
How to Scrape Google Product Online Sellers with Python
Advanced Data Extraction Specialist
Introduction
In today’s competitive eCommerce landscape, monitoring product listings and analyzing online sellers' performance on platforms like Google can provide valuable insights. Scraping Google Product listings allows businesses to gather real-time data to compare prices, track trends, and analyze competitors. In this article, we’ll show you how to scrape Google product online sellers with Python, using a variety of methods. We will also explain why Scrapeless is the best choice for businesses seeking reliable, scalable, and legal solutions.
Understanding the Challenges of Scraping Google Product Online Sellers
When attempting to scrape Google Product Online Sellers, several key challenges can arise:
- Anti-scraping Measures: Websites implement CAPTCHAs and IP blocking to prevent automated scraping, making data extraction difficult.
- Dynamic Content: Google Product pages often load data using JavaScript, which can be missed by traditional scraping methods like Requests & BeautifulSoup or Selenium.
- Rate-limiting: Excessive requests in a short period can lead to throttled access, causing delays and interruptions in the scraping process.
Privacy Notice: We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
Method 1: Scraping Google Product Online Sellers with Scrapeless API (Recommended Solution)
Why Scrapeless is a Great Tool:
- Efficient Data Extraction: Scrapeless can bypass CAPTCHAs and anti-bot measures, enabling smooth, uninterrupted data scraping.
- Affordable Pricing: At just $0.1 per 1,000 queries, Scrapeless offers one of the most affordable solutions for Google scraping.
- Multi-Source Scraping: In addition to scraping Google product online sellers, Scrapeless allows you to collect data from Google Maps, Google Hotels, Google Flights, Google News and more.
- Speed and Scalability: Handle large-scale scraping tasks quickly, without slowing down, making it ideal for both small and enterprise-level projects.
- Structured Data: The tool provides structured, clean data, ready for use in your analysis, reports, or integration into your systems.
- Ease of Use: No complex setup—simply integrate your API key and start scraping data in minutes.
How to Use Scrapeless API:
- Sign Up: Register on Scrapeless and obtain your API key. At the same time, you can also get a free trial at the top of the Dashboard.
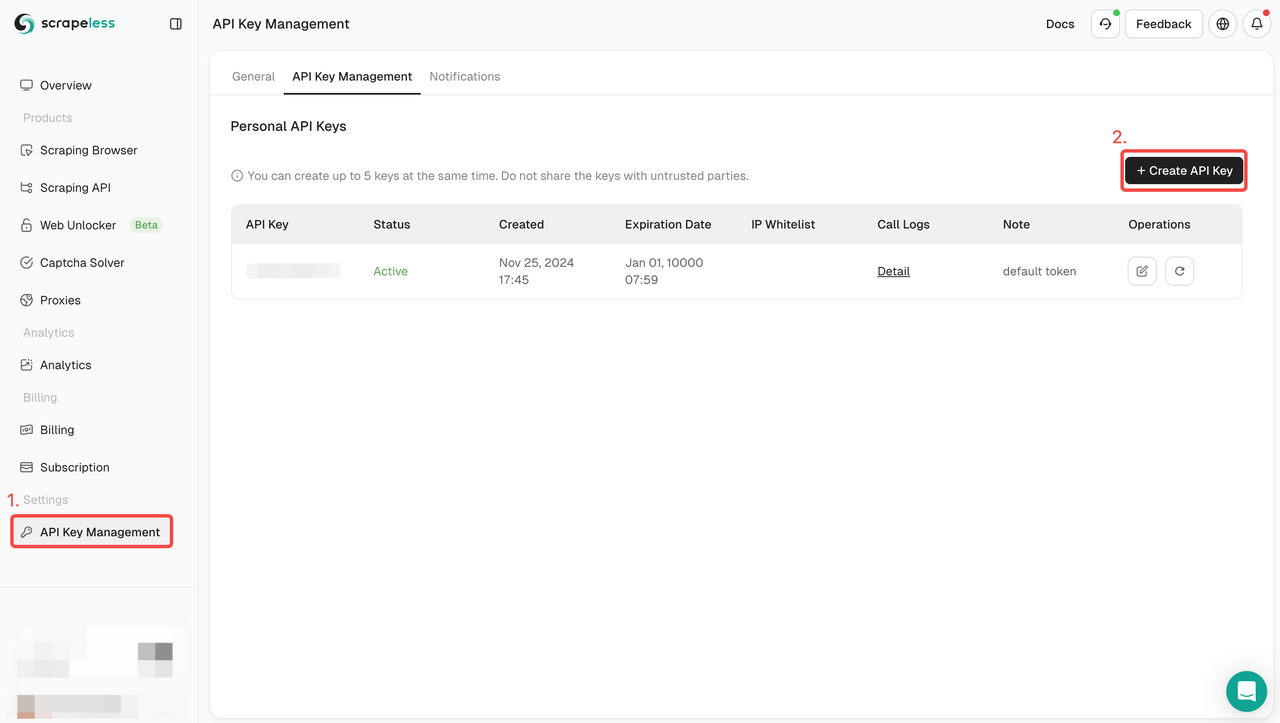
- Integrate API: Include the API key in your code to initiate requests to the service.
- Start Scraping: You can now send GET requests with product URLs or search queries, and Scrapeless will return structured data including product names, prices, reviews, and more.
- Use the Data: Leverage the retrieved data for competitor analysis, trend tracking, or any other project requiring Google data insights.
Complete Code Example:
python
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_product",
"product_id": "4172129135583325756",
"gl": "us",
"hl": "en",
}
payload = Payload("scraper.google.product", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Try Scrapeless for free and experience how our API can simplify your Google Product Online Seller scraping process. Start your free trial here.
Join our Discord community to get support, share insights, and stay updated on the latest features. Click here to join!
Method 2: Scraping Google Product Listings with Requests & BeautifulSoup
In this approach, we will take a deep dive into how to scrape Google product listings using two powerful Python libraries: Requests and BeautifulSoup. These libraries allow us to make HTTP requests to Google product pages and parse the HTML structure to extract valuable information.
Step 1. Setting up the environment
First, make sure you have Python installed on your system. And create a new directory to store the code for this project. Next you need to install beautifulsoup4 and requests. You can do this through PIP:
language
$ pip install requests beautifulsoup4Step 2. Use requests to make a simple request
Now, we need to crawl the data of Google products. Let's take the product with product_id 4172129135583325756 as an example and crawl some data of OnlineSeller.
Let's first simply use requests to send a GET request:
def google_product():
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get('https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8', headers=headers)As expected, the request returns a complete HTML page. Now we need to extract some data from the following page:
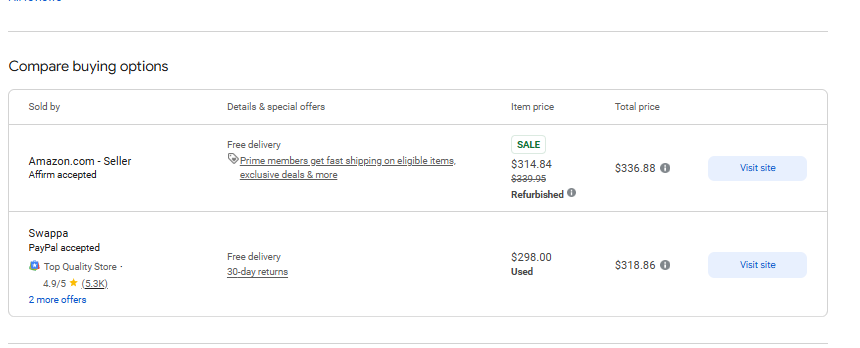
Step 3. Get specific data
As shown in the figure, the data we need is under tr[jscontroller='d5bMlb']:
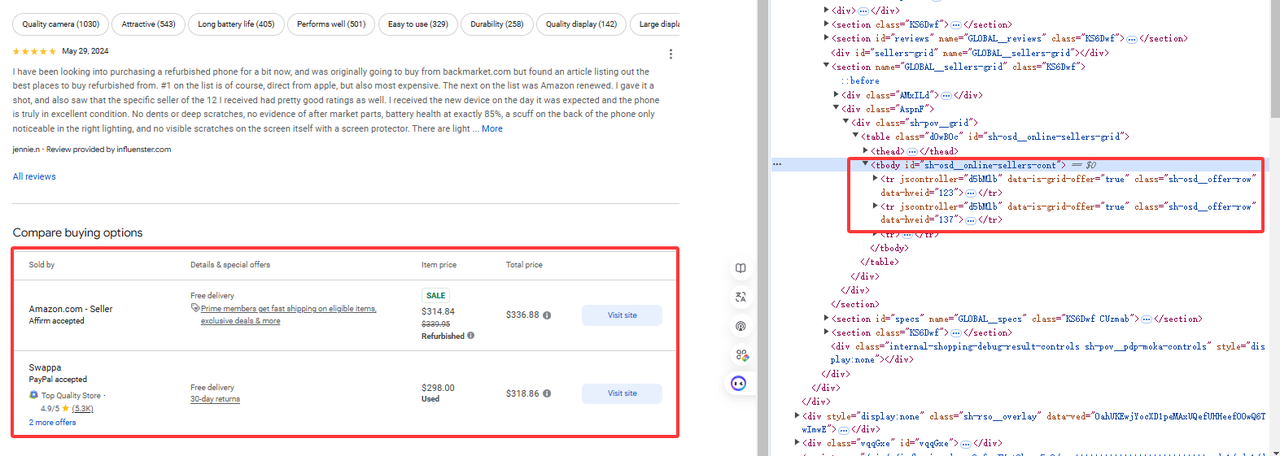
online_sellers = []
soup = BeautifulSoup(response.content, 'html.parser')
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})Then use BeautifulSoup to parse the HTML page and get the relevant elements:
Complete code
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price,
additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/jpeg,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Language": "en-US,en;q=0.9",
"Cache-Control": "no-cache",
"Pragma": "no-cache",
"Priority": "u=0, i",
"Sec-Ch-Ua": '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": '"Windows"',
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "none",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36",
}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
online_sellers = []
for i, row in enumerate(soup.find_all("tr", {"jscontroller": "d5bMlb"})):
name = row.find("a").get_text(strip=True)
payment_methods = row.find_all("div")[1].get_text(strip=True)
link = row.find("a")['href']
details_and_offers_text = row.find_all("td")[1].get_text(strip=True)
base_price = row.find("span", class_="g9WBQb fObmGc").get_text(strip=True)
badge = row.find("span", class_="XhDkmd").get_text(strip=True) if row.find("span", class_="XhDkmd") else ""
link = f"https://www.google.com/{link}"
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_sellers.append({
'name' : name,
'payment_methods' : payment_methods,
'link' : link,
'direct_link' : direct_link,
'details_and_offers' : [{"text": details_and_offers_text}],
'base_price' : base_price,
'badge' : badge
})
return online_sellers
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)The console print results are as follows:

limitation
Of course, we can get the data back using the example above of getting partial data, but there is a risk of IP blocking. We cannot make large requests, which will trigger Google's product risk control.
Method 3: Scraping Google Product Online Sellers with Selenium
In this method, we will explore how to use Selenium, a powerful web automation tool, to scrape Google product listings from online sellers. Unlike Requests and BeautifulSoup, Selenium allows us to interact with dynamic pages that require JavaScript to execute, which makes it perfect for scraping Google product listings that load content dynamically.
Step 1: Set up the environment
First, make sure you have Python installed on your system. And create a new directory to store the code for this project. Next, you need to install selenium and webdriver_manager. You can do this through PIP:
pip install selenium
pip install webdriver_managerStep 2: Initialize the selenium environment
Now, we need to add some configuration items of selenium and initialize the environment.
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)Step 3: Get specific data
We use selenium to get the product with product_id 4172129135583325756 and grab some data of OnlineSeller
driver.get(url)
time.sleep(5) #wait page
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""Complete code
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
import time
from urllib.parse import urlparse, parse_qs
class AdditionalPrice:
def __init__(self, shipping, tax):
self.shipping = shipping
self.tax = tax
class OnlineSeller:
def __init__(self, position, name, payment_methods, link, direct_link, details_and_offers, base_price, additional_price, badge, total_price):
self.position = position
self.name = name
self.payment_methods = payment_methods
self.link = link
self.direct_link = direct_link
self.details_and_offers = details_and_offers
self.base_price = base_price
self.additional_price = additional_price
self.badge = badge
self.total_price = total_price
def sellers_results(url):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--no-sandbox")
options.add_argument("--disable-dev-shm-usage")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
try:
driver.get(url)
time.sleep(5)
online_sellers = []
rows = driver.find_elements(By.CSS_SELECTOR, "tr[jscontroller='d5bMlb']")
for i, row in enumerate(rows):
name = row.find_element(By.TAG_NAME, "a").text.strip()
payment_methods = row.find_elements(By.TAG_NAME, "div")[1].text.strip()
link = row.find_element(By.TAG_NAME, "a").get_attribute('href')
details_and_offers_text = row.find_elements(By.TAG_NAME, "td")[1].text.strip()
base_price = row.find_element(By.CSS_SELECTOR, "span.g9WBQb.fObmGc").text.strip()
badge = row.find_element(By.CSS_SELECTOR, "span.XhDkmd").text.strip() if row.find_elements(By.CSS_SELECTOR, "span.XhDkmd") else ""
parse = urlparse(link)
direct_link = parse_qs(parse.query).get("q", [""])[0]
online_seller = {
'name': name,
'payment_methods': payment_methods,
'link': link,
'direct_link': direct_link,
'details_and_offers': [{"text": details_and_offers_text}],
'base_price': base_price,
'badge': badge
}
online_sellers.append(online_seller)
return online_sellers
finally:
driver.quit()
url = 'https://www.google.com/shopping/product/4172129135583325756?gl=us&hl=en&prds=pid:4172129135583325756,freeship:1&sourceid=chrome&ie=UTF-8'
sellers = sellers_results(url)
for seller in sellers:
print(seller)The console print results are as follows:

Limitations
Selenium is a powerful tool for automating web browser operations and is widely used in automated testing and web data crawling. However, it needs to wait for the page to load, so it is relatively slow in the data crawling process.
FAQ
What are the best methods for scraping Google product listings at scale?
The most effective method for large-scale Google product scraping is using Scrapeless. It provides a fast and scalable API, handling dynamic content, IP blocking, and CAPTCHAs efficiently, making it ideal for businesses.
How do I bypass Google’s anti-scraping measures when scraping product listings?
Google employs several anti-scraping measures, including CAPTCHAs and IP blocking. Scrapeless provides an API that bypasses these measures and ensures smooth, uninterrupted data extraction.
Can I use Python libraries like BeautifulSoup or Selenium to scrape Google Product listings?
While BeautifulSoup and Selenium can be used for scraping Google Product listings, they come with limitations such as slow performance, detection risk, and the inability to scale. Scrapeless offers a more efficient solution that handles all these issues.
Conclusion
In this article, we've discussed three methods for scraping Google Product Online Sellers: Requests & BeautifulSoup, Selenium, and Scrapeless. Each method offers distinct advantages, but when it comes to handling large-scale scraping, Scrapeless is undoubtedly the best choice for businesses.
- Requests & BeautifulSoup are suitable for small-scale scraping tasks but face limitations when dealing with dynamic content or when scaling up. These tools also run the risk of being blocked by anti-scraping measures.
- Selenium is effective for JavaScript-rendered pages, but it’s resource-intensive and slower than other options, making it less ideal for large-scale scraping of Google Product listings.
On the other hand, Scrapeless addresses all the challenges associated with traditional scraping methods. It's fast, reliable, and legal, ensuring that you can efficiently scrape Google Product Online Sellers at scale without worrying about being blocked or running into other obstacles.
For businesses seeking a streamlined, scalable solution, Scrapeless is the go-to tool. It bypasses all the hurdles of conventional methods and provides a smooth, hassle-free experience for collecting Google Product data.
Try Scrapeless today with a free trial and discover how easy it is to scale your Google Product scraping tasks. Start your free trial now.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


