
How to Bypass a Cloudflare-Protected Website?
Senior Web Scraping Engineer
Websites protected by Cloudflare can be some of the most difficult to scrape. Its automatic bot detection requires you to use a powerful web scraping tool to bypass Cloudflare's anti-scraping measures and extract its web page data.
Today, we'll show you how to scrape websites protected by Cloudflare using Python and the open source Cloudscraper library. That being said, while effective in some cases, you'll find that Cloudscraper has some limitations that are hard to avoid.
What Is Cloudflare Bot Management?
Cloudflare is a content delivery and web security company. It offers a web application firewall (WAF) to protect websites from security threats such as cross-site scripting (XSS), credential stuffing, and DDoS attacks.
One of the core systems of Cloudflare WAF is Bot Manager, which mitigates attacks by malicious bots without affecting real users. However, while Cloudflare allows known crawler bots such as Google, it assumes that any unknown bot traffic (including web crawlers) is malicious.
Introduction to Cloudflare WAF
Cloudflare WAF is a key component in Cloudflare's core protection system, designed to detect and block malicious requests by analyzing HTTP/HTTPS traffic in real time. It filters potential threats such as SQL injection, cross-site scripting (XSS), DDoS attacks, etc. based on rule sets (including predefined rules and custom rules).
Cloudflare WAF combines IP reputation database, behavioral analysis model and machine learning technology, and can dynamically adjust protection strategies to respond to new attacks. In addition, WAF is seamlessly integrated with Cloudflare's CDN and DDoS protection to provide multi-level security for websites while maintaining low latency and high availability for legitimate users.
From the table below, you can clearly see the protection measures of WAF and the difficulty of cracking:
| Protection layer | Technical principle | Difficulty of cracking |
|---|---|---|
| IP reputation detection | Analysis of IP historical behavior (ASN/geolocation) | ★★☆☆☆ |
| JS challenge | Dynamically generate math problems to verify browser environment | ★★★☆☆ |
| Browser fingerprint | Canvas/WebGL rendering feature extraction | ★★★★☆ |
| Dynamic token | Timestamp-based encrypted token verification | ★★★★☆ |
| Behavior analysis | Mouse trajectory/click pattern recognition | ★★★★★ |
How does Cloudflare detect bots?
Cloudflare's bot management system is designed to differentiate between malicious bots and legitimate traffic (such as search engine crawlers). By analyzing incoming requests, it identifies unusual patterns and blocks suspicious activity to maintain the integrity of your sites and applications.
Its detection methods can be either passive or active. Passive bot detection techniques use backend fingerprinting, while active detection techniques rely on client-side analysis.
- Passive bot detection techniques
- Detecting botnets
- IP address reputation
- HTTP request headers
- TLS fingerprinting
- HTTP/2 fingerprinting
- Active bot detection techniques
- CAPTCHAs
- Canvas fingerprinting
- Event tracing
- Environment API queries
3 Main Error of Cloudflare
- Cloudflare Error 1015: What Is It and How to Avoid
- Cloudflare Error 1006, 1007, 1008: What They're and How to Fix
- Cloudflare 403 Denied: Bypass This Issue
How to Scrape a Cloudflare-Protected Website?
Step 1: Set Up the Environment
First, ensure that Python is installed on your system. Create a new directory to store the code for this project. Next, you need to install cloudscraper and requests. You can do this via pip:
Shell
$ pip install cloudscraper requestsStep 2: Make a Simple Request Using requests
Now, we need to scrape data from the page at https://sailboatdata.com/sailboat/11-meter/ . A portion of the page content looks like this:
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
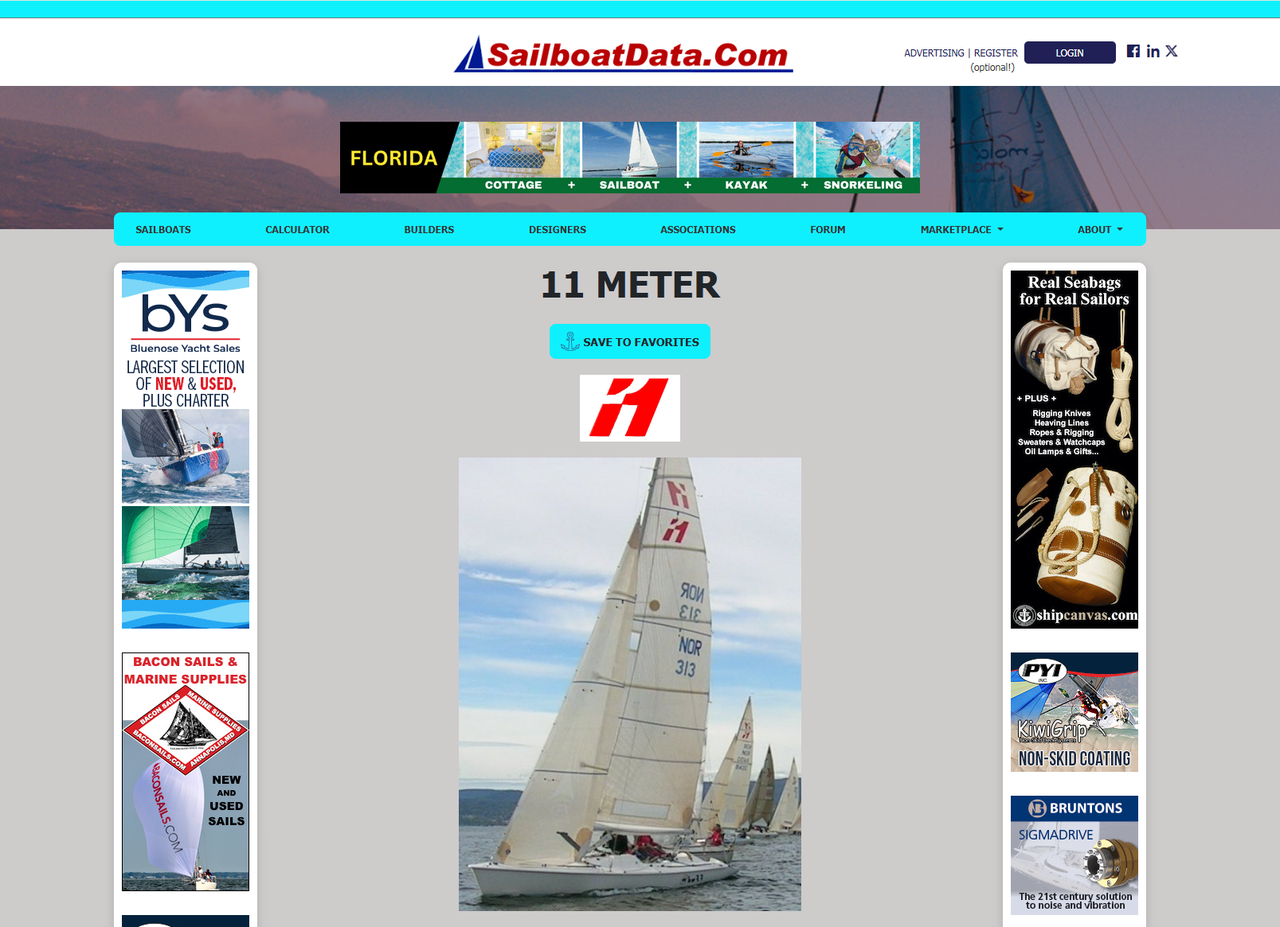
Let's first try sending a simple GET request using requests to confirm:
Python
def sailboatdata():
html = requests.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 403
with open("response.html", "wb") as f:
f.write(html.content)As expected, the webpage returns a 403 Forbidden status code. We’ve saved the response in a local file. The specific source code of the returned content is shown below:

The target website is protected, and the local file cannot be opened properly. Now, we need to find a way to bypass this.
Step 3: Scrape Data Using Cloudscraper
Let's use Cloudscraper to send the same GET request to the target website. Here’s the code:
Python
def sailboatdata_cloudscraper():
scraper = cloudscraper.create_scraper()
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")
print(html.status_code) # 200
with open("response.html", "wb") as f:
f.write(html.content)This time, Cloudflare did not block our request. We open the saved HTML file locally and view it in the browser. The page looks like this:
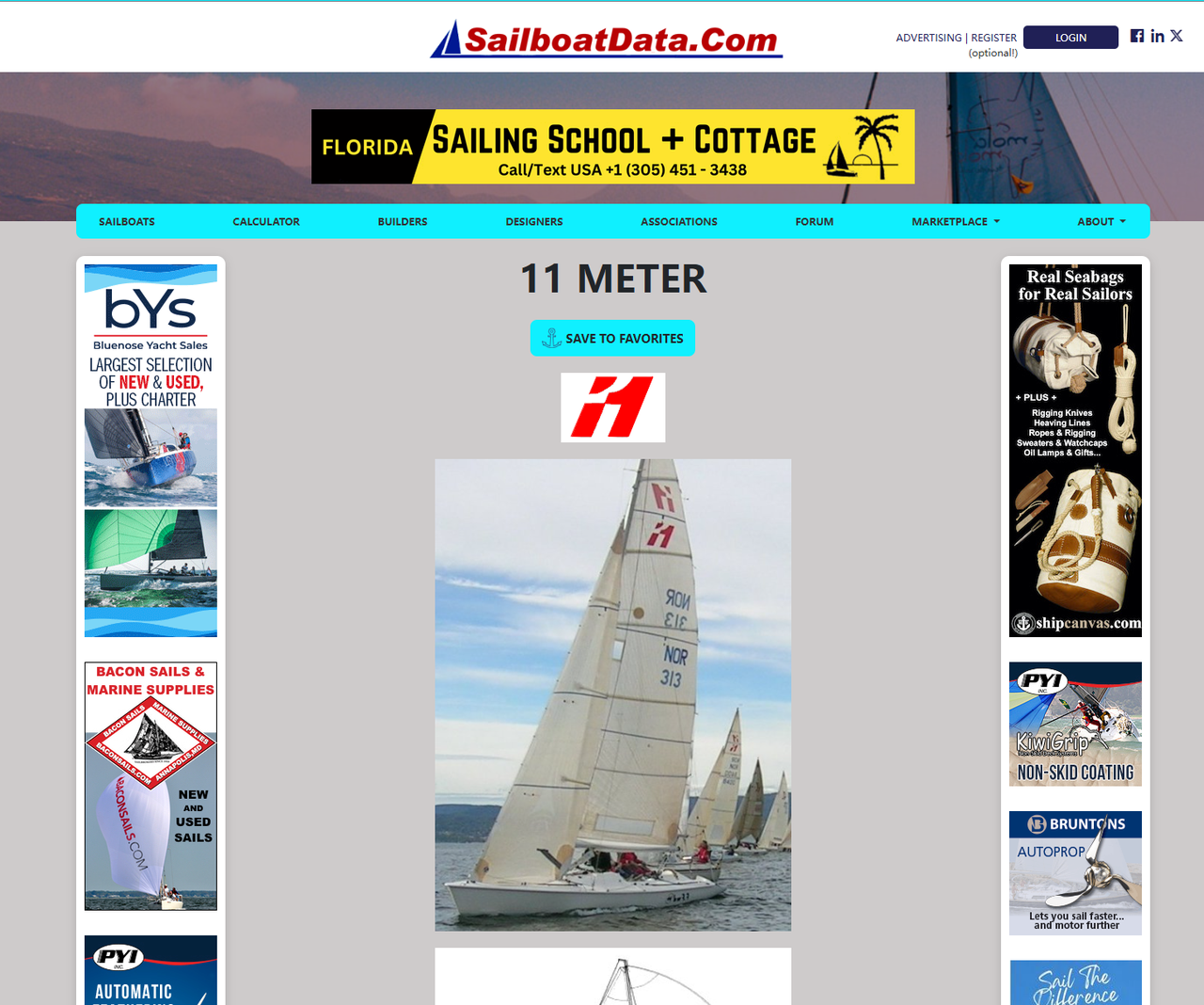
Advanced Features of Cloudscraper
Built-in CAPTCHA Handling
JavaScript
scraper = cloudscraper.create_scraper(
captcha={
'provider': '2captcha',
'api_key': '2captcha_api_key'
}
)Custom Proxy Support
Python
proxies = {"http": "your proxy address", "https": "your proxy address"}
scraper = cloudscraper.create_scraper()
scraper.proxies.update(proxies)
html = scraper.get("https://sailboatdata.com/sailboat/11-meter/")Scrapeless Scraping Browser: A More Powerful Alternative to Cloudscraper
Limitations of Cloudscraper
Cloudscraper has some limitations when dealing with certain Cloudflare-protected websites. The most notable issue is that it cannot bypass Cloudflare's robot detection v2 protection mechanism. If you try to scrape data from such a website, you will trigger the following error message:
JSON
cloudscraper.exceptions.CloudflareChallengeError: Detected a Cloudflare version 2 challenge, This feature is not available in the opensource (free) version.In addition, Cloudscraper is also unable to cope with Cloudflare's advanced JavaScript challenges. These challenges often involve complex dynamic calculations or interactions with page elements, which are difficult for automated tools such as Cloudscraper to simulate in order to pass the verification.
Another problem is Cloudflare's rate limiting policy. To prevent abuse, Cloudflare strictly controls the request frequency, and Cloudscraper lacks an effective mechanism to manage these limits, which may cause request delays or even failures.
Last but not least, as Cloudflare continues to upgrade its bot detection technology, it is difficult for Cloudscraper, as an open source tool, to keep up with these changes. Over time, the effectiveness and stability of its functionality may gradually decrease, especially in the face of new versions of protection mechanisms.
Why is Scrapeless effective?
Scraping Browser is a high-performance solution for extracting large amounts of data from dynamic websites. It allows developers to run, manage, and monitor headless browsers without dedicated server resources. It is designed for efficient, large-scale web data extraction:
- Simulate real human interaction behaviors to bypass advanced anti-crawler mechanisms such as browser fingerprinting and TLS fingerprinting detection.
- Support automatic resolution of multiple types of verification codes, including cf_challenge, to ensure uninterrupted crawling process.
- Seamless integration of popular tools such as Puppeteer and Playwright to simplify the development process and support single-line code to start automated tasks.
How to integrate the Scraping Browser bypass Cloudflare?
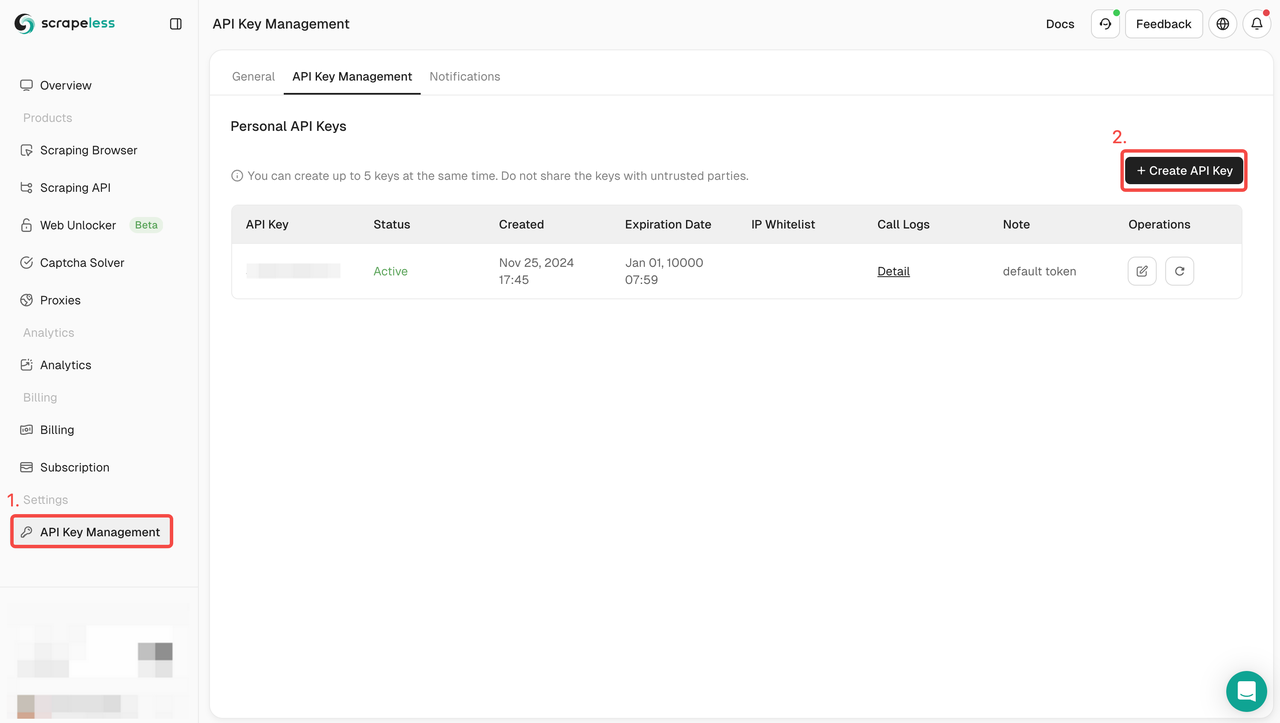
Step 1. Create your API token
- Sign up for Scrapeless
- Choose API Key Management
- Click Create API Key to create your Scrapeless API Key.
Scrapeless ensures seamless web scraping.
🎁 Join Discord and Claim your free trial now!
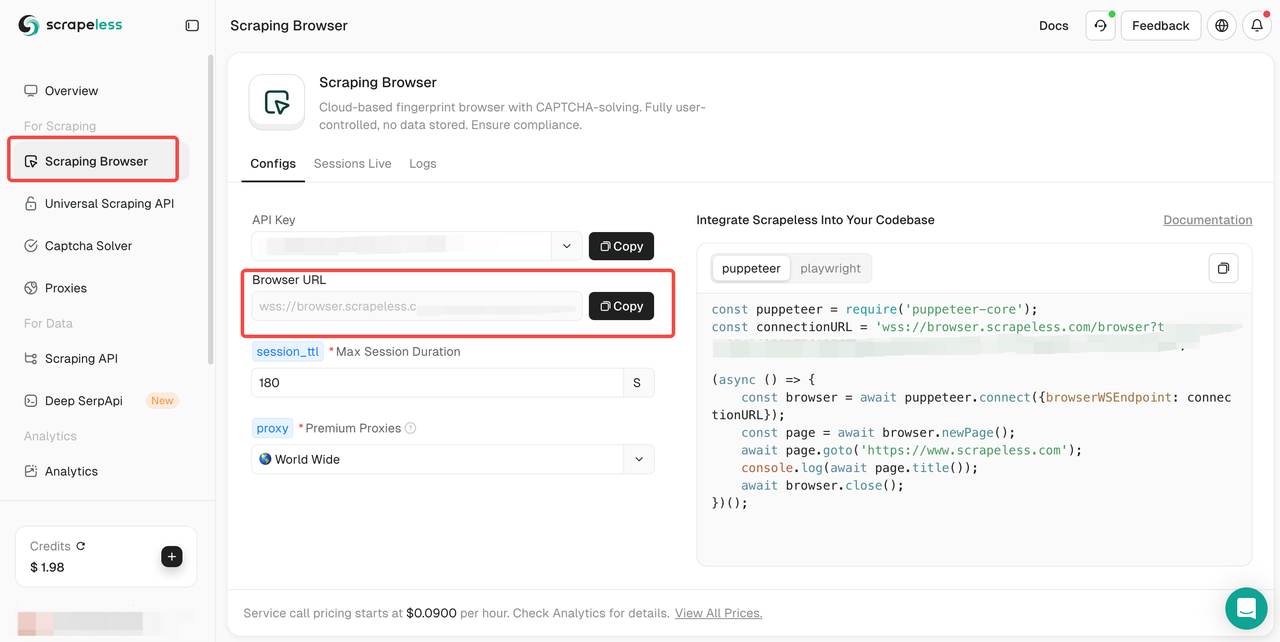
Step 2. Then, go to Scraping Browser and copy your Browser URL.
Or you can check our request code as a reference:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_API_TOKEN>&session_ttl=180&proxy_country=ANY';
(async () => {
const browser = await puppeteer.connect({browserWSEndpoint: connectionURL});
const page = await browser.newPage();
await page.goto('https://www.scrapeless.com');
console.log(await page.title());
await browser.close();
})();Step 3. Integrate the code or browser URL into your Puppeteer script:
JavaScript
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// set up browser environment
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// create a new page
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'networkidle0',
}); // Replace with your target URL
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
//take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();4 Tips for Bypassing Cloudflare
If you want to hack Cloudflare yourself, it will be very difficult! You have to consider all the defenses Cloudflare has against bots and find ways to overcome them. Most people will definitely not choose to do this.
Do you want to give it a try? Here are a few tips to help you bypass Cloudflare:
JavaScript rendering
Cloudflare often uses JavaScript challenges to detect bots. These scripts are embedded in web pages and perform specific checks through the browser to determine whether the visitor is a bot. If a bot is suspected, Cloudflare will display a CAPTCHA (such as Turnstile verification code), otherwise it will allow normal access.
Therefore, to crawl protected pages, you need to use browser automation tools such as Playwright, Selenium or Puppeteer to simulate real user interactions. However, the default configuration of headless browsers may be exposed to anti-bot systems. It is recommended to use Playwright Stealth or Puppeteer Stealth libraries to hide automation traces.
CAPTCHA solving
CAPTCHA is a key test to distinguish bots from humans. It may include simple click verification or complex puzzles. Automatically parsing CAPTCHA is difficult, so you can try to bypass it with Python technology or use Bright Data's Cloudflare Turnstile Solver to automatically solve it.
Rate limit avoidance
Cloudflare will trigger rate limits for too many requests in a short period of time, which may cause the IP to be temporarily or permanently blocked. To avoid this problem, it is recommended to use a proxy service (such as a residential proxy) to implement IP rotation and disguise the request as a real device.
Browser spoofing
While browser automation tools are effective, they consume a lot of resources. If Cloudflare WAF is not configured strictly, you can use browser spoofing technology to send HTTP requests to imitate real browser behavior (such as setting the User-Agent header). However, in more complex scenarios, headers alone may not be enough, and you also need to copy the browser's TLS fingerprint (such as using the curl-impersonate tool).
Ending
In this article, you learned tips and tricks on how to scrape websites protected by Cloudflare. Cloudflare is the most popular CDN service on the market, and it also offers advanced anti-bot solutions.
As this article shows, bypassing Cloudflare's anti-scraping measures is challenging, but not impossible. Everything becomes easier with professional, fast, and reliable scraping solutions, such as:
- Universal Scraping API: Autonomously bypass rate limits, fingerprinting, and other anti-bot restrictions for seamless public web data collection.
- Scraping Browser: A fully hosted browser that allows you to scrape dynamic web data while automating the process of unblocking websites.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


