
How to Bypass Cloudflare With Puppeteer
Advanced Data Extraction Specialist
In the field of data collection and web crawling, developers often face a thorny problem: how to effectively bypass Cloudflare's protection mechanism. As a widely used website security and performance optimization service in the world, Cloudflare's anti-crawler and firewall functions bring considerable challenges to data crawling. This problem is particularly prominent when using Puppeteer for web crawling. This article will explore in depth how to use Scrapeless Scraping Browser, combined with Puppeteer, to easily break through the limitations of Cloudflare and start an efficient and stable data collection journey.
How Cloudflare detects bots
Cloudflare detects bots using a combination of techniques, including:
- Behavioral Analysis – Monitors mouse movements, keystrokes, scrolling behavior, and interaction patterns to distinguish human users from bots.
- IP Reputation – Uses a global threat intelligence database to identify suspicious IP addresses based on past activity.
- Challenge-Response Tests – Deploys CAPTCHAs or JavaScript challenges to verify if a visitor is human.
- Fingerprinting – Analyzes browser characteristics, HTTP headers, and device attributes to detect automation.
- Rate Limiting – Flags unusual request patterns, such as high-frequency or non-human browsing behaviors.
- Machine Learning – Uses AI models trained on vast amounts of traffic data to identify bot-like behaviors.
- TLS Fingerprinting – Examines how TLS connections are established to differentiate between real browsers and automated scripts.
- JavaScript Execution Monitoring – Checks if JavaScript is properly executed to detect headless browsers and bots that disable scripts.
Why Puppeteer alone can’t bypass Cloudflare
Here's the translation with the core keyword "bypass Cloudflare" inserted:
1. Cloudflare's Complex Detection Mechanisms
Cloudflare uses multiple methods to detect and distinguish between human users and automated tools like Puppeteer, including behavior analysis, IP reputation checks, and HTTP fingerprinting. These mechanisms make it difficult for Puppeteer alone to bypass Cloudflare.
2. Puppeteer's Default Behavior Is Easily Identified
By default, Puppeteer exhibits behaviors that differ from human users, such as:
- Fixed user-agent strings that don't match typical browsers.
- Lack of human-like interactions, such as unnatural mouse movements or click patterns.
- Distinct request headers that reveal it as an automated tool.
3. Cloudflare's Challenge Mechanisms
When Cloudflare detects suspicious traffic, it triggers challenges like CAPTCHAs or verification steps. Puppeteer alone cannot solve these challenges, making it impossible to bypass Cloudflare without additional tools.
4. Need for Extra Configuration and Tools
To bypass Cloudflare, Puppeteer requires additional setups, such as:
- Simulating human behavior with random delays and realistic interactions.
- Using proxy IPs to avoid IP bans.
- Modifying request headers to mimic real browsers.
- Integrating CAPTCHA-solving services like 2Captcha.
5. Continuously Updated Detection Rules
Cloudflare regularly updates its detection algorithms, rendering old bypass methods ineffective over time.
In summary, Puppeteer alone struggles to bypass Cloudflare's detection. It needs to be combined with other techniques and tools to simulate human behavior and handle Cloudflare's challenges effectively.
Method #1: Bypass Cloudflare using puppeteer-extra-plugin-stealth
The puppeteer-extra-plugin-stealthis a patch that helps bypass Cloudflare by masking Puppeteer's automated browser properties, making it appear like an actual browser.
For example, the Stealth plugin overrides the WebDriver property and replaces the HeadlessChrome flag with Chrome to mask automation signals. It also mocks other legitimate browser properties, such as chrome.runtime, which makes it appear headful even in headless mode.
The Puppeteer Stealth plugin uses a similar API as the base Puppeteer, so there's no learning curve for developers already using Puppeteer.
Let's bypass CoinTracker, a website with simple Cloudflare protection, to see how Puppeteer Stealth works.
First, install the plugin:
npm install puppeteer-extra puppeteer-extra-plugin-stealthNow, import the required libraries and add the Stealth plugin. Then, request the protected website and take a screenshot of its homepage:
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://sailboatdata.com/sailboat/11-meter/', {
waitUntil: 'load',
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();The Puppeteer Stealth plugin bypasses Cloudflare and screenshots the website's homepage, as shown:
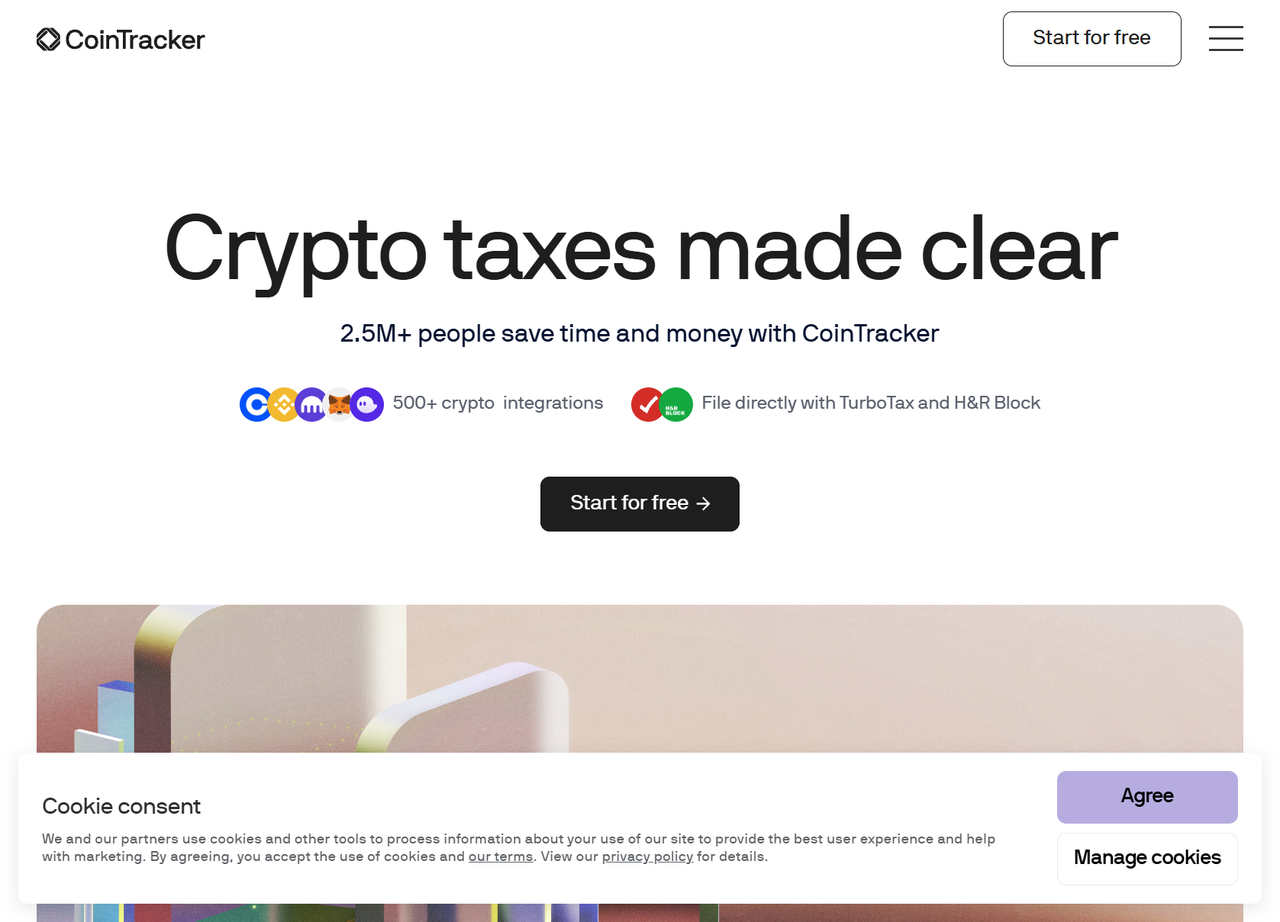
You have successfully evaded Cloudflare’s detection.
Of course, the current target website is easy to access because it does not enforce any sophisticated detection techniques.
Can the Puppeteer Stealth plugin handle more advanced security measures? The answer is...
The Stealth plugin is blocked, as shown in the figure.
Limitations of Puppeteer Stealth plugin
Some websites use more advanced Cloudflare security checks than others. In such cases, masking Puppeteer's automation properties using the Puppeteer-extra-plugin-stealth Cloudflare evasion technique is insufficient to get through.
For example, Puppeteer Stealth got blocked when attempting to access the Cloudflare Challenge page.
Try it out yourself by replacing the previous target URL with the challenge page URL:
// npm install puppeteer-extra puppeteer-extra-plugin-stealth
const puppeteer = require('puppeteer-extra');
const StealthPlugin = require('puppeteer-extra-plugin-stealth');
// add the stealth plugin
puppeteer.use(StealthPlugin());
(async () => {
// set up browser environment
const browser = await puppeteer.launch();
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
// take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();The Stealth plugin got blocked, as shown:
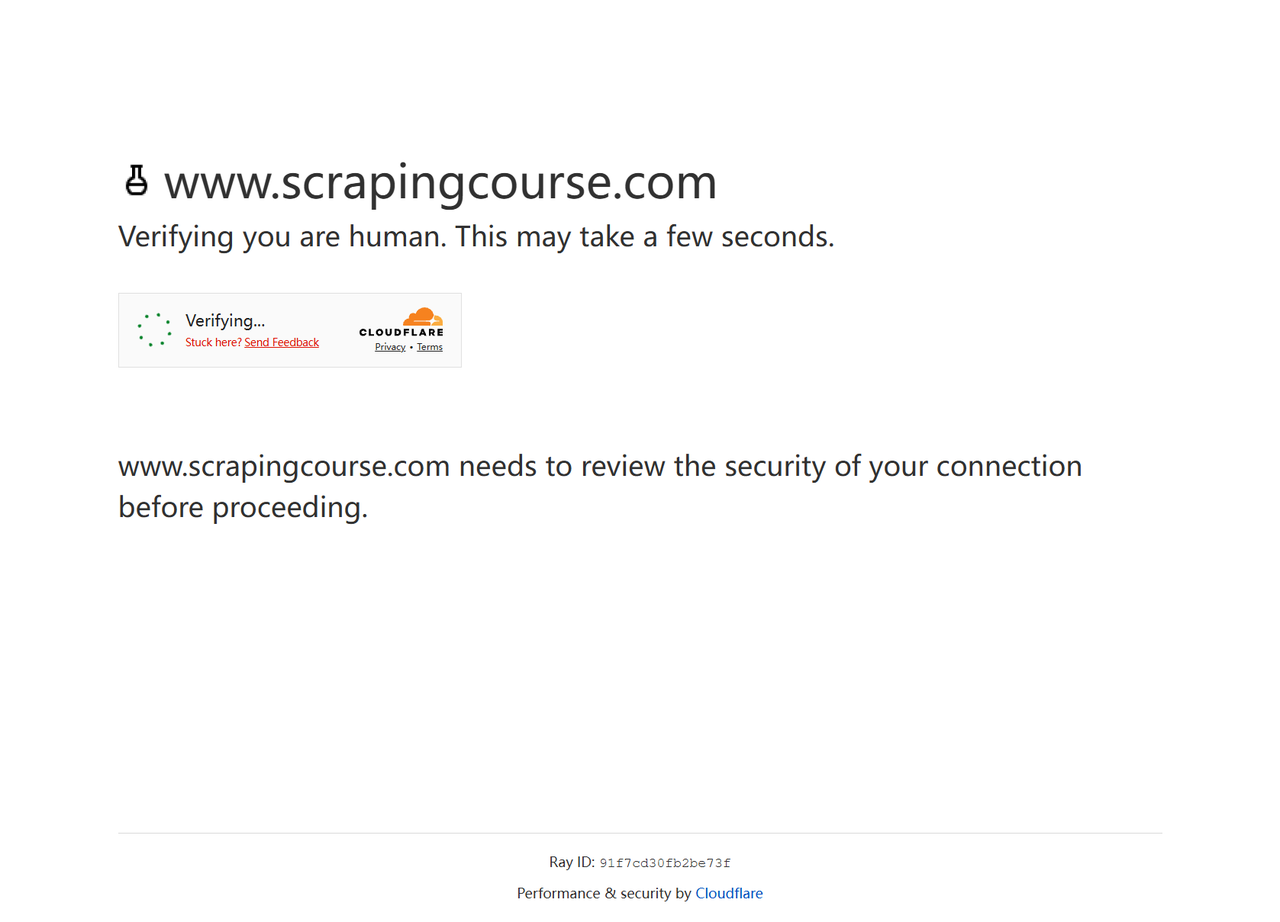
The results indicate that a more advanced Cloudflare anti-bot system detected the Stealth plugin as a bot. The Stealth plugin still has some detectable traits, such as inconsistent WebGL or Canvas rendering, giving it away as a bot.
How can you solve these limitations and extract data from complicated websites? The answer is Scrapeless.
Method 2: Bypass Cloudflare using Scrapeless and Puppeteer
The easiest way to avoid the limitations of Puppeteer and its Stealth plugin is to integrate the library with the Scrapeless Scraping Browser. With the Scrapeless Scraping Browser, your Puppeteer scraper gets fortified with advanced evasions to appear as a human and bypass anti-bot detection.
All you have to do is add a single line of code to your existing Puppeteer script, and the Scraping Browser will help you handle core browser fingerprinting, add missing plugins and extensions, manage residential proxy rotation, and more.
The Scraping Browser also runs in the cloud, preventing the memory overhead of running local browser instances. This feature makes it highly scalable.
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
Key Features of Scrpeless Scraping Browser
Scrpeless Scraping Browser is a tool designed for efficient and large-scale web data extraction:
- Simulate real human interaction behaviors to bypass advanced anti-crawler mechanisms such as browser fingerprinting and TLS fingerprinting detection.
- Support automatic solution of multiple types of verification codes, including cf_challenge to ensure uninterrupted crawling process.
- Seamless integration of popular tools such as Puppeteer and Playwright to simplify the development process and support launching automated tasks with a single line of code.
How to integrate the Scraping Browser with Puppeteer
Scrapeless requires puppeteer-core, a Puppeteer version that doesn't download the Chrome binary. So, ensure you install it:
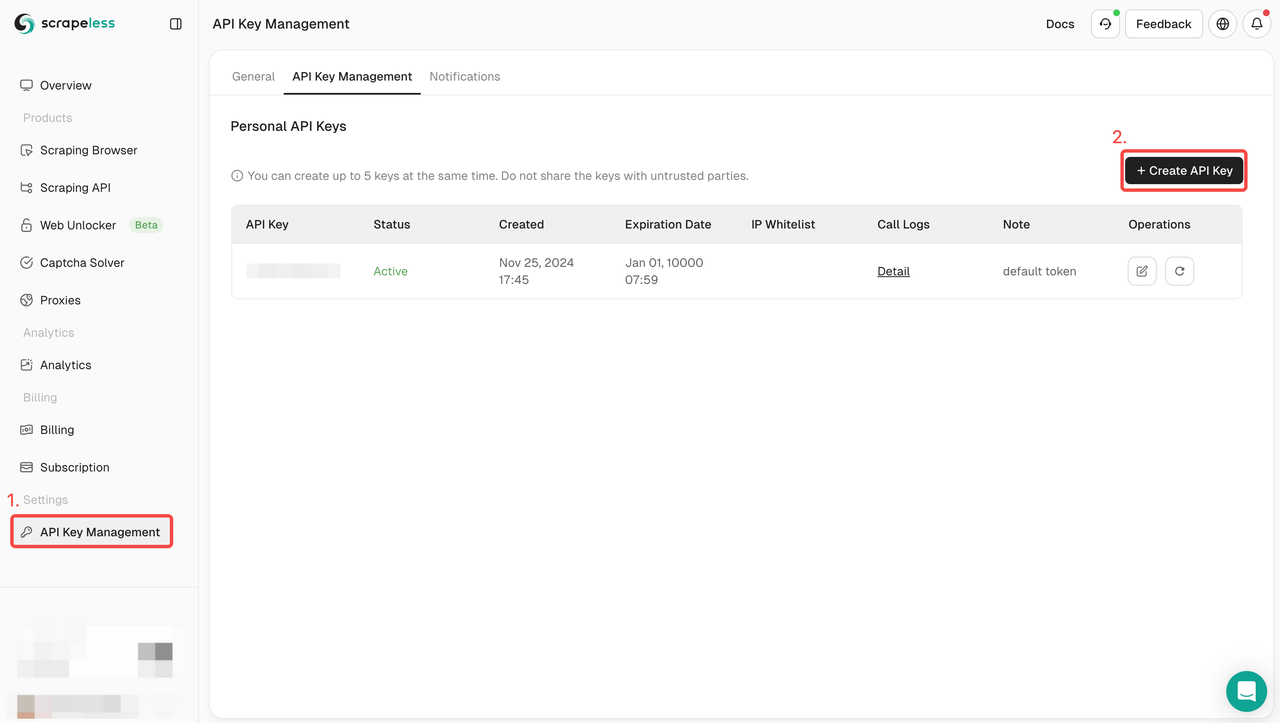
npm install puppeteer-coreStep 1. Sign up for Scrapeless, click API Key Management > Create API Key to create your Scrapeless API Key.
Sign up for Scrapeless and get a free trial. If you have any questions, you can also contact Liam via Discord
Step 2. Then, go to Scraping Browser and copy your Browser URL.
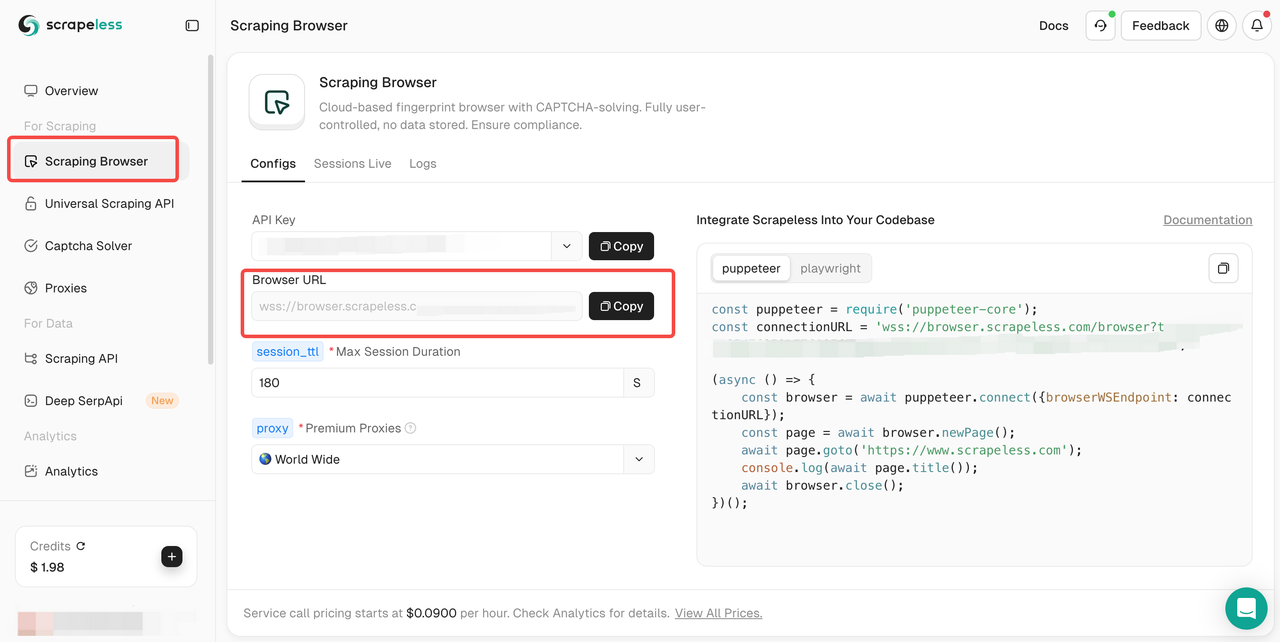
Integrate the copied browser URL into your Puppeteer script like so:
const puppeteer = require('puppeteer-core');
const connectionURL = 'wss://browser.scrapeless.com/browser?token=<YOUR_Scrapeless_API_KEY>&session_ttl=180&proxy_country=ANY';
(async () => {
// set up browser environment
const browser = await puppeteer.connect({
browserWSEndpoint: connectionURL,
});
// create a new page
const page = await browser.newPage();
// navigate to a URL
await page.goto('https://www.scrapingcourse.com/cloudflare-challenge', {
waitUntil: 'networkidle0',
});
// wait for the challenge to resolve
await new Promise(function (resolve) {
setTimeout(resolve, 10000);
});
//take page screenshot
await page.screenshot({ path: 'screenshot.png' });
// close the browser instance
await browser.close();
})();You need to replace https://www.scrapingcourse.com/cloudflare-challenge with any website with cloudflare-challenge;
Also replace your Scrapeless API Key in the token part.
The above code accesses and screenshots the protected page. See the result below:
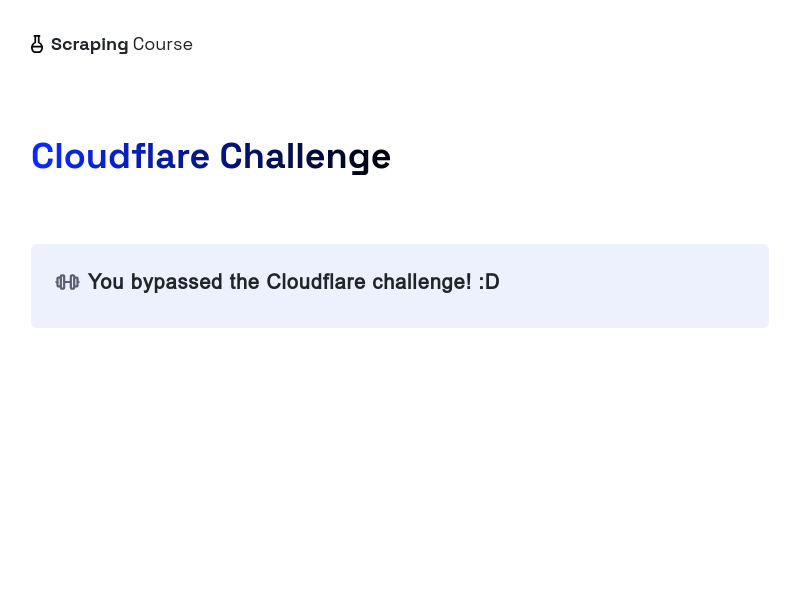
Congratulations 🎉! You've successfully bypassed Cloudflare using Puppeteer and Scrapeless.
Benefits of Integrating Scrapeless Scraping Browser into Puppeteer to Bypass Cloudflare
Integrating Scrapeless Scraping Browser into Puppeteer to bypass Cloudflare has the following benefits:
- Boost Anti - Detection
Puppeteer alone has clear automation features (e.g., navigator.webdriver attribute, HeadlessChrome user - agent flag), making it easy for Cloudflare to identify as a bot. Scrapeless Scraping Browser can mimic real - browser fingerprints (type, user - agent, screen resolution, etc.), effectively hiding Puppeteer's automation features, reducing the risk of Cloudflare detection, and increasing scraping success rates.
- Simplify Configuration and Integration
Scrapeless Scraping Browser offers easy - to - use APIs and integration methods. Developers can add a small amount of code to existing Puppeteer scripts to leverage its powerful anti - detection features, without needing to understand Puppeteer's internals or Cloudflare's anti - crawling mechanisms. This lowers development barriers and workloads.
- Enhance Code Maintainability
Using Scrapeless Scraping Browser reduces reliance on Puppeteer's underlying configurations and custom scripts. This makes the code cleaner and clearer, facilitating future maintenance and upgrades.
Additional Resources
How to Bypass Cloudflare Challenge Full Guide
What Is TCP/IP Fingerprinting?
How to Scrape Google News with Python
Scrapeless API official documentation
Conclusion
In summary, bypassing Cloudflare with Puppeteer requires effective tools and methods. Scrapeless Scraping Browser offers a simple yet powerful solution by enhancing anti-detection, simplifying integration, and improving maintainability. Always ensure legal compliance when scraping.
Improve your business efficiency and choose Scrapeless Scraping Browser's enterprise-level customized solutions. We provide professional and efficient data collection services.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


