![How to Scrape Walmart Product Data Using Python [Price, Reviews, and More]](/_next/image?url=https%3A%2F%2Fassets.scrapeless.com%2Fprod%2Fposts%2Fscrape-walmart-product%2F14c86a4c6d7107464e4d7120991df343.png&w=1920&q=100)
How to Scrape Walmart Product Data Using Python [Price, Reviews, and More]
Advanced Data Extraction Specialist
Walmart is one of the largest online retailers, offering a vast amount of product data, including prices, reviews, stock availability, and detailed descriptions. Extracting this data can be valuable for price comparison, market research, or competitive analysis.
However, Walmart has robust bot detection mechanisms, making it challenging to scrape data manually. In this guide, we’ll explore different Python-based scraping methods, and later introduce Scrapeless, a powerful alternative that bypasses these challenges effortlessly.
Part 1: Understanding Walmart’s Website Structure
Before scraping, it’s crucial to understand how Walmart’s website is structured:
- Static Content: Some elements, like product names and descriptions, are readily available in the HTML source.
- Dynamic Content: Prices, stock availability, and reviews may load asynchronously via JavaScript or API calls.
To analyze Walmart’s structure: - Open a product page on Walmart.com.
- Right-click and select Inspect Element to examine the HTML structure.
- Look for key data attributes like price, product ID, or reviews.
How to Scrape Walmart: A Step-by-Step Tutorial
Scraping Walmart's website for product data can provide valuable insights, but it requires the right tools and techniques to do so effectively. In this guide, we'll walk you through the entire process of Walmart data scraping using Python and Selenium, including how to bypass bot detection. Whether you're building a Walmart scraper or need product details for market research, this tutorial will cover everything you need.
Part 1: Introduction to Walmart Data Scraping
Before diving into the steps, let's understand what Walmart data scraping involves. Walmart scraper tools can extract product information from Walmart's online store, including prices, descriptions, reviews, and ratings. However, due to Walmart's anti-scraping measures, you'll need to take a few precautions to avoid being blocked.
Part 2: Prerequisites for Scraping Walmart
To get started with Walmart data scraping, you'll need the following:
- Python: A versatile programming language for web scraping tasks.
- Selenium: A powerful tool for automating web browsers.
- ChromeDriver: The browser driver needed to interface with Chrome through Selenium.
- pip: Python's package installer for installing necessary libraries.
Ensure you have these installed by running the following commands:
pip install seleniumAdditionally, download ChromeDriver from the official site and ensure it's compatible with your Chrome version.
Part 3: Setting Up Your Walmart Scraper with Selenium
Now that you have everything ready, let's begin setting up the scraper. This section explains how to set up the scraper to interact with Walmart's website.
Step 1: Importing Required Libraries
Start by importing the necessary libraries:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import ServiceStep 2: Initialize the Web Driver
Next, initialize the Chrome WebDriver. Ensure you replace the path with your own ChromeDriver location:
s=Service('/path/to/chromedriver')
driver = webdriver.Chrome(service=s)Step 3: Navigating to Walmart
Once the browser is ready, navigate to Walmart's homepage:
driver.get("https://www.walmart.com")
Now, you should see Walmart's homepage in the browser window.
Part 4: Searching for Products on Walmart
To scrape specific products, you first need to search for them on Walmart’s site. Use the search bar to input a product query, such as "wireless headphones."
Step 1: Locate the Search Bar
Inspect the webpage to locate the search bar. Right-click on the search field and click Inspect to find the name attribute. You should see something like this:
<input type="text" name="q" />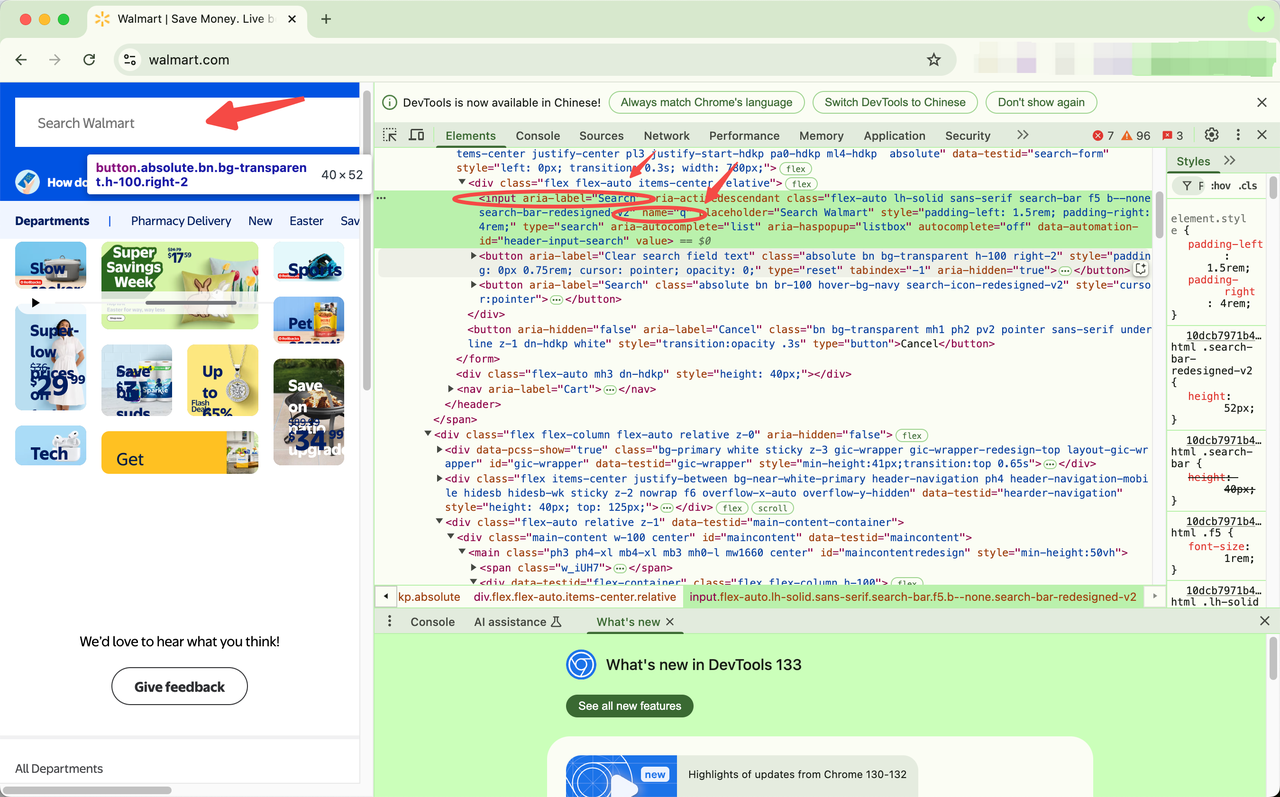
Step 2: Input Your Search Term
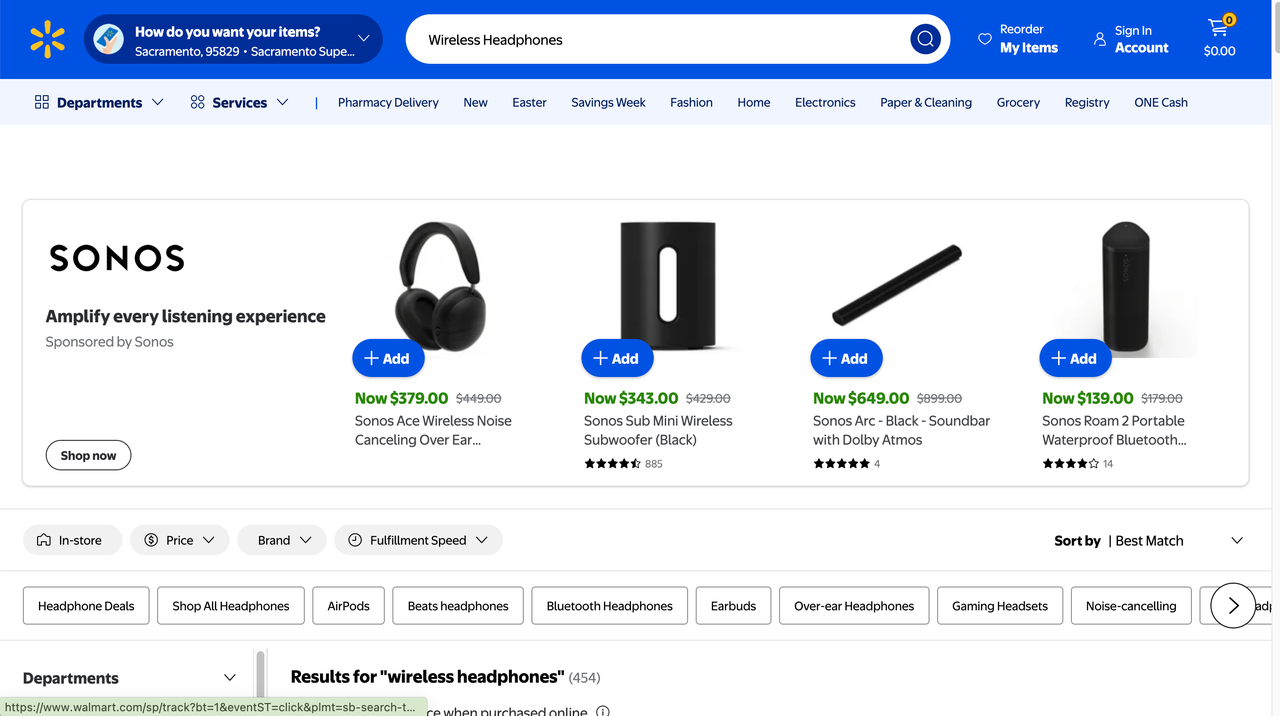
Now that you've located the search bar, you can simulate typing a query using Selenium:
search = driver.find_element("name", "q")
search.send_keys("Wireless Headphones")
search.send_keys(Keys.ENTER)This will perform the search for "Wireless Headphones" on Walmart.
Part 5: Navigating to a Product Page and Scraping Data
Once you've searched for a product, you can click on a specific product to access its detailed page. Here's how to extract the product name, price, rating, and number of reviews:
Step 1: Open the Product Page
For example, you can directly access a product page:
url = "https://www.walmart.com/ip/Sonos-Ace-Wireless-Noise-Canceling-Headphones-Black/5902797595"
driver.get(url)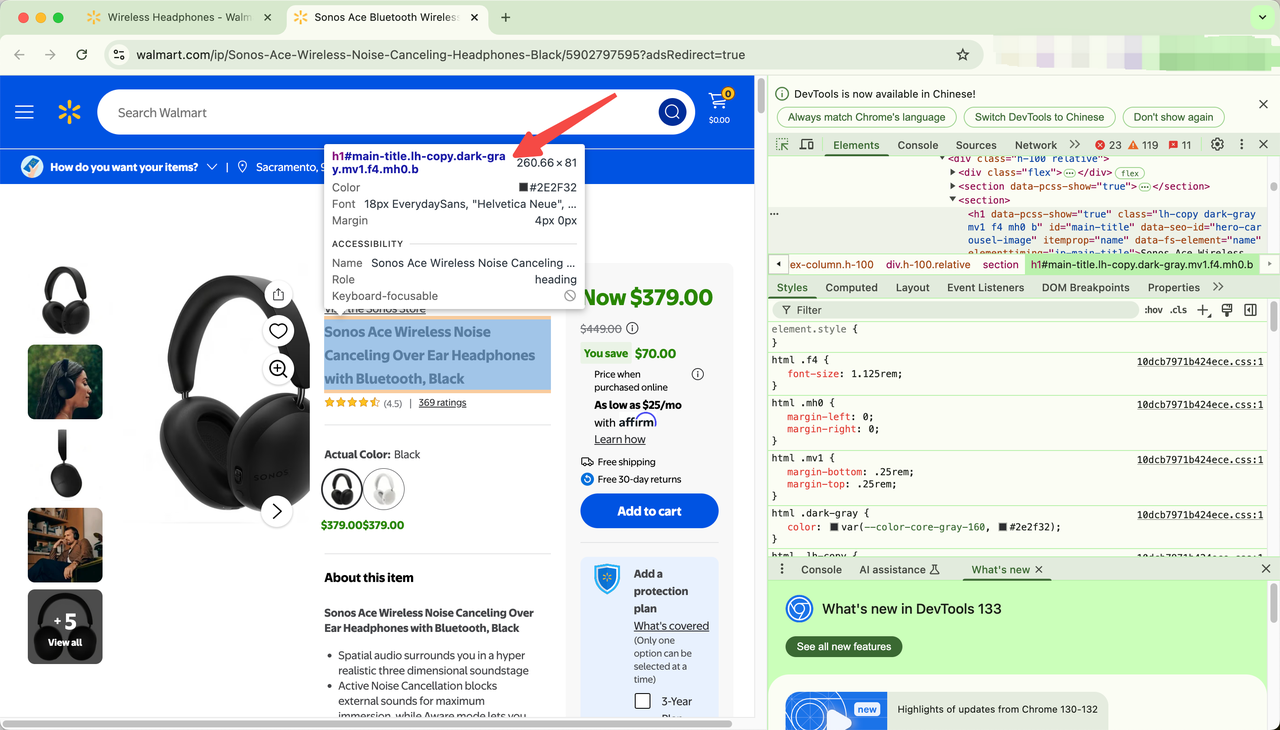
Once you have the page open, right-click on it and click Inspect. You can navigate to any element you want to grab information about. For example, after inspecting the product title, you’ll notice that the title is in an H1 tag. Since this is the only H1 tag on the page, you can grab it using the following code:
title = driver.find_element(By.TAG_NAME, "h1")
print("Product Title:", title.text)Likewise, you can see that the price element in the page uses the itemprop attribute.
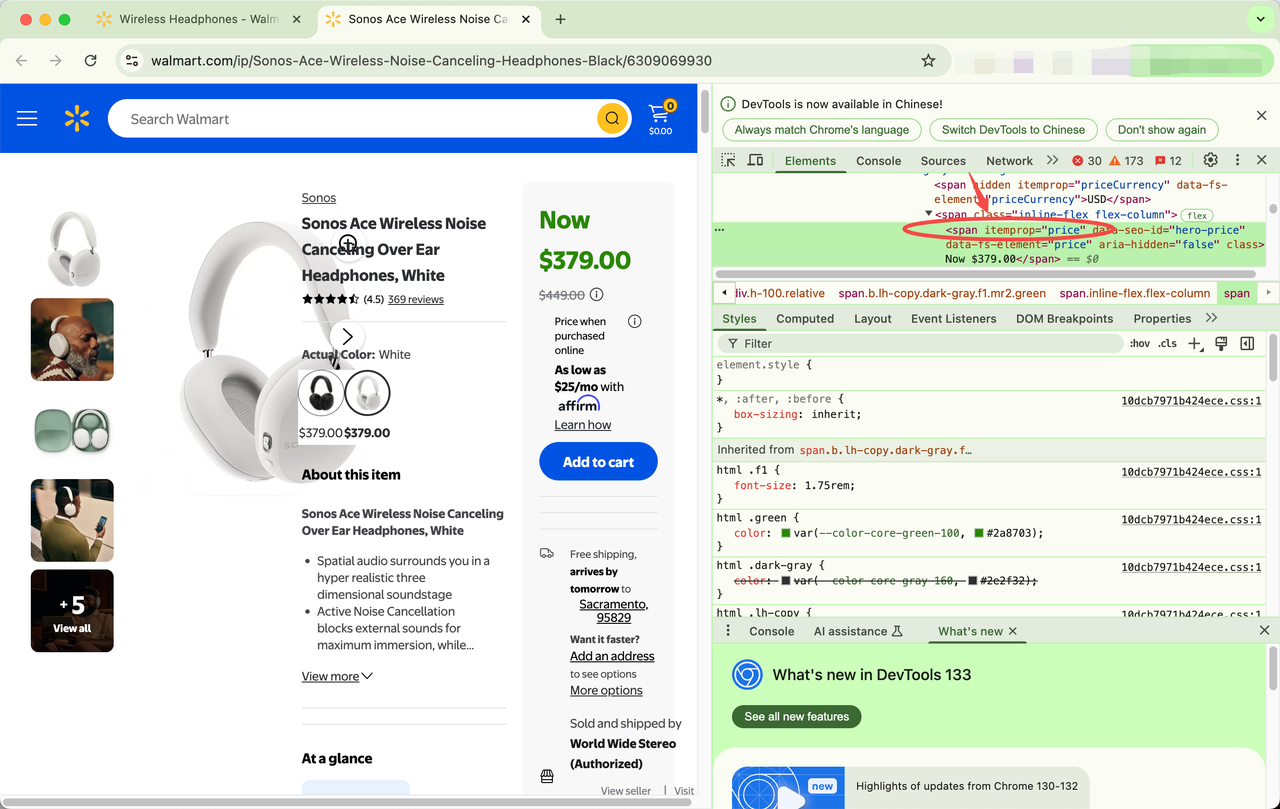
Similarly, you can check to see where other information is on the page. You can get the rating and number of reviews with the following code.
# Get ratings
rating = driver.find_element(By.CLASS_NAME, "f-headline")
print("Rating:", rating.text)
# Get number of reviews
number_of_reviews = driver.find_element(By.CLASS_NAME, "dark-gray")
print("Number of Reviews:", number_of_reviews.text)Step 2: Extract Product Information
After the page loads, use the following code to extract details:
title = driver.find_element(By.TAG_NAME, "h1")
print("Product Title:", title.text)
price = driver.find_element(By.CSS_SELECTOR, '[itemprop="price"]')
print("Price:", price.text)
rating = driver.find_element(By.CLASS_NAME, "f-headline")
print("Rating:", rating.text)
number_of_reviews = driver.find_element(By.CLASS_NAME, "dark-gray")
print("Number of Reviews:", number_of_reviews.text)This will output the product's title, price, rating, and number of reviews.
Recommended tool: Scrapeless, easy to crawl Walmart data
If you are looking for an efficient and simple way to crawl Walmart data, Scrapeless is a tool worth considering. Compared with traditional crawling methods, such as using Python and Selenium, Scrapeless provides a simpler and more automated crawling experience. Scrapeless is designed to solve Walmart's anti-crawler mechanism, and can bypass verification codes, IP blocking, and other anti-crawler technologies, making the data crawling process smoother. The following are detailed steps on how to use Scrapeless to crawl Walmart data.
Pricing: Free trial and pay-as-you-go plans available.
Output Formats and Delivery: Get data in JSON, NDJSON, or CSV files via webhook or API delivery.
Compliance and Support: Scrapeless ensures 100% compliance with GDPR and CCPA, with 24/7 global support.
Step 1: Register and log in to Scrapeless
Visit the Scrapeless official website and create an account.
Step 2: Get the Scrapeless API Key
- After signing up and logging into the Scrapeless Dashboard, go to the API Key Management page.
- Click the "Generate API Key" button to generate your API Key.
- Click the generated API key to copy it.
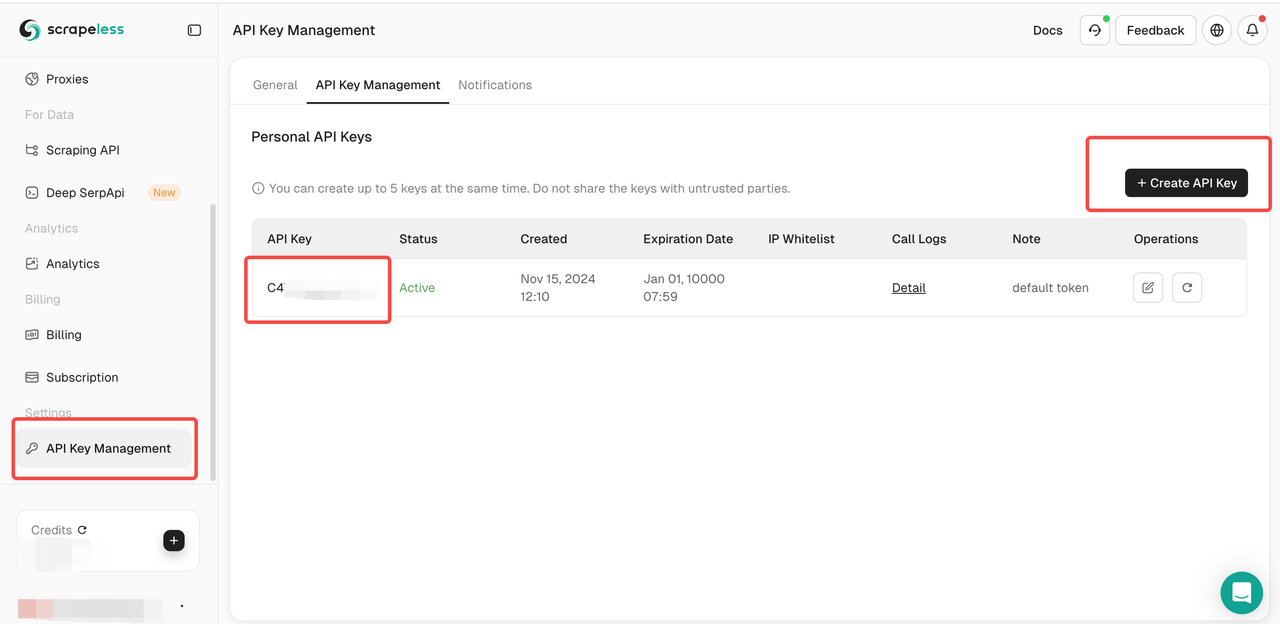
Scrapeless uses the API key to authenticate users and request permissions. You need to configure the key in the Scrapeless tool to perform effective data scraping.
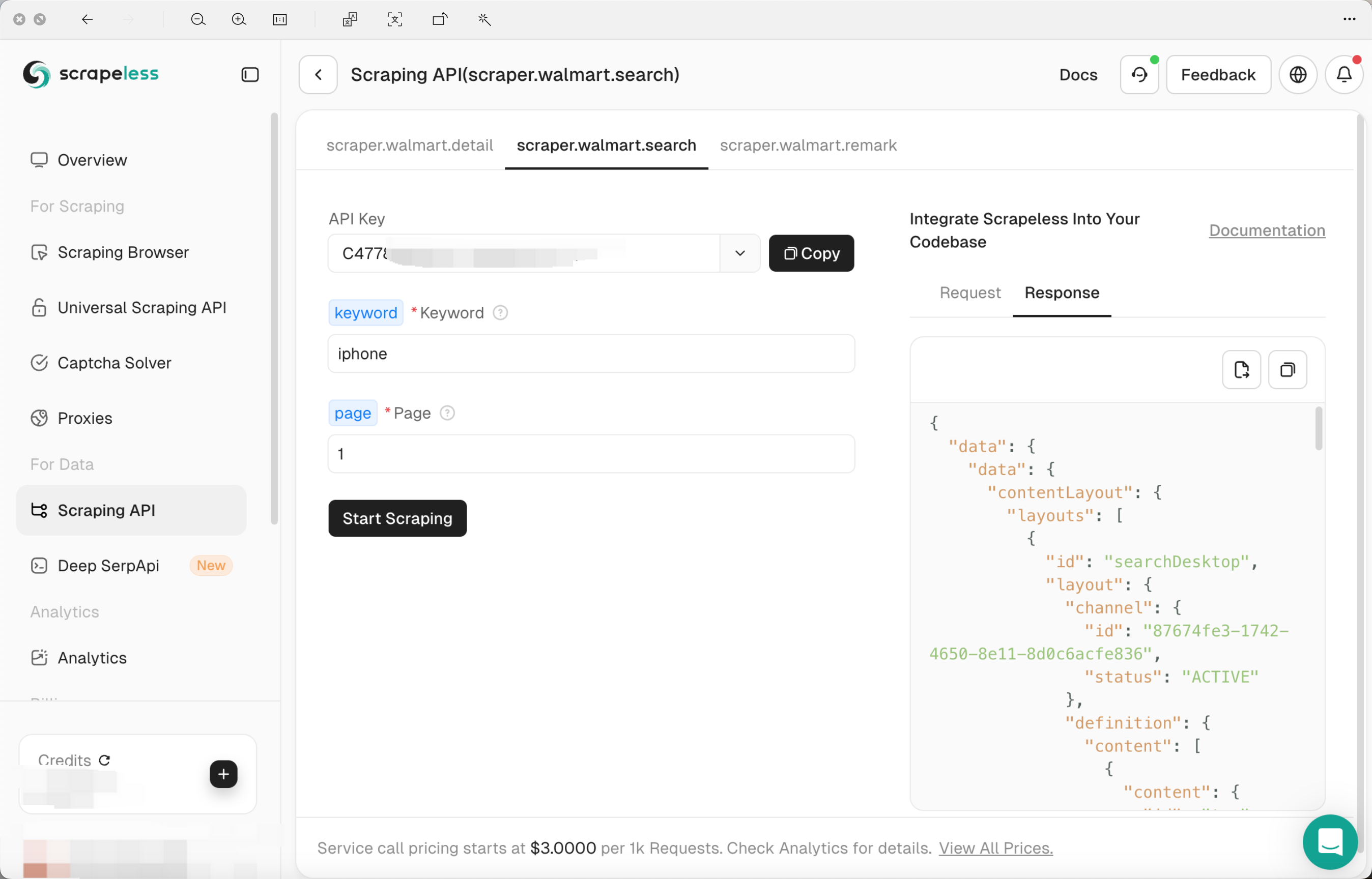
Step 3: Configure Scrapeless tool
When configuring Scrapeless, you only need to specify the target page or search term to be crawled in the control panel, and select the data field to be crawled (such as product detail、search、remark). This process does not require writing a single line of code, while traditional Python and Selenium methods require manual writing of a large number of scripts to locate page elements and crawl data.
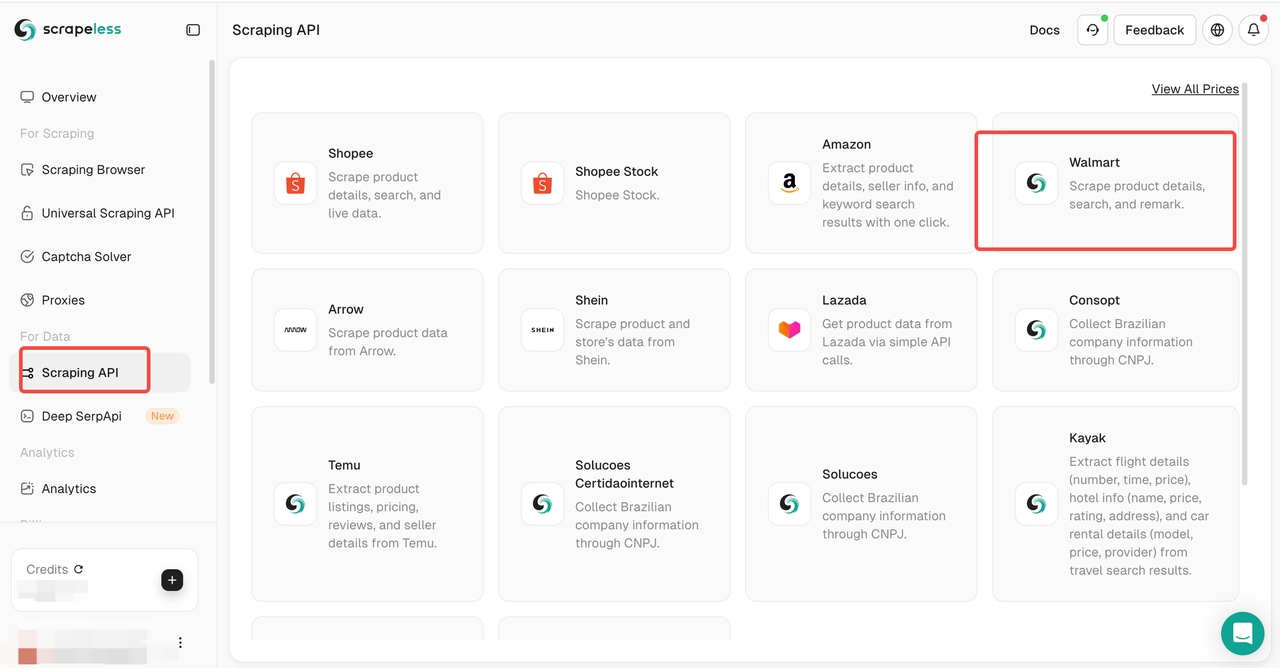
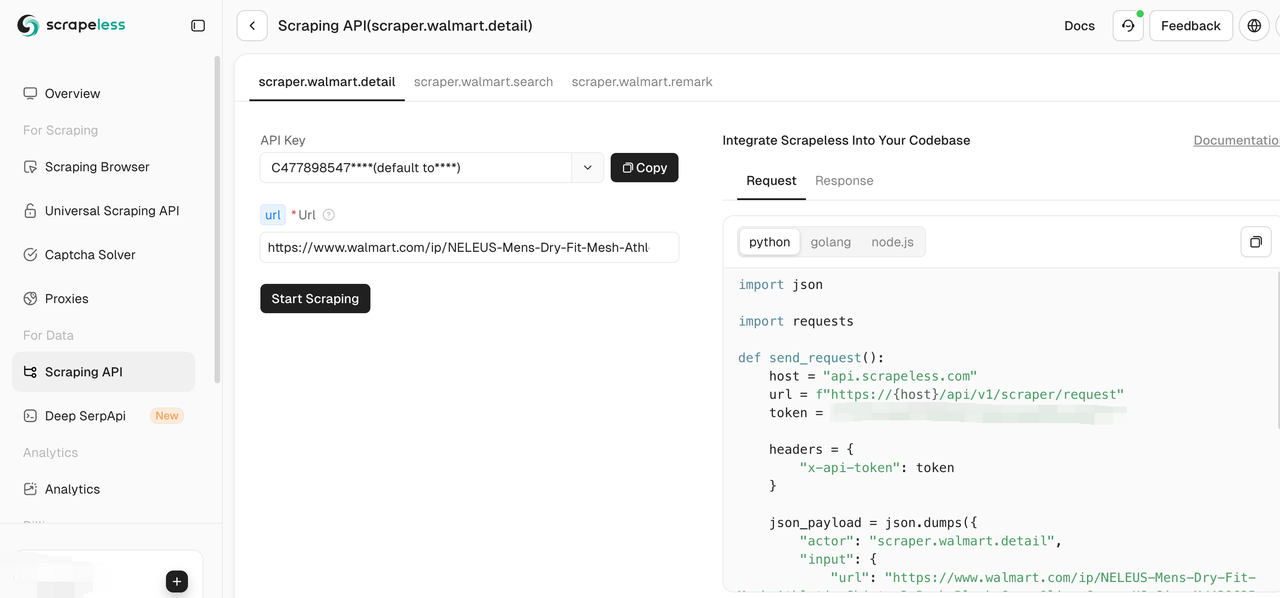
Step 4: Start the crawling task
After clicking the "Start Scraping" button, Scrapeless will automatically bypass Walmart's anti-crawling measures and crawl data.
How to Bypass Walmart Antibot
Walmart employs sophisticated antibot measures to prevent automated data scraping, including CAPTCHA challenges, IP blocking, browser fingerprinting, and request rate limiting. If you attempt to scrape Walmart using traditional tools like Selenium, Puppeteer, or Scrapy, you may quickly run into these restrictions, making data extraction extremely difficult.
The most effective way to bypass Walmart’s antibot system without dealing with complex configurations is to use Scrapeless Scraping Browser. This tool is specifically designed to handle Walmart’s anti-scraping defenses, allowing you to extract data without being blocked.
🚀 Ready to collect Walmart’s publicly available data safely and compliantly?
With Scrapeless, you can effortlessly access Walmart product data without coding or violating platform policies.👉 Log in to start collecting now and streamline your data workflow today!
Why Scrapeless Scraping Browser?
Compared to traditional scraping methods, Scrapeless Scraping Browser provides a hassle-free and automated solution to bypass Walmart's antibot system. Here's why it's superior:
- Automatic IP Rotation – Scrapeless automatically switches between multiple residential and datacenter proxies to prevent IP bans.
- Built-in CAPTCHA Solver – Handles CAPTCHA challenges without requiring third-party solvers or manual intervention.
- Browser Fingerprint Evasion – Mimics real human browsing behavior by rotating user agents, handling cookies, and avoiding bot detection patterns.
- Headless Stealth Mode – Unlike Selenium, which can be easily detected by Walmart, Scrapeless runs in a way that mimics real user interactions, preventing detection.
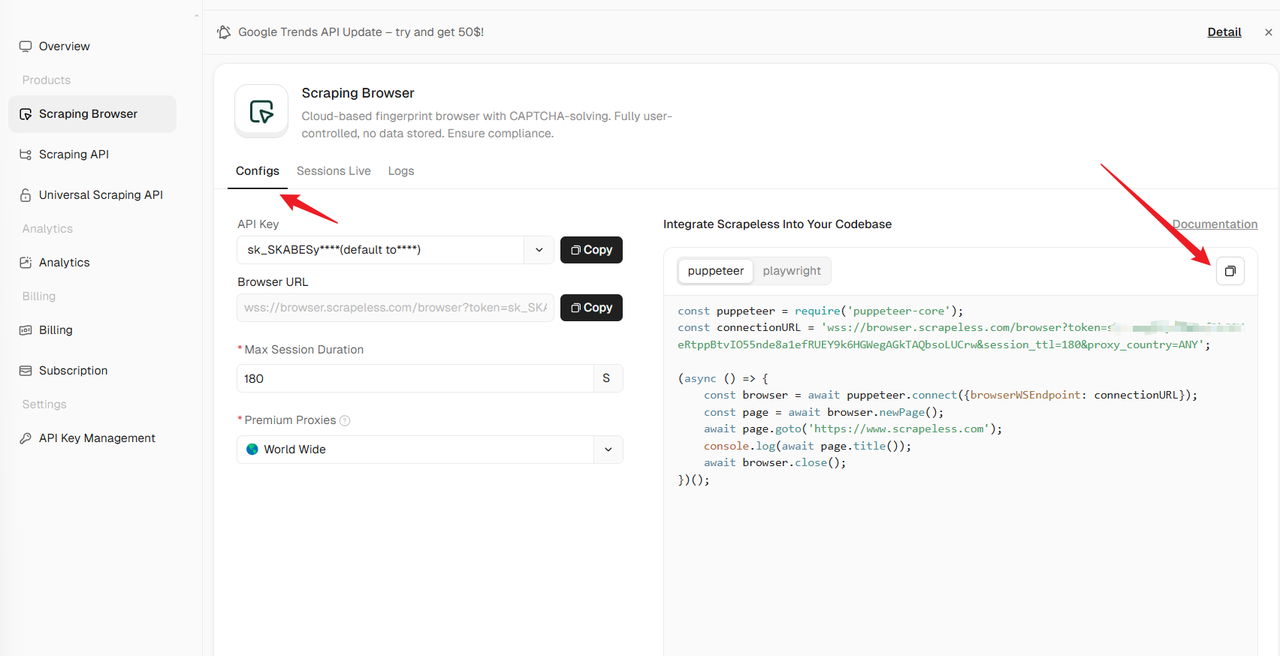
Steps to Use Scrapeless Scraping Browser to Bypass Walmart Antibot
Go to the Scraping Browser menu and click Configs. You can select your apiKey and other configurations on the left, and then select your preferred crawler framework sample code on the right. Copy the sample code to your IDE, modify the code execution logic according to the actual situation, and run the code.
Conclusion
Scraping Walmart product data can provide valuable insights, but traditional Python scraping methods face anti-bot challenges.
Comparison of Methods:
| Method | Pros | Cons |
|---|---|---|
| BeautifulSoup | Fast, easy for static data | Can't handle JavaScript-rendered content |
| Selenium | Handles JavaScript | Slow, high risk of detection |
| Scrapeless | No coding required, bypasses all blocks | Requires an API subscription |
For small-scale scraping, Python methods may work. However, for large-scale data extraction, Scrapeless is the best solution, as it handles bot detection, proxies, and JavaScript automatically.
Final Recommendation:
- Use Python + BeautifulSoup for basic scraping.
- Use Selenium if dynamic content is needed.
- Use Scrapeless for hassle-free, large-scale Walmart data scraping.
🚀 Scrapeless Advanced Data Services
In addition, Scrapeless also provides a variety of advanced data collection services, such as ready-to-use Walmart datasets and efficient proxy solutions.
Whether you're looking for dataset services or testing customized data collection solutions, you can contact Liam through Discord for support.
Faqs
How to Bypass Verification for Walmart?
Walmart uses verification methods like CAPTCHA and bot detection to prevent automated scraping. The easiest way to bypass these restrictions is by using Scrapeless Scraping Browser, which automatically handles CAPTCHAs, rotates fingerprints, and mimics real user behavior.
Alternatively, you can:
- Use rotating proxies to avoid IP bans.
- Add delays between requests to reduce detection risks.
- Rotate user agents to appear as different users.
Is scraping Walmart legal?
Scraping Walmart’s publicly available data is generally legal, but avoid violating Walmart’s Terms of Service. Always scrape ethically and follow robots.txt guidelines.
How often should I scrape Walmart?
To avoid bans, scrape at reasonable intervals or use an API like Scrapeless.
Note: This guide has been thoroughly tested by our team at the time of writing. However, since websites frequently update their code and structure, some steps may no longer work as expected. We only scrape publicly available data and strictly prohibit scraping personal information, login-restricted data, or engaging in any actions that violate website terms of service. Please ensure that your data collection practices comply with legal regulations and website policies.
Related Resources
If you're interested in more advanced scraping techniques and tutorials, check out these helpful guides:
-
How to Use Undetected ChromeDriver for Web Scraping
Learn how to avoid detection and scrape websites safely using Undetected ChromeDriver. -
How to Scrape Google Product Online Sellers with Python
A step-by-step guide to scraping Google Shopping seller information using Python. -
How to Scrape Google Play Store App in Python
Discover how to extract app details, ratings, and reviews from Google Play Store. -
How to Scrape Google Product Reviews Results with Python
Easily collect product reviews from Google Shopping search results. -
How to Bypass Cloudflare Protection and Turnstile Using Scrapeless | Complete Guide
Learn how to bypass Cloudflare’s bot protection and Turnstile challenge effectively. -
How to Bypass TLS Fingerprinting
Understand TLS fingerprinting and how to avoid being blocked during scraping. -
How to Get Lazada Product List through Scrapeless?
Quickly collect Lazada product listings using Scrapeless scraping API without hassle.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


