
5 Best Web Crawlers in 2025: Complete Guide for Efficient Data Scraping
Advanced Data Extraction Specialist
There are many web crawlers that can help you extract data, index web pages, or perform automated web scraping efficiently. However, you may find that not all crawlers are equally effective—some have limited functionality, while others may be difficult to configure or too resource-intensive. Sometimes, choosing the wrong tool can slow down your workflow or even result in IP bans. So, how do you find the right one?
To solve this problem, all you need is a best web crawler that balances performance, ease of use, and scalability. Given that, we have selected and reviewed the 5 best web crawlers that offer powerful features for various scraping needs. Keep reading to find the one that suits your requirements best.
| Product | Ease of Use | Features | Best For | Type | Price |
|---|---|---|---|---|---|
| Scrapeless | Very easy, user-friendly interface with advanced automation | Advanced anti-blocking tech, proxy pool, fast data extraction, dynamic rendering support, CAPTCHA unlocking, real browser for anti-detection | Professionals & businesses needing high-performance data scraping | Cloud-based, large-scale scraping | From $49/month, subscription discounts available |
| WebHarvy | Easy-to-use, point-and-click interface | Visual scraping interface, supports scraping images, links, text, scheduler for automated crawling | Small to medium businesses scraping structured data | Desktop-based, graphical interface | From $129 |
| OutWit Hub | Moderate ease of use, some technical knowledge required | Auto-detects patterns, extracts images, links, text, and other data types | Users needing flexible and customizable scraping | Desktop-based, browser extension | Starting at €95 |
| ParseHub | Easy-to-use, minimal setup required | Scrapes dynamic websites, supports multiple data formats, works with complex web structures | Users scraping complex or dynamic websites | Desktop-based, with cloud options | Starting at $189/month |
| Content Grabber | Moderate, but powerful features require learning | Full automation, supports scraping large datasets, advanced data export options | Agencies & developers scraping large volumes of data | Desktop-based, powerful scripting support | From $449 to $2495 |
Now let’s get into the details and discuss these tools along with some web crawling basics.
What is Web Crawling?
Web crawling is the process of using automated software to browse and extract data from websites. The software, known as a web crawler or spider, follows links on a site to gather data such as text, images, and other content for further use.
Why is Web Crawling Important?
Web crawling is essential for:
- Search Engine Indexing: Crawlers help search engines like Google index webpages for better search results.
- Market Research: Businesses use crawlers to monitor competitor pricing, product details, and trends.
- Data Collection: It helps gather large datasets for analysis, machine learning, and insights.
- Efficiency: Automates data gathering, saving time and resources.
How to Crawl Data?
To crawl data, follow these steps:
Select Target Websites: Identify the sites you want to gather data from.
Set Up a Crawler: Use tools or custom scripts to automate the process.
Extract Data: Define what data you need and configure the crawler.
Store Data: Save the extracted information in a structured format for analysis.
Web Crawling Technology
Web crawlers use various technologies like:
- HTML Parsing: Extracts data from a webpage's HTML.
- API Crawling: Uses APIs for structured data retrieval.
- Headless Browsers: Tools like Puppeteer help extract data from JavaScript-heavy sites.
- Proxies & CAPTCHA Solving: Prevents blockages by rotating IPs and bypassing security measures.
What is a Web Crawler?
A web crawler is an automated program designed to collect and replicate web data. In almost every industry, businesses and organizations eventually need to extract data for various use cases.
However, web crawlers are not just simple programs for bulk copying information. They must be powerful enough to scrape data from multiple sources and intelligently mimic human behavior to ensure data extraction without being blocked.
Why Use a Web Crawler?
When it comes to large-scale data extraction, manual online scraping is impractical. Additionally, automation helps set strict algorithms and avoids ambiguity. Using a web crawler offers the following advantages over manual methods:
- Higher Accuracy: Automated crawlers ensure data is collected consistently without human errors.
- Cost-Effective: Reduces the costs associated with manual data entry.
- Control Over Data: You can specifically define what data needs to be extracted.
- Time Efficiency: Web crawlers can save a significant amount of time in the extraction process, making large-scale data gathering feasible.
To ensure we recommend only the most effective best web crawlers, we conducted the following tests:
| Criteria | Details |
|---|---|
| 🎉 Numbers Tested | 10+ web crawlers, including open-source and commercial tools |
| 👀 What We Crawled | E-commerce websites, news portals, social media platforms, and structured databases |
| 😎 What We Valued | Price, crawling speed, anti-detection features, real browser simulation, proxy support, and ease of use |
1. Scrapeless ★★★
Price: From $49/month
Best for: Businesses and developers who need an advanced and efficient solution for large-scale web scraping
Scrapeless is one of the best web crawlers on the market today, offering an all-in-one solution for handling anti-blocking measures while efficiently extracting data from websites.
With Scrapeless, you can scrape data from a wide variety of websites, including e-commerce, market research, and social media platforms. It excels at bypassing CAPTCHA challenges, using real browser simulations for anti-detection, and managing dynamic content that other crawlers often struggle with.
The tool’s anti-blocking technology includes features like a rich proxy IP pool, rapid CAPTCHA unlocking, and TLS fingerprint spoofing, ensuring that your scraping activities are undetected and safe from IP bans. Scrapeless is also known for its ability to scrape data from JavaScript-heavy pages, making it ideal for modern, complex websites. It’s a powerful solution for businesses that need large-scale data extraction without the risk of detection.
More advantages:
- Scrapeless: Starting from $49/month for full access to their web scraping APIs.
- Google SERP API : Google SERP API pricing is as low as $0.3 per 1K queries, which is very affordable for frequent searches. It also covers more than 30 search result types, such as AI results, knowledge graphs, local news, advertising results, Twitter results, etc.
- Google Trends Scraping API: Delivers data in as little as 2 seconds, offering fast access to trends data.
How to Use Scrapeless Scraping API to Scrape Data
Scraping data with Scrapeless is easy and efficient. You can get started by following these steps:
-
Sign upfor an account: Visit the Scrapeless website and sign up for an account.
-
Select the Scraping API for your scenario: You can select the Scraping API you need on the left
Or you can set up an API integration to integrate our tool into your workflow, whether you are using Python, Node.js, or other programming languages. You can refer to the Scrapeless API documentation.
- Set crawling target: Select the website to crawl and configure the required crawling settings. Here we take Google Flights as an example.
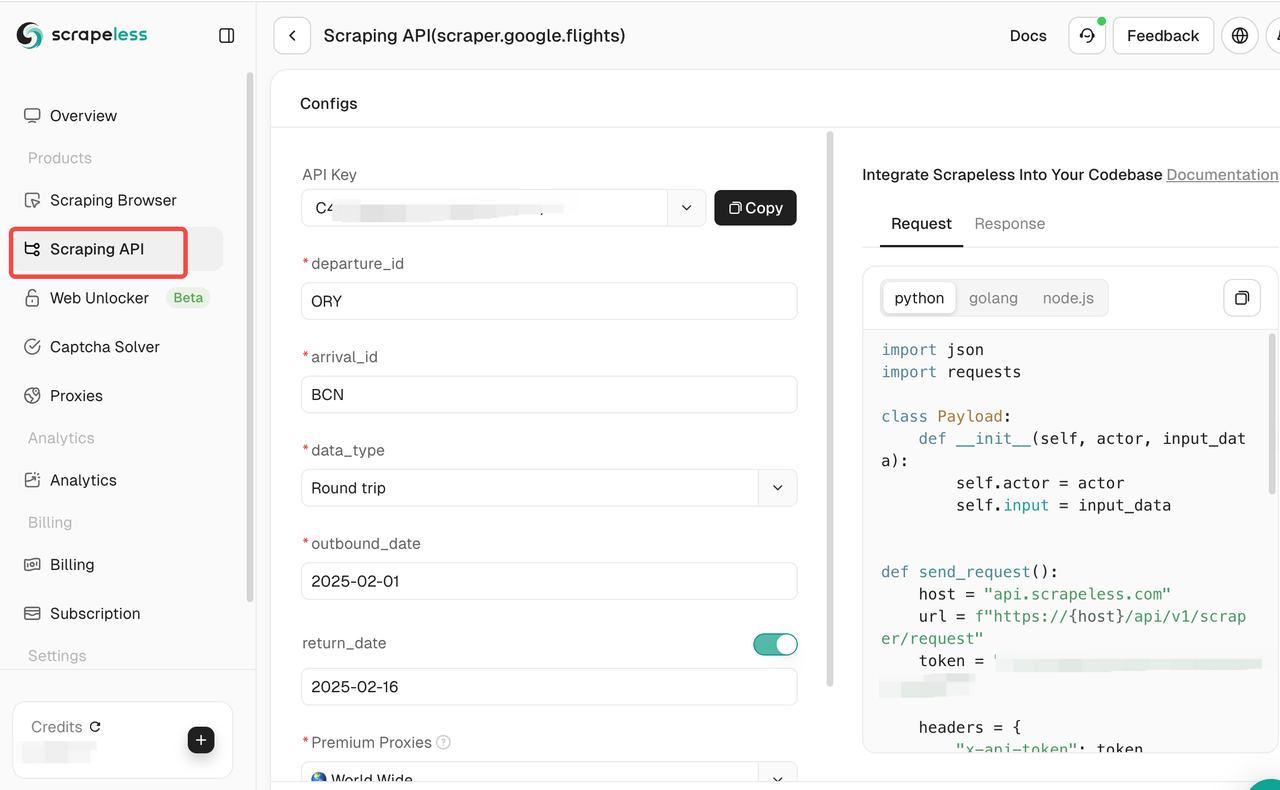
Click Scraping API, then select Google Flight, and set the corresponding scraping requirements.
- Start scraping: Click Start Scraping to start scraping, and the scraping results will appear on the right.
2. WebHarvy
Price: From $129
Best for: Users looking for a simple point-and-click scraping solution
WebHarvy is an easy-to-use web crawler that’s perfect for beginners. Its visual point-and-click interface makes scraping straightforward without needing to write a single line of code. While it doesn’t have the same advanced anti-blocking capabilities as Scrapeless, it’s excellent for scraping product data from e-commerce sites and blogs.
Pros:
- Ease of use: User-friendly interface that doesn't require coding knowledge
- Visual point-and-click scraping: Extracts data without having to learn complex configurations
- Good for e-commerce sites: Great for extracting product listings, images, and prices
Cons:
- Limited anti-blocking features: Vulnerable to scraping restrictions on high-traffic sites
- Limited scalability: Doesn’t perform well for large-scale, high-frequency scraping projects
3. OutWit Hub
Price:Starting at €95
Best for: Beginners who need a simple browser-based scraper
OutWit Hub is a browser extension-based web crawler that allows you to scrape links, emails, images, and more. It’s excellent for beginners and small scraping tasks but may not be the best choice for advanced use cases that require complex scraping or handling JavaScript-heavy pages.
If you have also encountered the JS challenge, you can click to check out this tutorial: How to Bypass Cloudflare Challenge
Pros:
- Browser integration: Simple to install and use directly within your browser
- Easy-to-use interface: Ideal for beginners with no coding experience
- Flexibility: Allows for scraping various data types like links, images, and text
Cons:
- Lacks advanced features: Missing support for handling dynamic content or high-volume scraping
- Limited scalability: Best suited for light scraping rather than large or complex projects
4. ParseHub
Price: Start at $189 per month
Best for: Advanced users needing to scrape dynamic content
ParseHub is an advanced web crawler that excels at scraping JavaScript-heavy websites. It provides a more robust set of features for handling complex sites, but the high price point and complexity may deter less experienced users. It offers a visual interface, but it’s more complex than WebHarvy.
Pros:
- Supports dynamic sites: Excellent for scraping JavaScript-heavy websites
- Visual interface: Allows you to create scraping projects without coding
- Advanced features: Provides options for scheduling and automating scraping tasks
Cons:
- Pricing: Expensive for small-scale or casual users
- Steep learning curve: More advanced features may be overwhelming for beginners
- Slower performance: Not as fast as Scrapeless for large scraping tasks
5. Content Grabber
Price: From $449 to $2495
Best for: Enterprise-level scraping solutions
Content Grabber is a feature-rich web crawler designed for large-scale web scraping tasks, especially for enterprise-level users. It’s great for structured data scraping across multiple websites, but the steep pricing and advanced setup may be overkill for casual users.
Pros:
- Highly customizable: Suitable for scraping large datasets and handling complex workflows
- Advanced features: Supports APIs, proxy rotation, and CAPTCHA solving
- Great for enterprise use: Ideal for high-volume data extraction
Cons:
- High cost: The pricing may be prohibitive for small businesses or individuals
- Complexity: Requires time and effort to learn and set up effectively
- Overkill for small projects: More suited for large-scale operations
FAQ about Web Crawlers
1. What is the Difference Between Web Scraping and Web Crawling
Answer: While both web scraping and web crawling involve extracting information from the web, they serve different purposes. Web crawling is primarily focused on discovering and indexing content across multiple websites. It is used by search engines to map out the structure of the web. On the other hand, web scraping refers to the act of extracting specific data from a website—such as product details, prices, or contact information—using a scraper tool. Scraping is typically more targeted and designed for gathering actionable data, whereas crawling is about collecting and indexing larger sets of data across the web.
2. How does web scraping work?
Answer: Web scraping works by using automated software or scripts (web crawlers) to extract data from websites. The process involves sending requests to a website, retrieving the HTML content, and parsing it to extract useful information such as text, images, links, and more. Advanced crawlers like Scrapeless can handle dynamic websites, bypass anti-scraping measures, and export data in various formats for further analysis.
3. Can I use a web crawler for scraping dynamic websites?
Answer: Yes, many modern web crawlers, including Scrapeless and ParseHub, are designed to handle dynamic websites. These crawlers can render JavaScript and interact with websites as a real browser would, making it possible to scrape data from pages that load content dynamically. Scrapeless, in particular, provides features like anti-detection technology and fast data extraction, ensuring that dynamic content is scraped accurately and efficiently.
Final Thoughts
All in all, choosing the best web crawler for data scraping in 2025 is essential to maximize your efficiency. While tools like WebHarvy, OutWit Hub, and ParseHub are all good options, Scrapeless takes the lead with its user-friendly interface, advanced features, and competitive pricing (only $49 per month). In addition, you can try Scrapeless for free to explore its features.
Don’t miss the opportunity to join the Scrapeless Discord community, join the Scrapeless Discord and contact sales to claim your free trial!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


