
How to Scrape Google Lens Product Results?
Specialist in Anti-Bot Strategies
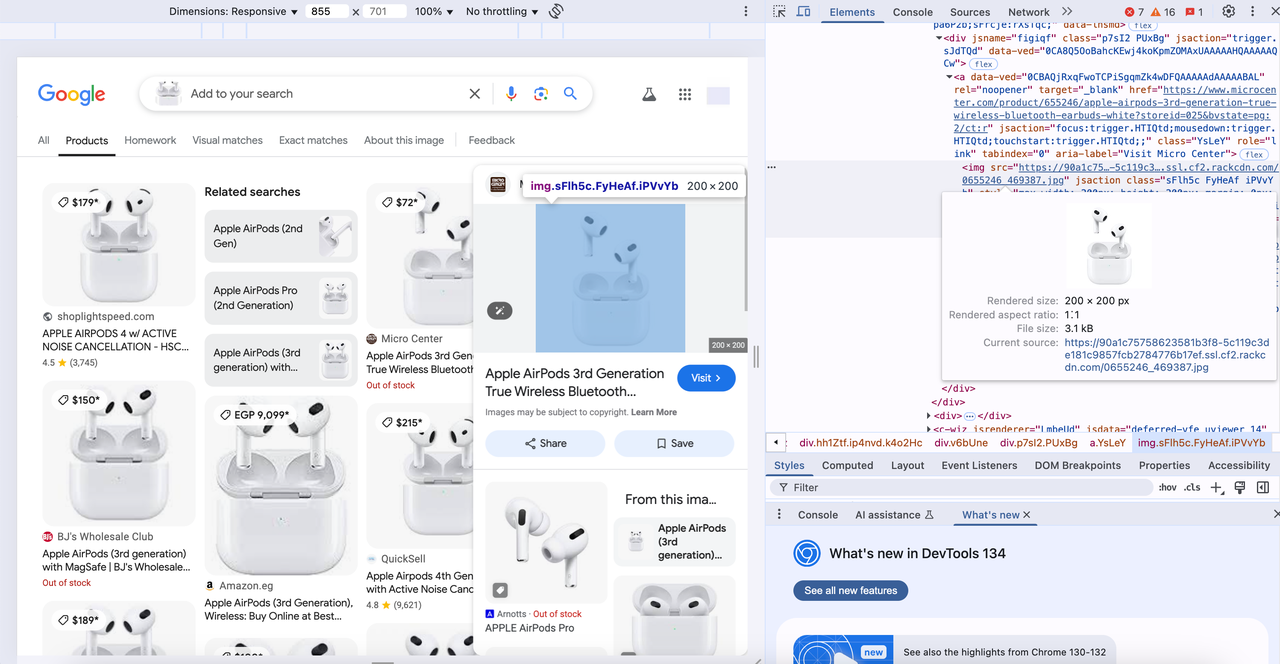
Google Lens is a free tool that allows you to analyze images to extract data like text and identify objects, people, animals, plants, etc. You can also use it to search for similar visual matches to the one provided.
This powerful tool is invaluable for consumers and businesses alike, offering insights into product availability, pricing, and reviews. However, manually extracting data from Google Lens can be time-consuming and inefficient.
This guide will walk you through the process of scraping Google Lens product results using Scrapeless Google Lens API, providing you with the tools and techniques to automate this task effectively.
Keep Scrolling now!
Understanding Google Lens Product Search
Google Lens uses advanced image recognition technology to identify products within images. Once a product is recognized, Google Lens displays a list of relevant results, including product names, prices, retailers, and reviews. This data is crucial for market research, price comparison, and competitor analysis.
However, the dynamic nature of Google Lens and its potential anti-scraping measures make automated data extraction challenging.
Challenges in Scraping Google Lens
- Dynamic Content: Google Lens relies on JavaScript to load data dynamically. Use tools like Selenium or Puppeteer to ensure your scraper waits for all elements to load before extracting information.
- Anti-Scraping Measures: Avoid detection by rotating user agents and using proxies to distribute requests across multiple IPs.
- Rate Limiting: Send requests at a controlled pace to avoid IP bans. Introduce delays between requests to mimic human behavior.
Why Should We Use an API?
There are several reasons why you might want to use an API, especially Scrapeless Google Lens API:
- No need to create a parser from scratch and maintain it.
- Bypass Google's blocking: solving CAPTCHAs or solving IP blocking.
- Paying for proxies and CAPTCHA solvers.
- No need to use browser automation.
The Scrapeless API handles everything on the backend, the response time is very fast, less than ~3.3 seconds per request, and there is no need for browser automation, so it will be much faster.
How to Scrape Google Lens Product Results?
Your first reaction may be to try to use programming to achieve the crawling task. However, due to time and energy constraints🚫. Most smart users have chosen to use cheap and fast APIs to complete complex data extraction. It can be completed with simple configuration:
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
Prerequisites
First, let's establish a connection to the Google Lens API and use the google_lens source. You can follow the instructions provided in our documentation.
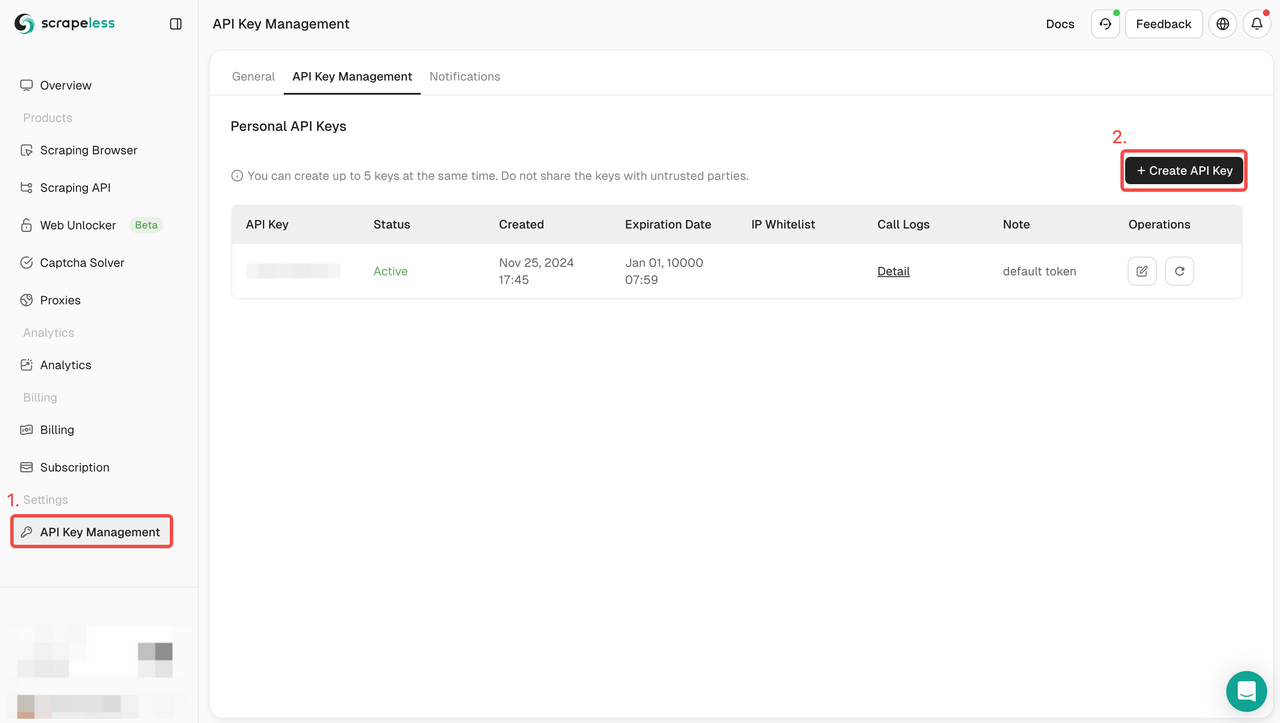
Step 1: Create your Google Lens API Token
To get started, you’ll need to obtain your API Key from the Scrapeless Dashboard:
- Log in to the Scrapeless Dashboard.
- Navigate to API Key Management.
- Click Create to generate your unique API Key.
- Once created, simply click on the API Key to copy it.
Step 2: Write a Python script to integrate the Scrapeless API
Python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
engine: "google_lens",
hl: "en",
country: "us",
search_type: "products"
url: "https://m.media-amazon.com/images/I/61iBtxCUabL._AC_UF894,1000_QL80_.jpg",
}
payload = Payload("scraper.google.lens", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Alternative method: Using Playground
You can also choose to use Scrapeless Playground to complete the data extraction of Google Lens products.
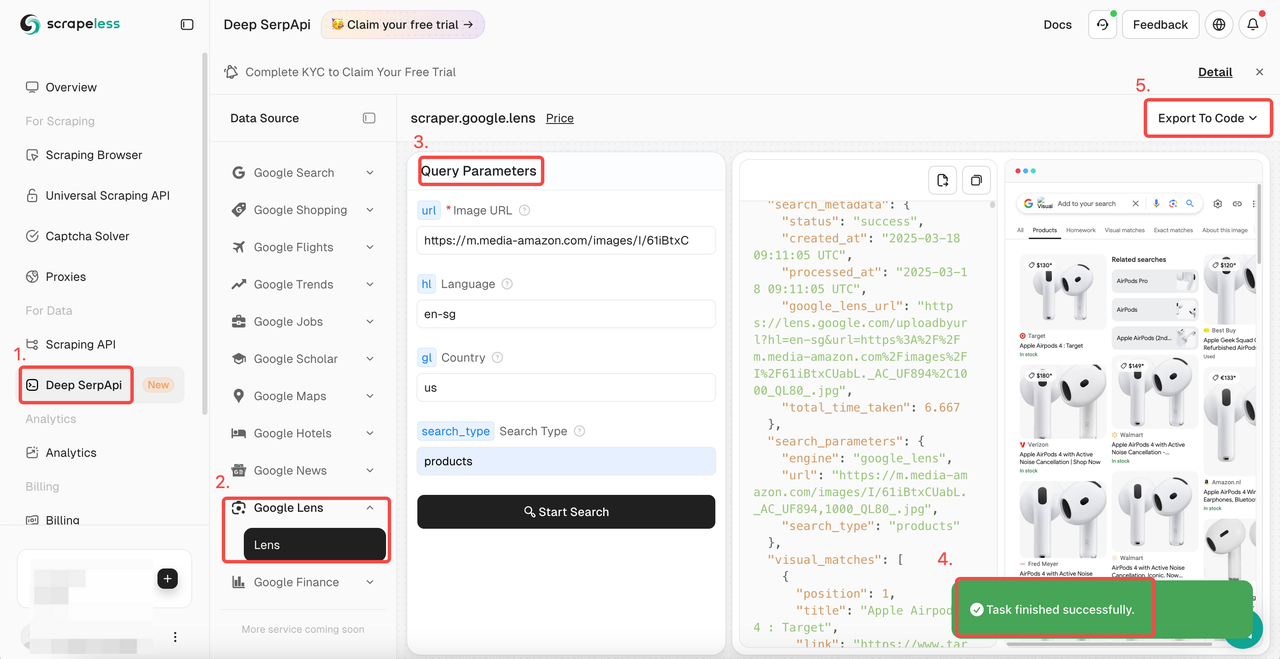
- After creating the API token, click Deep SerpApi
- Find the Google Lens actor
- Add the parameters you need to complete the request configuration.
- Click Start Search and wait for the results to load.
- Export the results
Step 3. Get scraping results
The following are some of the crawling results, which are only for demonstration reference:
JSON
{
"search_metadata": {
"status": "success",
"created_at": "2025-03-18 09:11:05 UTC",
"processed_at": "2025-03-18 09:11:05 UTC",
"google_lens_url": "https://lens.google.com/uploadbyurl?hl=en-sg&url=https%3A%2F%2Fm.media-amazon.com%2Fimages%2FI%2F61iBtxCUabL._AC_UF894%2C1000_QL80_.jpg",
"total_time_taken": 6.667
},
"search_parameters": {
"engine": "google_lens",
"url": "https://m.media-amazon.com/images/I/61iBtxCUabL._AC_UF894,1000_QL80_.jpg",
"search_type": "products"
},
"visual_matches": [
{
"position": 1,
"title": "Apple Airpods 4 : Target",
"link": "https://www.target.com/p/ap2022-true-wireless-bluetooth-headphones/-/A-85978615",
"currency": "USD",
"price": "$130*",
"extracted_price": 130,
"stock_information": "In stock",
"source": "Target",
...Is it legal to scrape data from Google Lens?
Scraping Google Lens data is not illegal, but there are various legal and ethical guidelines that need to be followed. Users must understand Google's Terms of Service, data privacy laws, and intellectual property rights to ensure their activities are compliant. By following best practices and staying informed about legal developments, you can minimize the risk of legal issues associated with web scraping.
Scrapeless Deep SerpAPI: A Powerful Real-Time Search Data Solution
Deep SerpApi is a real-time search data platform designed for AI applications and retrieval augmentation generation (RAG) models, providing real-time, accurate, and structured Google search results data, supporting more than 20 Google SERP types, including Google Search, Google Trends, Google Shopping, Google Flights, Google Hotels, Google Maps, etc.
What are advantages of Deep SerpApi?
- Real-time data update: based on data updates within the past 24 hours, ensuring the timeliness and accuracy of information.
- Multi-language and geo-location support: supports multiple languages and geo-locations, and can customize search results based on the user's location, device type, and language.
- 1-2 seconds response: The average response time is only 1-2 seconds, suitable for high-frequency and large-scale data retrieval.
- Seamless integration: compatible with mainstream programming languages such as Python, Node.js, Golang, etc., and can be easily integrated into existing projects.
- High cost performance: The price is as low as $0.1 per 1,000 queries, which is the most cost-effective SERP solution on the market.
Get you bonus now!
The Sponsored Developer program is in progress! The first 100 users receive 500K queries of free API calls, perfect for testing and scaling projects.
You can integrate Deep SerpApi into your AI tools, applications, or any project you're working on. We support frameworks like Dify (Langchain, Langflow, FlowiseAI, and many others are coming soon!). You can also integrate Scrapeless in other ways that suit your project.
Once your integration is completed, share your work with us through GitHub or social media, and provide proof of integration. In return, we'll provide you with 500K free queries for 1 month to help you maximize the benefits of our products.
Join our community and get details from our Admin: Emily Fann!
The Bottom Lines
This tutorial introduces how to use Scrapeless's Google Lens API to scrape results. Following our steps, you can easily use the Scrapeless API to set up the environment, extract relevant data, and save it to a file for easy access.
In addition, Deep SerpApi Playground saves us a lot of unnecessary complicated steps. You only need to make simple parameter configurations to get accurate data results.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


