How to Get Lazada Product List through Scrapeless?
Emily Chen
Advanced Data Extraction Specialist
26-Mar-2025
In e-commerce data analysis, market research, or competitive product analysis, obtaining Lazada product data is a key step. Lazada officially provides an API for developers to access product information, but due to strict access rights, rate limits, and other factors, using the official API may not always be the best solution. Therefore, many developers choose Lazada Scraper as an alternative, using Lazada Data Scraping technology to bypass these restrictions and efficiently extract the required data.
This guide will introduce how to obtain Lazada product lists through Scrapeless Lazada API, and compare the pros and cons of the official API and Scrapeless to help you choose the best Lazada Data Scraper solution. In addition, we will also explore how to bypass Lazada anti-crawling mechanism and how to efficiently extract Lazada e-commerce datasets.
Part 1. Introduction to Lazada API
Lazada provides official APIs for developers to access data such as products, orders, and inventory. However, these APIs have the following limitations:
Access rights are required: merchants or developers need to register and obtain authorization before using them.
API rate limit: The official API has a limit on the request frequency, which affects the efficiency of data scraping.
Limited data scope: Some key information may not be directly available, such as competitor product data.
Complex authentication: The OAuth authentication process is cumbersome, which increases the difficulty of development.
These limitations have prompted many developers to seek third-party Lazada scraper solutions to obtain more flexible and efficient data scraping capabilities.
Part 2. How to Get Lazada Product List through Scrapeless [Python Guide]
Scrapeless provides a more convenient way to scrape Lazada data. Through API calls, you can bypass the official API restrictions and get product information directly.
2.1 Advantages of Scrapeless API
Supports all Lazada sites (Malaysia, Singapore, Indonesia, etc.).
Bypass the official API restrictions and not be restricted by request frequency.
2.2 Here are the steps to scrape Lazada product list using Scrapeless API
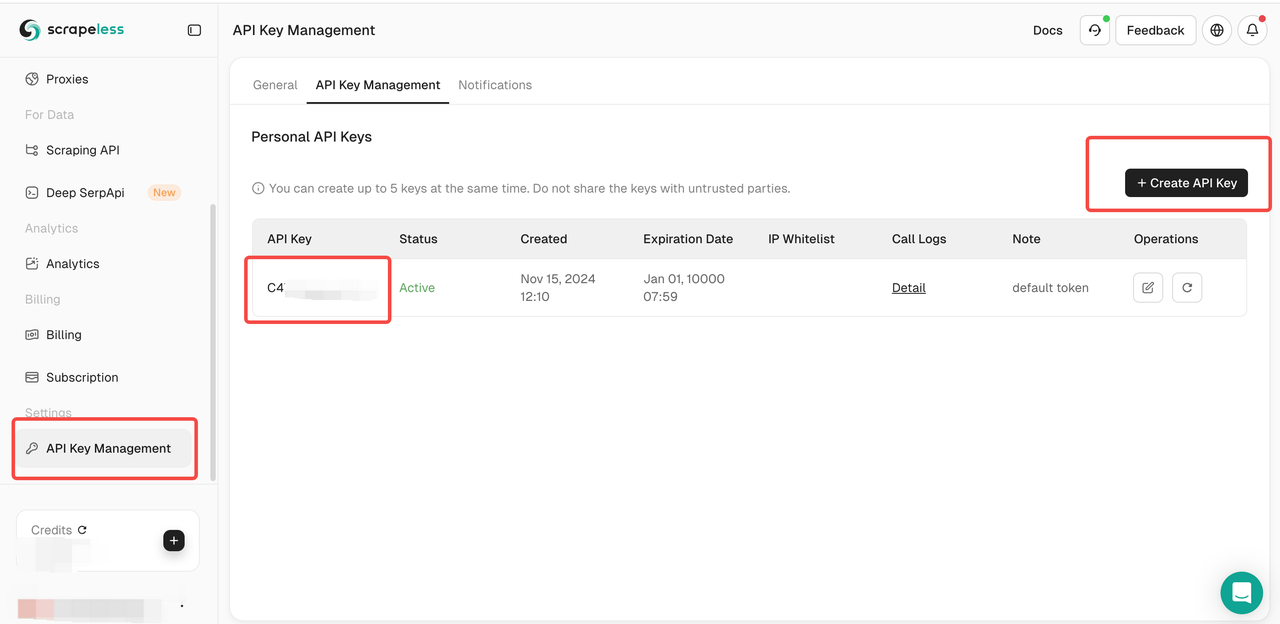
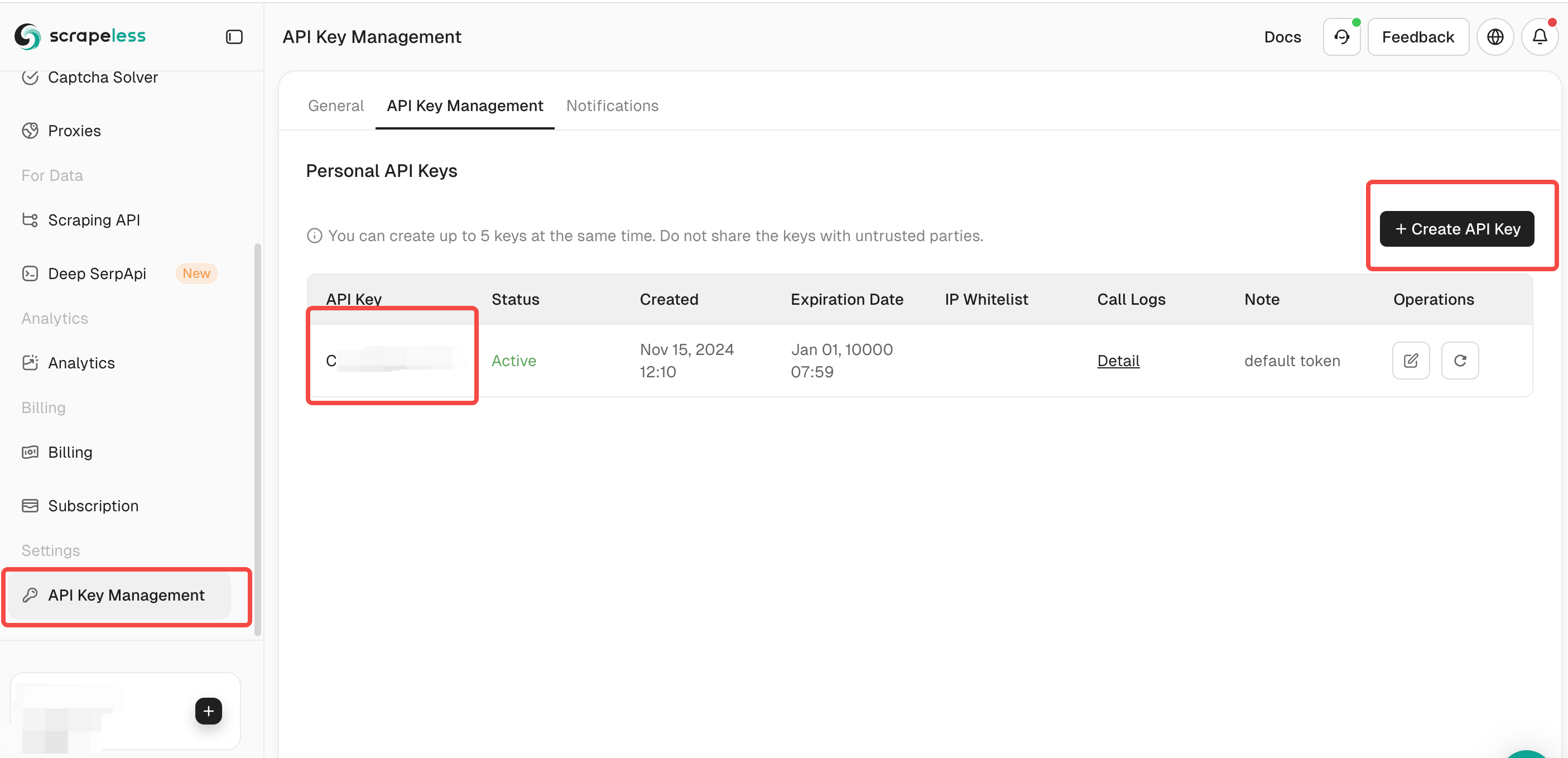
After signing up and logging into the Scrapeless Dashboard, go to the API Key Management page.
Click the "Generate API Key" button to generate your API Key.
Click the generated API key to copy it.
Scrapeless uses the API key to authenticate users and request permissions. You need to configure the key in the Scrapeless tool to perform effective data scraping.
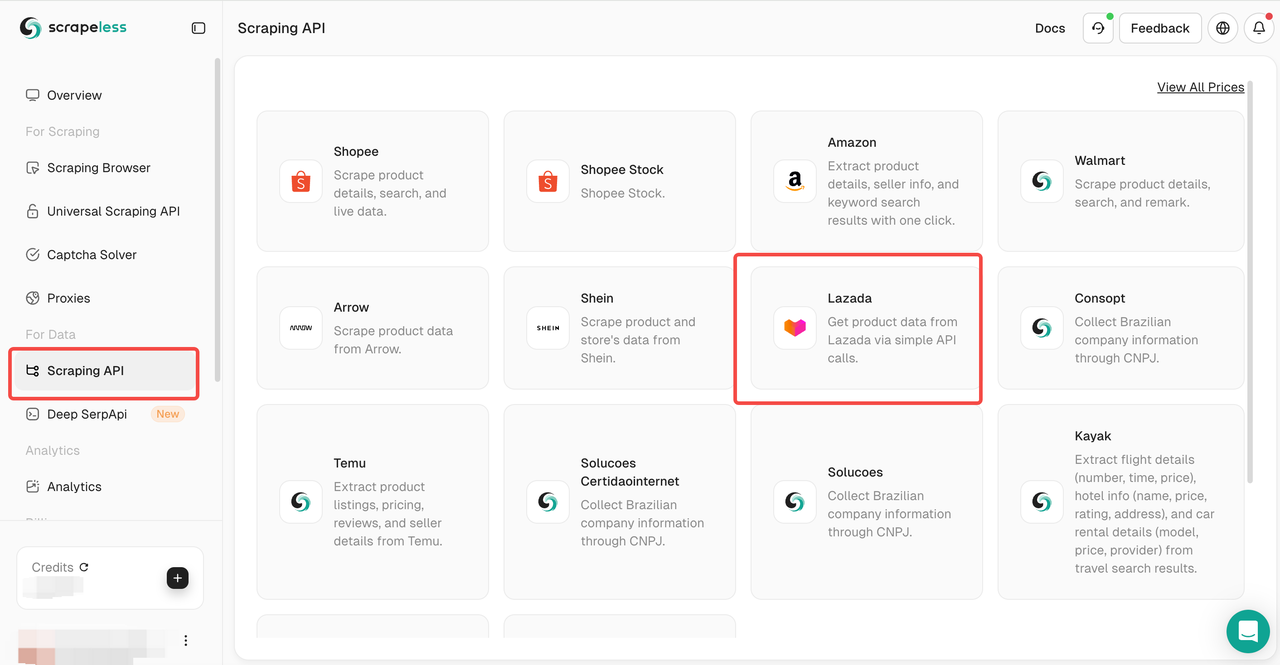
Step 3: Configure Scrapeless tool
Click Scraping API and select Lazada
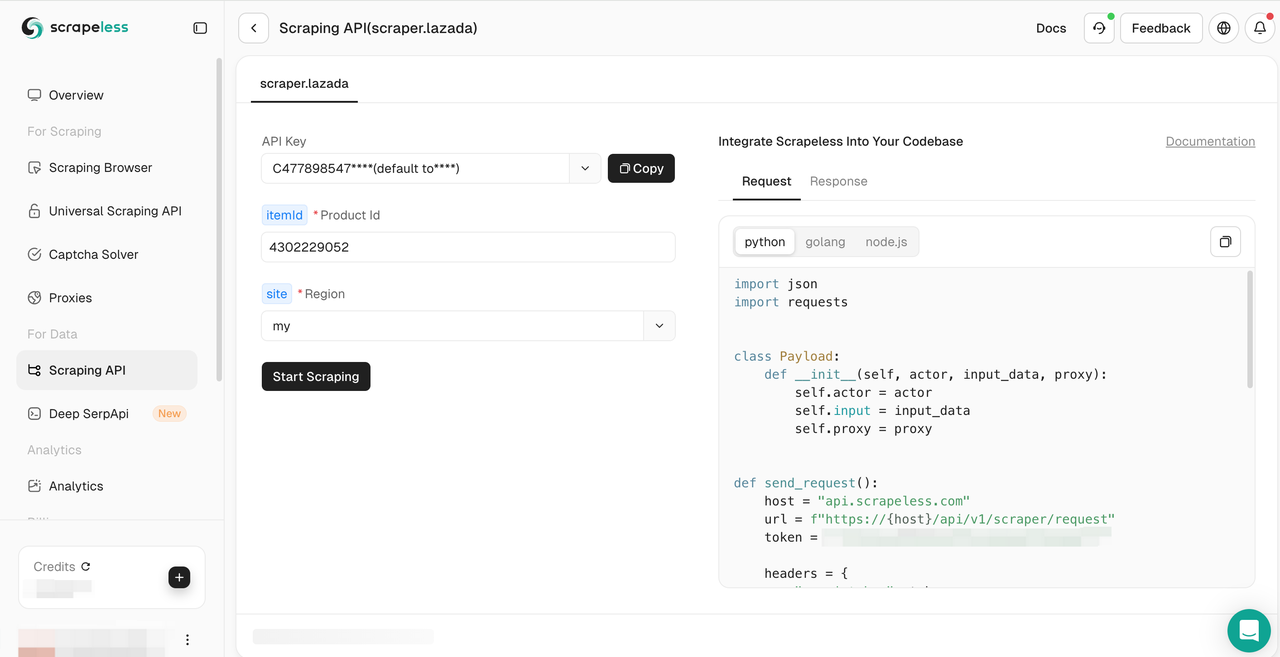
Then, configure the corresponding scraping parameters and click "Start Scraping".
Here is a Python code example to scrape Lazada product list using Scrapeless API:
Part 3. How to Extract Lazada E-commerce Datasets?
If you need to obtain the complete Lazada E-commerce Datasets, you can follow the steps below. Whether it is market research, competitive product analysis, or AI training data collection, these methods can help you extract Lazada data efficiently.
Step 1: Data storage and cleaning
The captured Lazada data needs to be stored and cleaned for subsequent analysis. You can use the following methods to store data:
CSV files (for small-scale data)
MySQL/MongoDB (for large-scale data storage)
Elasticsearch (for search and analysis)
Example: Save the captured Lazada data to a CSV file
Copy
import pandas as pd
# Assume data is JSON data obtained from the Scrapeless API
data_list = data.get("products", [])
# Convert to Pandas DataFrame
df = pd.DataFrame(data_list)
# Save as CSV
df.to_csv("lazada_products.csv", index=False)
print("Data has been saved to lazada_products.csv")
Step 2: Data analysis and visualization
After obtaining Lazada data, you can perform the following data analysis:
Price trend analysis (price changes in different time periods and different stores)
Best-selling product rankings (top 10 sales products and their growth trends)
Consumer feedback analysis (analyze keywords in comments and extract user concerns)
Example: Visualizing Price Distribution Using Matplotlib
Copy
import matplotlib.pyplot as plt
# Price data
prices = df["price"].astype(float)
# Draw a histogram
plt.hist(prices, bins=20, color='blue', alpha=0.7)
plt.xlabel("Price")
plt.ylabel("Number of Products")
plt.title("Lazada Product Price Distribution")
plt.show()
Step 3: Automatically crawl Lazada data regularly
In order to continuously obtain the latest Lazada data, you can set up regular crawling tasks, such as:
Use Python scheduled tasks (schedule module)
Use Crontab to automatically run scripts on the server
Integrate crawling tasks into Airflow for scheduling management
Example: Crawl Lazada product data on a daily basis
Copy
import schedule
import time
def job():
print("Starting Lazada data scraping...")
# Call Scrapeless API to get data
# Save to database
print("Scraping completed!")
# Set to run once a day at 8 o'clock
schedule.every().day.at("08:00").do(job)
while True:
schedule.run_pending()
time.sleep(60)
Part 3. Scrapeless Lazada API Pricing
Scrapeless API provides flexible pricing plans for developers and enterprises with different needs. Common pricing models include:
Pay per request: charge for each API call, suitable for small-scale data scraping.
Subscription: monthly or annual packages, suitable for high-frequency data collection.
Custom enterprise plan: customized services for large enterprises, supporting batch data scraping.
Scrapeless provides efficient data scraping APIs for major social media and e-commerce platforms, including Lazada, TikTok, Shopee, Amazon, Shein, and Instagram.
We also offer custom dataset services to meet various business data needs.
If you need more information or customized solutions, feel free to contact Liam via Discord 👉 Join Discord »
Compared with Lazada official API, Scrapeless Lazada Scraping API does not require complex certification and is more suitable for e-commerce automation, data scraping and market analysis.
Part 4. Official Lazada API vs. Scrapeless: Why Choose Scrapeless?
Feature
Official Lazada API
Scrapeless Lazada API
Authentication
Requires API key & approval
No authentication required
Rate Limits
Strict limits
Flexible
Access Restrictions
Limited to approved partners
Open to all users
Ease of Use
Complex setup
Simple API request
Data Availability
Only for approved sellers
Can fetch public product listings
🚀 Why Choose Scrapeless?
Break API limits, support large-scale data crawling
Scrapeless Lazada API is more suitable for developers, market researchers, and data analysts who need to scrape large amounts of Lazada data.
Part 5. How to Bypass Lazada Bot Detection for Scraping?
Lazada uses a variety of anti-crawler technologies, such as CAPTCHA, IP restriction, User-Agent identification, behavioral analysis, etc., to prevent data scraping from unofficial APIs. The following methods can help bypass Lazada's anti-crawler mechanism.
Method 1. Use Scrapeless Scraping Browser
Scrapeless provides a Scraping Browser solution with the following advantages:
Automatically bypass CAPTCHA verification and reduce human-machine verification interference.
Simulate real user behavior and reduce the risk of crawlers being blocked.
Support dynamic page loading, suitable for Lazada pages rendered by JavaScript.
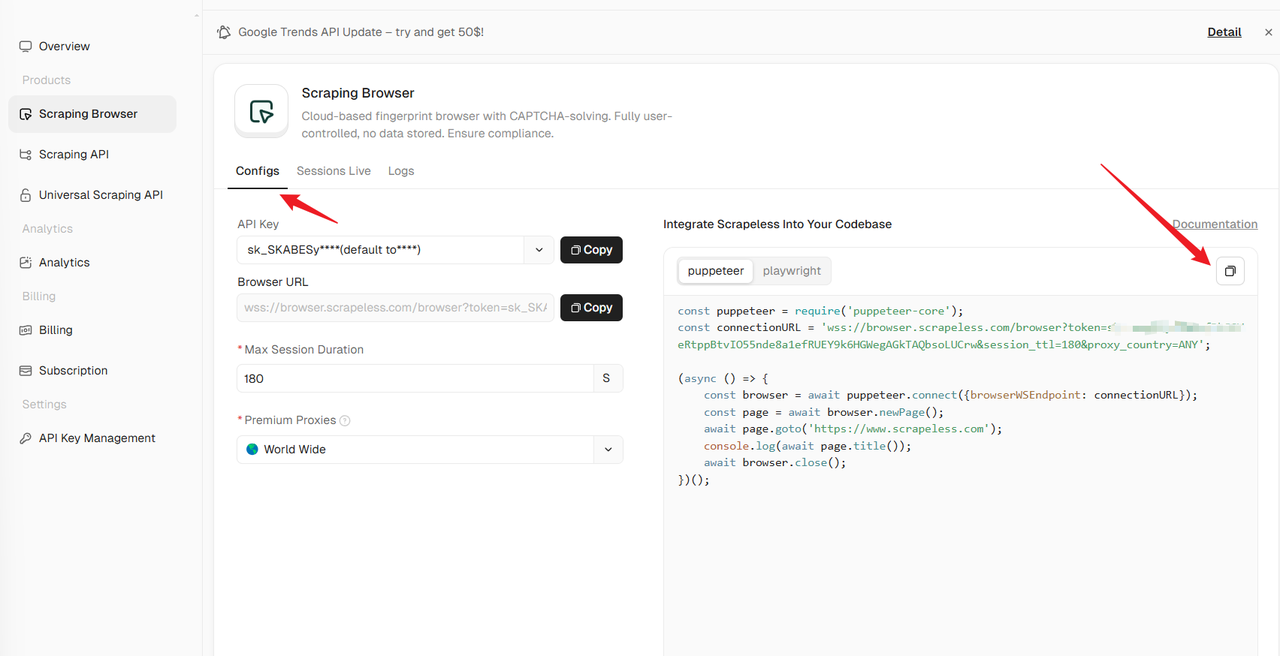
Step 1: Run your Scraping Browser
Go to the Scraping Browser menu and click Configs. You can select your apiKey and other configurations on the left, and then select your preferred crawler framework sample code on the right. Copy the sample code to your IDE, modify the code execution logic according to the actual situation, and run the code.
How to get your Scrapeless API Key
Navigate to API Key Management.
Click Create to generate your unique API Key.
Once created, simply click on the API Key to copy it.
Step 2: The following is a code example that you can integrate into your tool.
Proxies rotate IPs to avoid being blocked due to high access frequency in a short period of time.
It is recommended to use residential proxies or data center proxies.
Method 3. Disguise User-Agent
Copy
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
Method 4. Set the request interval to reduce the access frequency
Use time.sleep() to control the request rate and avoid triggering the rate limit.
Part 6. FAQ: Common Questions About Lazada Data Scraping
1. Is it legal to use Lazada Scraper?
As long as you follow the website's crawling rules and ensure that the data is used for legal purposes, there will be no problem.
2. Which Lazada sites does the Scrapeless API support?
Scrapeless currently supports multiple Lazada markets in Southeast Asia, including Malaysia, Singapore, Indonesia, etc.
3. Can I crawl the product data of competitors?
Yes, Scrapeless allows users to crawl public product information for market analysis and competition research.
4. How to improve the success rate of data crawling?
Using techniques such as proxy rotation, Scraping Browser, and simulating user operations can improve the success rate of crawling.
Part 7. Conclusion
With Scrapeless API, you can easily bypass the limitations of Lazada API and efficiently obtain Lazada product lists. Whether it is competitor analysis, market research or AI data training, Scrapeless provides the best Lazada Scraper solution. If you are looking for an efficient and stable Lazada Data Scraper, Scrapeless is undoubtedly the best choice!
Note: This guide has been thoroughly tested by our team at the time of writing. However, since websites frequently update their code and structure, some steps may no longer work as expected. We only scrape publicly available data and strictly prohibit scraping personal information, login-restricted data, or engaging in any actions that violate website terms of service. Please ensure that your data collection practices comply with legal regulations and website policies.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.