
How to Scrape Google Play Store App in Python
Advanced Data Extraction Specialist
The Google Play Store contains a vast amount of app data, including app names, developer information, ratings, download counts, and user reviews. This data is crucial for market analysis, competitor research, app store optimization (ASO), and automated data monitoring. For example, developers can scrape Google Play Store data to analyze competitors' update frequency, trending keywords, and user feedback to optimize their product strategies.
Additionally, market researchers can track the growth trends of specific app categories by collecting and analyzing Play Store data.
However, scraping Google Play Store is not straightforward due to several challenges:
- Dynamic content loading: Most app information is rendered using JavaScript, making it impossible to extract complete data with traditional requests + BeautifulSoup methods.
- Anti-scraping mechanisms: Google detects unusual access patterns and blocks scrapers using CAPTCHAs, IP restrictions, and other countermeasures.
- Complex HTML structure: The structure of Google Play Store pages frequently changes, requiring scrapers to be continuously updated.
In this article, we will explore several common Python-based scraping methods, including Requests + BeautifulSoup, while analyzing their pros and cons. Finally, we will introduce a more efficient and reliable solution— Scrapeless—that allows you to extract Google Play Store data effortlessly without writing complex scraping scripts.
Understanding Google Play Store Scraping Challenges
Scraping Google Play Store can be challenging due to several built-in protections that prevent automated data extraction. Before diving into how to scrape Google Play Store, it's essential to understand the key obstacles that scrapers face.
1. Dynamic Content Loading
Many sections of the Google Play Store, including app descriptions, reviews, and ratings, are loaded dynamically using JavaScript. This means that a simple requests + BeautifulSoup approach won’t work because the raw HTML response does not contain the full app details. Instead, a Google Play scraper needs to render JavaScript to extract complete data, which often requires tools like Selenium or Puppeteer.
2. Anti-Scraping Mechanisms
Google Play Store has implemented several anti-scraping mechanisms to detect and block automated requests. Some of these include:
- CAPTCHAs: After too many requests from a single IP, Google Play Store prompts for CAPTCHA verification, making it difficult for scrapers to continue.
- IP Rate Limiting: Google tracks unusual traffic patterns and may temporarily or permanently block an IP address that sends too many requests.
- User-Agent Detection: Sending requests without proper headers (like a browser User-Agent) can quickly lead to blocks.
A Google Play Store scraper must use rotating proxies, CAPTCHA-solving techniques, and realistic browser headers to bypass these restrictions.
3. Constant HTML Structure Changes
Google frequently updates the layout and structure of its Play Store pages. This means that a Google Play scraper built today might break in a few months unless regularly updated. This is a common challenge for developers who rely on web scraping for data extraction.
4. API Limitations
Google does not provide a free official API for scraping Google Play Store data. While some third-party APIs exist, they often have rate limits, require subscriptions, or lack flexibility in data extraction.
Method 1: Scraping Google Play Store Using Requests & BeautifulSoup
One of the simplest ways to scrape Google Play Store is by using Python’s requests library to fetch the HTML and BeautifulSoup to parse the page. This method is straightforward but has several limitations, which we’ll discuss below.
Note: We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
How to Scrape Google Play Store Using Requests & BeautifulSoup
Here’s a simple example of how to extract app details from the Google Play Store using requests and BeautifulSoup:
import requests
from bs4 import BeautifulSoup
# Define the URL of the app page
app_url = "https://play.google.com/store/apps/details?id=com.whatsapp"
# Set headers to mimic a real browser request
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
# Send the request
response = requests.get(app_url, headers=headers)
# Check if the request was successful
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Extract app name
app_name = soup.find("h1", class_="Fd93Bb F5UCq").text if soup.find("h1", class_="Fd93Bb F5UCq") else "Not Found"
# Extract app description
app_description = soup.find("div", class_="bARER").text if soup.find("div", class_="bARER") else "Not Found"
print(f"App Name: {app_name}")
print(f"Description: {app_description}")
else:
print(f"Failed to fetch the page, status code: {response.status_code}")Some of the crawling results are shown below:
Description: WhatsApp from Meta is a FREE messaging and video calling app. It’s used by over 2B people in more than 180 countries. It’s simple, reliable, and private, so you can easily keep in touch with your friends and family. WhatsApp works across mobile and desktop even on slow connections, with no subscription fees*.Private messaging across the worldYour personal messages and calls to friends and family are end-to-end encrypted. No one outside of your chats, not even WhatsApp, can read or listen to them.Simple and secure connections, right awayAll you need is your phone number, no user names or logins. You can quickly view your contacts who are on WhatsApp and start messaging.High quality voice and video callsMake secure video and voice calls with up to 8 people for free*. Your calls work across mobile devices using your phone’s Internet service, even on slow connections.Group chats to keep you
.....Limitations of Using Requests & BeautifulSoup to Scrape Google Play Store
While requests and BeautifulSoup provide a simple way to scrape Google Play Store, this approach has several drawbacks:
❌ Unable to Handle Dynamic Content
- Google Play Store loads many elements, such as reviews and ratings, dynamically via JavaScript. Since requests only fetches the raw HTML, dynamically loaded data will be missing.
- Many app details (like developer information and user reviews) require JavaScript execution, which requests cannot handle.
❌ Easily Blocked by Google
- Google Play has strict anti-scraping mechanisms that detect unusual traffic patterns. If you make multiple requests from the same IP, Google may block access or present a CAPTCHA.
- Using static headers can help temporarily, but eventually, your scraper will be flagged.
❌ Limited Use Cases
- Since this method cannot render JavaScript, it is only useful for scraping static content.
- If you need detailed information such as user reviews, update history, or app screenshots, this approach won’t work.
When to Use Requests & BeautifulSoup for Scraping Google Play Store?
Despite its limitations, this method is still useful for small-scale scraping tasks where JavaScript execution is not required, such as:
✅ Extracting app names and basic descriptions
✅ Fetching app package IDs for quick lookups
✅ Scraping categories, rankings, or static metadata
Method 2: Scraping Google Play Store Using Scrapeless (Better Performance for B2B Needs)
For businesses that rely on Google Play Store scraper solutions for market intelligence, ad tracking, or competitor research, traditional web scraping methods like Selenium or Scrapy can be slow, unreliable, and require high maintenance. Scrapeless, on the other hand, offers a scalable, API-based solution to scrape Google Play Store efficiently without the need for infrastructure management or dealing with Google’s anti-scraping protections.
Why Is Scrapeless the Best Choice for B2B Google Play Scraping?
🚀 Eliminate Scraping Challenges – Scrapeless provides a fully managed Google Play scraper, bypassing Google’s anti-scraping mechanisms without requiring proxies or browser automation.
💰 Lower Operational Costs – Maintaining your own Google Play Store scraper requires constant updates, proxy rotation, and CAPTCHAs handling. Scrapeless eliminates these costs, with API pricing as low as $0.1 per 1K requests, making it a cost-effective choice for B2B data needs.
📊 Actionable, Structured Data – The API provides cleaned, structured JSON data, making it easy for businesses to monitor app trends, track competitors, or fuel machine-learning models without the hassle of data parsing and cleaning.
How to Use Scrapeless as a Google Play Store Scraper (Python API Example)
For B2B companies that need Google Play scraping at scale, here’s how to fetch app data using Scrapeless in Python:
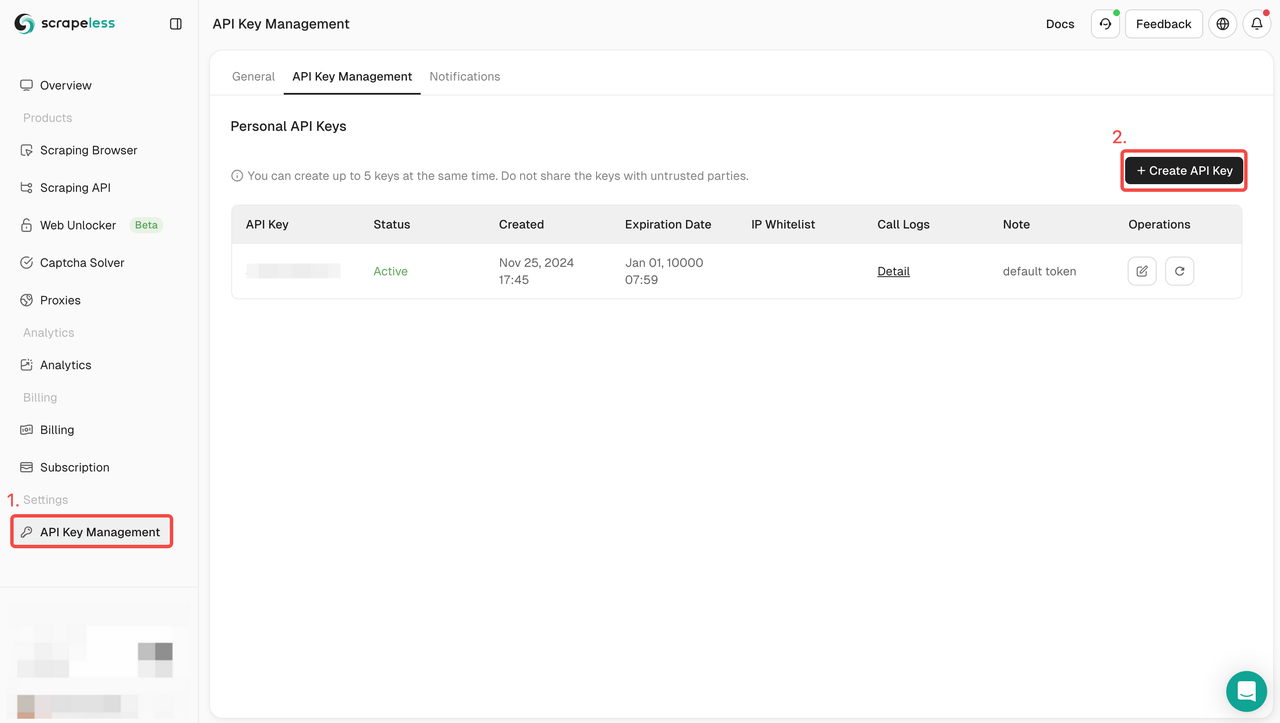
Step 1: Create your Google Play Store API Token
To get started, you’ll need to obtain your API Key from the Scrapeless Dashboard:
- Log in to the Scrapeless Dashboard.
- Navigate to API Key Management.
- Click Create to generate your unique API Key.
- Once created, simply click on the API Key to copy it.
Scrapeless is priced at just $0.1 per 1,000 requests, with a free trial available to let you experience efficient Google Play Store data scraping services.
Step 2: Write a Python script to integrate the Scrapeless API
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"apps_category": "BEAUTY",
}
payload = Payload("scraper.google.play", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()For more advanced parameter information, you can check out Scrapeless's official API documentation
Also replace "your_token" with your Scrapeless API Key
Key Business Use Cases for Scrapeless as a Google Play Store Scraper
-
Competitor Intelligence – Monitor competing apps’ updates, pricing changes, and customer sentiment analysis.
-
Market Research & Trend Analysis – Extract historical and real-time app data for deeper industry insights.
-
Ad Intelligence & ASO Optimization – Track keyword trends, app rankings, and developer activity for more effective marketing - strategies.
-
Data Integration with Enterprise Systems – Easily connect Scrapeless API with internal analytics, CRM, or automation platforms.
Why Choose Scrapeless Over Traditional Google Play Scraping Methods?
| Method | Speed | Bypasses Anti-Scraping | Handles JavaScript | Maintenance Required | Best For |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | ⚡⚡ | ❌ No | ❌ No | ✅ Yes | Small-scale scraping |
| Selenium | ⚡ | ❌ No | ✅ Yes | ✅ Yes | JavaScript-heavy pages |
| Scrapeless | ⚡⚡⚡⚡ | ✅ Yes | ✅ Yes | ❌ No | Large-scale B2B data extraction |
Unlike traditional Google Play Store scraper setups, Scrapeless provides a fully managed, scalable solution, making it the best choice for businesses that need reliable, structured, and cost-effective data extraction.
Try Scrapeless for free and experience how our API can simplify your Google Play Store scraping process. Start your free trial here.
Join our Discord community to get support, share insights, and stay updated on the latest features. Click here to join!
FAQs about scraping Google Play Store
Q1: How to handle Google Play Store anti-scraping mechanisms?
Google Play Store has strict anti-scraping measures, such as CAPTCHA and IP blocking. Using rotating proxies, headless browsers, or a specialized Google Play scraper like Scrapeless can help bypass these restrictions.
Q2: Can I use Scrapy or Selenium for large-scale scraping?
While Scrapy and Selenium can scrape Google Play Store, they are not ideal for large-scale scraping due to high IP blocking risks and slow performance. A cloud-based Google Play Store scraper like Scrapeless offers better efficiency.
Q3: What is the best tool to scrape Google Play Store?
The best choice depends on your needs. If you want a scalable, hassle-free solution, Scrapeless is a powerful Google Play scraper with fast, reliable data extraction.
Conclusion
In this article, we've explored several methods to scrape Google Play Store, each with its own pros and cons. Using Requests + BS4 is a good option for simple, small-scale scraping, but it has limitations when dealing with dynamic content. Scrapeless provides the best performance for large-scale, enterprise-level data collection. It eliminates the need for maintaining complex scrapers, is faster than traditional methods, and offers a cost-effective pricing model.
For businesses looking to save time and development costs while obtaining high-quality data, Scrapeless is the optimal solution. We encourage you to try Scrapeless for free and experience how its API can streamline your Google Play Store scraping process. Click here to get started with your free trial!
More Resources
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


