Scrapeless x Cursor
Cursor leverages Scrapeless MCP Server to deliver real-time, accurate answers.

Cursor is an intelligent code editor that integrates AI assistants like Claude and GPT-4. It supports the Model Context Protocol (MCP), allowing seamless integration of external data sources. This guide will walk you through setting up Scrapeless MCP Server on Cursor to enhance AI-powered workflows with real-time data retrieval.
In today's fast-paced development environment, having real-time data access directly within your coding workflow isn't just convenient—it's transformative. The integration of Scrapeless MCP Server with Cursor bridges the critical gap between AI-powered code assistance and live external data, creating what we call "context-aware development."
At its core, this integration combines three powerful technologies:
When properly configured, these components work together seamlessly:
Let's make everything simple!
Figure out the detailed integrating steps now!
Scrapeless MCP Server is a server built on the Model Context Protocol (MCP) by Scrapeless. It enables AI models (such as Claude and GPT) to access external information sources during conversations. With advanced search capabilities, Scrapeless MCP Server retrieves real-time data from sources like Google Search, including Google Maps, Google Jobs, Google Hotels, and Google Flights, ensuring accurate and relevant responses.
To run Scrapeless MCP Server, you must first install Node.js and npm:
node -v
npm -vv22.x.x
10.x.xTo use Scrapeless MCP Server, you need an API key:
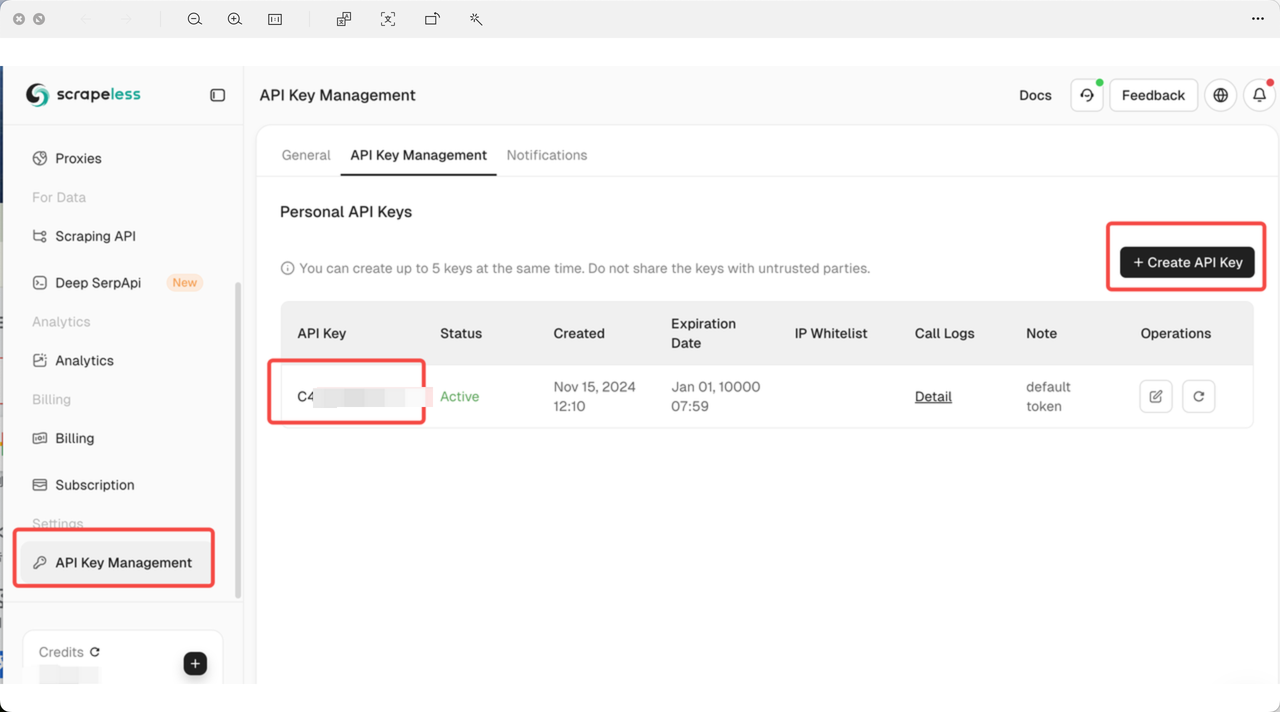
The Using Guide: https://x.com/Scrapelessteam/status/1910288052775465431
Download and install the Cursor desktop application from the official site.
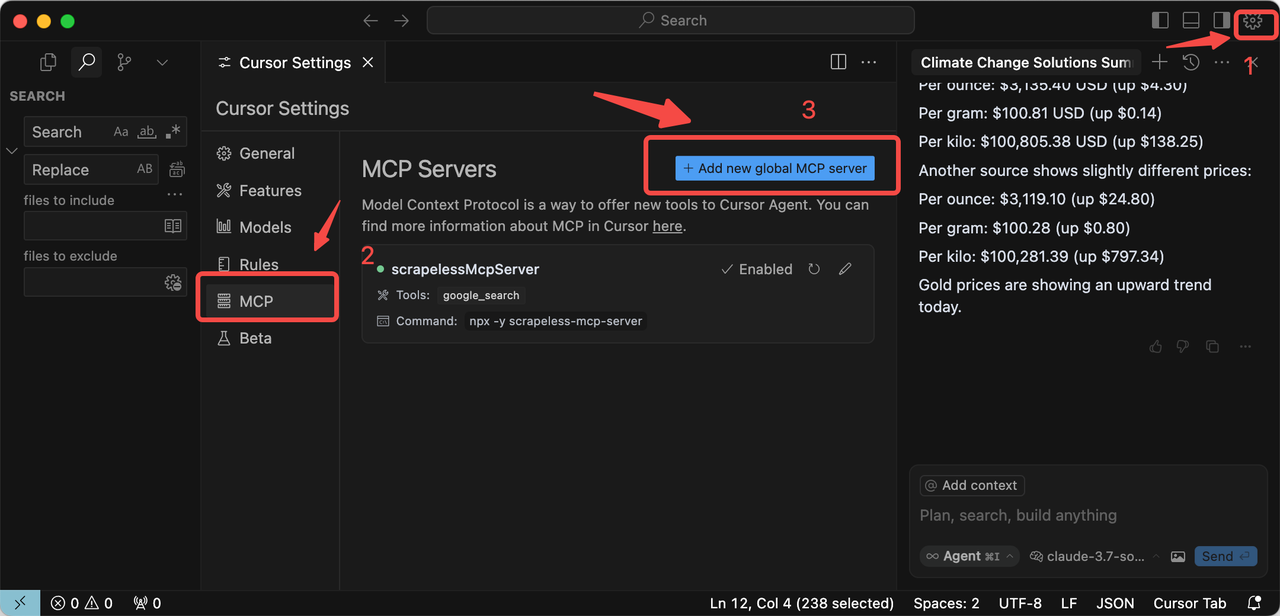
{
"mcpServers": {
"scrapelessMcpServer": {
"command": "npx",
"args": ["-y", "scrapeless-mcp-server"],
"env": {
"SCRAPELESS_KEY": "YOUR_SCRAPELESS_KEY"
}
}
}
}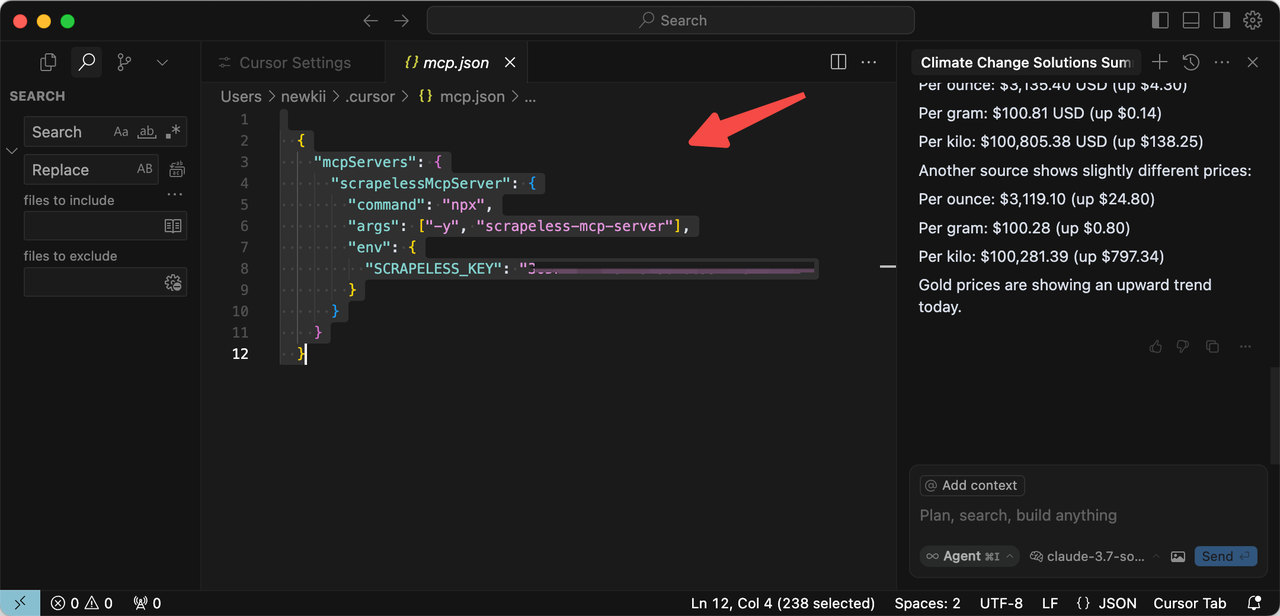
Now, you can save the configuration and restart Cursor.
Once the setup is complete, you can start using Scrapeless MCP Server within Cursor by entering queries in the chat interface. For example:
Please help me check today's gold price.The cursor will then call Scrapeless MCP Server and return accurate real-time results.
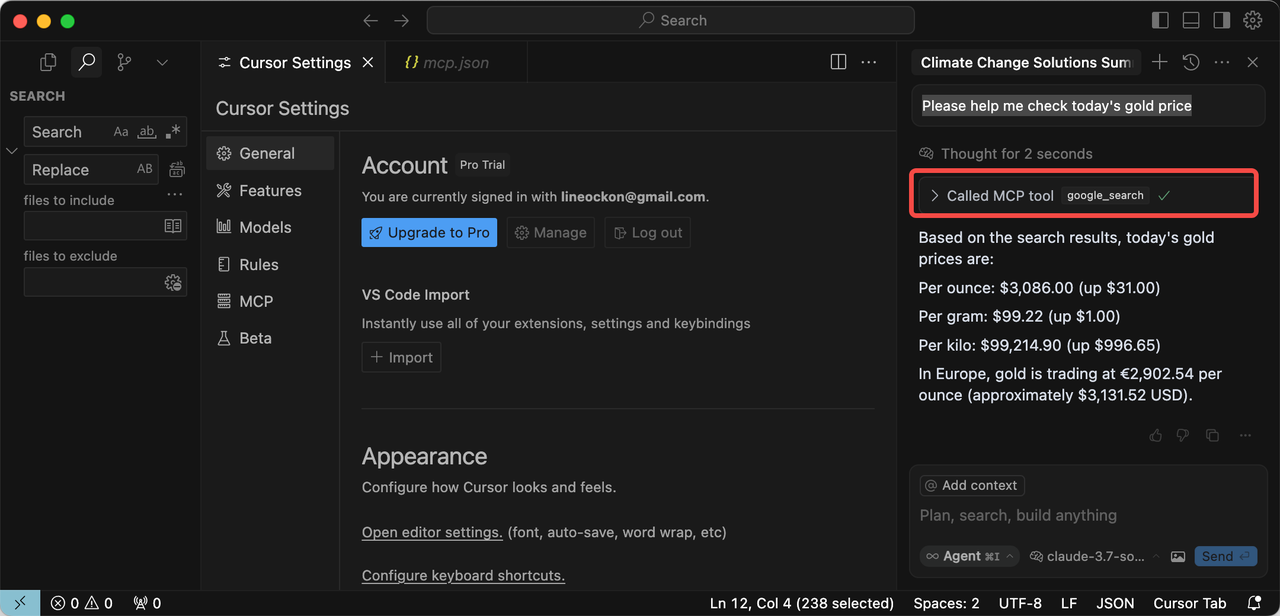
By integrating Scrapeless MCP Server with Cursor, you can significantly enhance AI-assisted coding with real-time information retrieval. Follow this guide to set up your environment and unlock the full potential of AI-powered development.
Get the free trial now and figure out a new possibility!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.