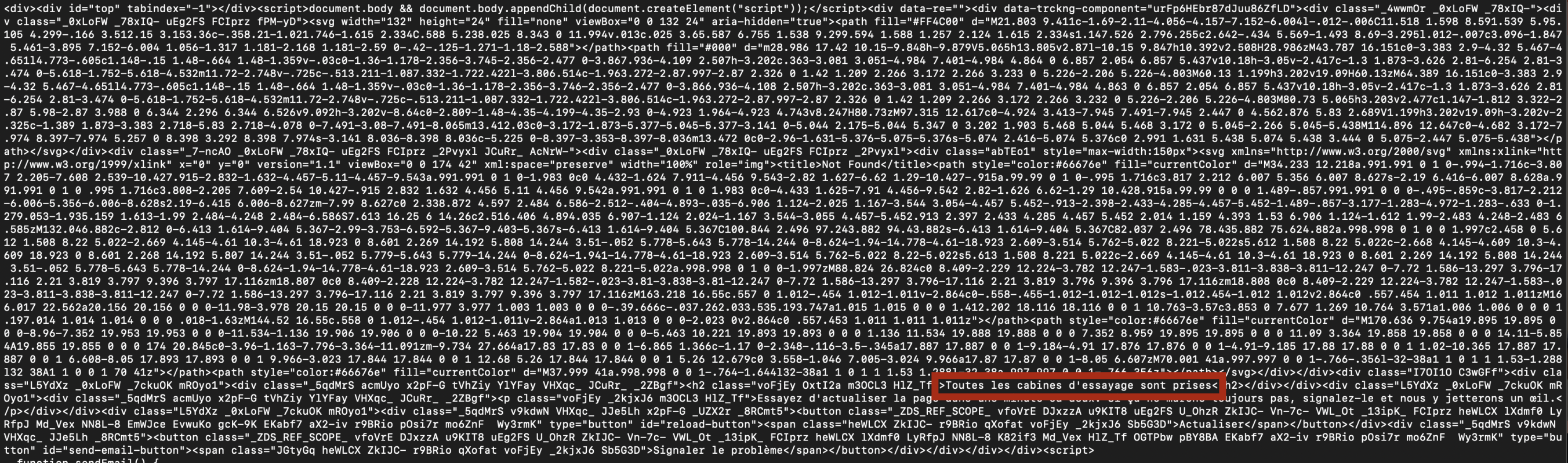
This failure underscores the need for advanced bypassing strategies, which we’ll explore next.
Best Methods to Bypass Akamai With Playwright
To overcome Akamai’s defenses, we’ll detail three methods: using Scrapeless (the recommended approach), the Playwright Stealth plugin, and premium proxies. Each method includes detailed steps, code, and graphic descriptions.
Method 1: Use Scrapeless to Bypass Akamai(Recommended)
Scrapeless is a web scraping API tailored to defeat anti-bot systems like Akamai. It generates critical tokens (e.g., _abck and bm_sz cookies, sensor data) and manages proxies, ensuring high success rates with minimal effort. By integrating Scrapeless with Playwright, you can bypass Akamai’s checks effectively.
Why Scrapeless Excels
- Token Generation: Provides Akamai-specific cookies and sensor data to pass initial verification.
- Proxy Rotation: Uses premium proxies to mask your IP and avoid blocks.
- Ease of Use: Handles complex bypassing logic, reducing manual configuration.
Step-by-Step Guide
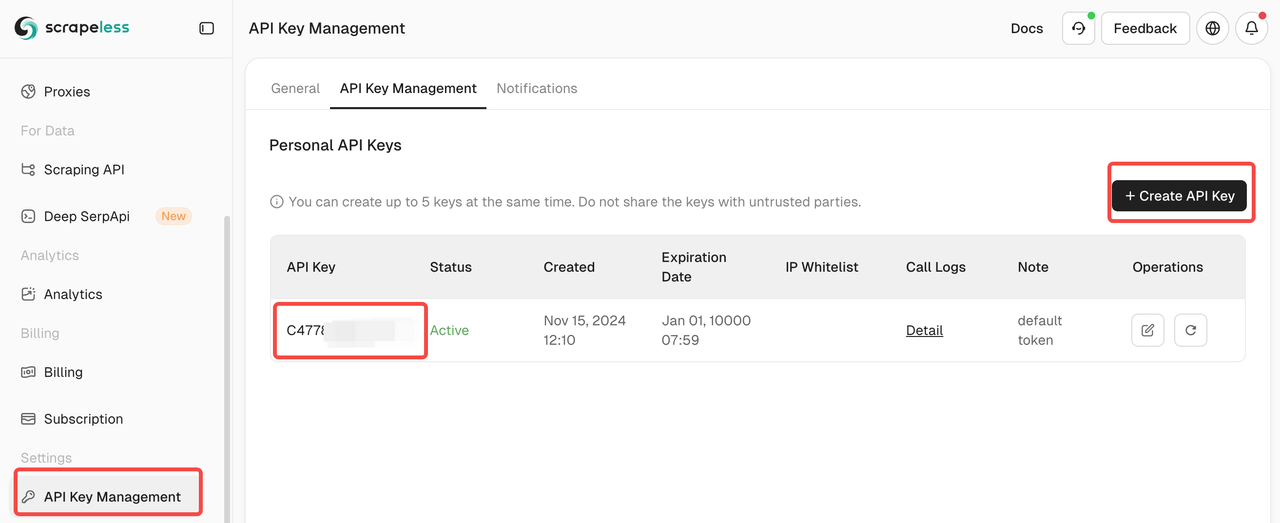
- Sign Up and Get API Key
- Register at Scrapeless and retrieve your API key from the dashboard.
Unlock Faster, More Efficient Web Scraping Today!
Bypass Akamai and scale your web scraping tasks effortlessly with Scrapeless. Get started now and experience seamless integration with advanced scraping tools!
Log in to Scrapeless now.
- Generate Akamai Cookies
- Use the Scrapeless /api/v1/unlocker/request endpoint (Web Unlocker: Akamaiweb Cookie) to fetch _abck and bm_sz cookies.
- Code:
import http.client
import json
conn = http.client.HTTPSConnection("api.scrapeless.com")
payload = json.dumps({
"actor": "unlocker.akamaiweb",
"input": {
"type": "cookie",
"url": "https://www.zalando.fr/release-calendar/homme-sneakers/",
"userAgent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36",
},
"proxy": {
"country": "FR"
}
})
headers = {
'Content-Type': 'application/json',
'x-api-token': 'YOUR API KEY'
}
conn.request("POST", "/api/v1/unlocker/request", payload, headers)
res = conn.getresponse()
data = res.read()
print(data.decode("utf-8"))
- Set Cookies in Playwright: Not Recommended
While injecting cookies into Playwright is technically possible, it's generally not the best approach for bypassing Akamai protections. Automated browsers like Playwright have numerous "fingerprints" that make them easily detectable, even with valid cookies.
Why it's problematic:
- Modern websites easily detect automated browsers through JavaScript fingerprinting
- Akamai cookies often have additional properties tied to the original browser
- The way Playwright executes JavaScript differs from a normal browser
Recommended alternative:
- Use a simple HTTP request with appropriate cookies and headers
- Code for HTTP request:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Sec-Fetch-Dest": "document"
}
cookies = {
"_abck": "0E868C6CC7CA82A40139ACBF093E8CDE~-1~YAAQyIMQAoFI7L2VAQAA4tUo6Q1z...",
"bm_sz": "BF4B4DAA3C6506FF52A615374EA95300~YAAQyIMQAj5B7L2VAQAA474o6Rv..."
}
response = requests.get("https://www.zalando.com", headers=headers, cookies=cookies)
content = response.text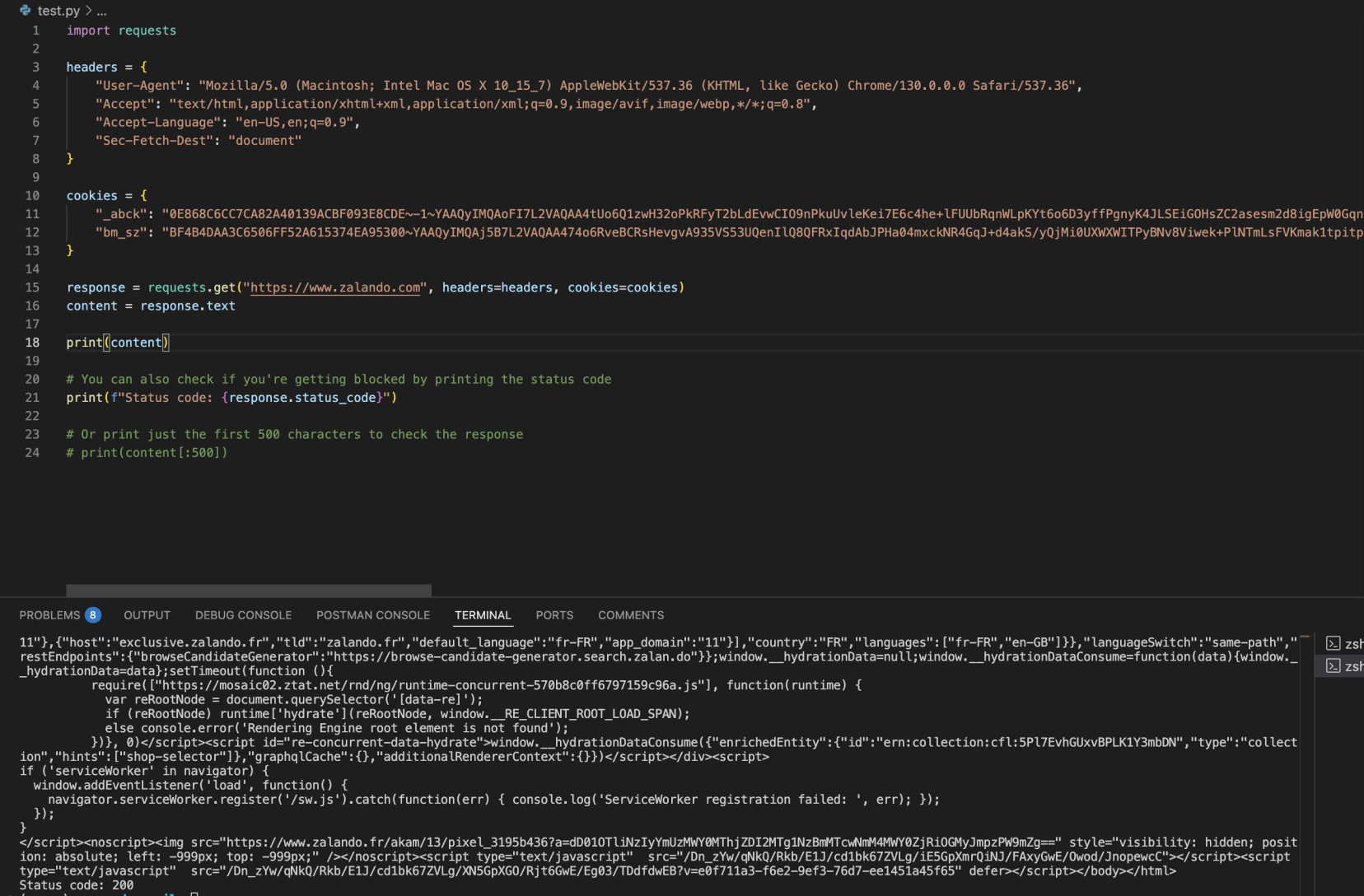
Handle Sensor Data (If Needed)
- For sites requiring sensor data, use the "Akamaiweb Sensor" endpoint and inject it via Playwright.
- Refer to Scrapeless Documentation for specifics.
Advantages
Scrapeless simplifies bypassing Akamai by automating token generation and proxy management, offering a 90%+ success rate based on its optimized infrastructure.
Method 2: Use the Playwright Stealth Plugin to Bypass Akamai
The Playwright Stealth plugin modifies Playwright to evade basic detection by altering browser fingerprints (e.g., hiding navigator.webdriver).
The steps to use the Playwright Stealth Plugin to Bypass Akamai are as follows:
- Install the Plugin
- Run: pip install playwright-stealth
- Apply Stealth to Playwright
- Code:
from playwright.sync_api import sync_playwright
from playwright_stealth import stealth_sync
with sync_playwright() as p:
browser = p.chromium.launch()
context = browser.new_context()
page = context.new_page()
stealth_sync(page)
page.goto("https://www.zalando.com/")
content = page.content()
print(content)
browser.close()
Limitations
While effective against simpler anti-bot systems, Stealth struggles with Akamai’s advanced checks (e.g., sensor data validation), making it less reliable.
Method 3: Use Premium Proxies to Bypass Akamai
Premium proxies mask your IP and rotate addresses to evade IP-based blocks, a key component of Akamai’s defenses.
The Steps to Use Premium Proxies to Bypass Akamai
- Obtain Premium Proxy Credentials
- Sign up with a provider like Scrapeless, Bright Data or Smartproxy for high-anonymity proxies.
- Integrate with Playwright
- Code:
from playwright.sync_api import sync_playwright
proxy_server = "http://premium_proxy:port"
proxy_username = "username"
proxy_password = "password"
with sync_playwright() as p:
browser = p.chromium.launch(
proxy={
"server": proxy_server,
"username": proxy_username,
"password": proxy_password
}
)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.zalando.com/")
content = page.content()
print(content)
browser.close()Note
Proxies alone may not suffice against Akamai’s behavioral and fingerprinting checks, so combining them with Scrapeless is ideal.
Technical Analysis: How Akamai Detects and How to Counter It
Akamai’s bot detection is a multi-faceted system, and understanding it is key to bypassing it effectively.
Akamai’s Detection Mechanisms
- Cookies (
_abck,bm_sz)
- These track session integrity and user behavior. The _abck cookie, for instance, is a dynamic token tied to browser fingerprints and IP data.
- Counter: Scrapeless generates valid cookies via its "Akamaiweb Cookie" endpoint, mimicking legitimate sessions (Scrapeless Docs).
- Sensor Data
- A JavaScript payload collects browser environment details (e.g., screen size, plugins, mouse events) to build a unique fingerprint.
- Counter: Scrapeless’s "Akamaiweb Sensor" endpoint provides pre-validated sensor data, injectable into Playwright requests.
- Behavioral Analysis
- Tracks navigation patterns and interaction timing to flag non-human behavior.
- Counter: Scrapeless likely uses machine learning to simulate human-like patterns, though this is proprietary.
- IP Reputation
- Blocks IPs associated with bots or data centers.
- Counter: Scrapeless’s premium proxies rotate IPs, maintaining high anonymity.
Scrapeless’s Technical Edge
Per the Scrapeless Web Unlocker documentation, its Akamai-specific endpoints leverage reverse-engineered solutions to produce tokens that align with Akamai’s expectations. For example, the _abck cookie includes encrypted data reflecting user-agent and proxy details, ensuring consistency across requests. This automation eliminates the need for manual script analysis, which is prone to obsolescence as Akamai updates its algorithms.
Unblock Akamai and Scrape Like a Pro
Discover the best tool for seamless web scraping! Scrapeless offers advanced features to bypass Akamai without coding headaches.
Log in to Scrapeless today and get started.
Conclusion
Bypassing Akamai with Playwright demands more than its base capabilities. The Playwright Stealth plugin and premium proxies offer partial solutions, but Scrapeless emerges as the most reliable method. By integrating Scrapeless’s API with Playwright, you can generate essential cookies and sensor data, sidestepping Akamai’s defenses with ease and precision. For robust, hassle-free scraping, Scrapeless is the go-to choice.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


