Web scraping often faces challenges with anti-bot systems, with TLS fingerprinting being one of the most difficult obstacles to overcome. Websites use this technique to detect and block scrapers by analyzing unique patterns in TLS handshakes.
This article explores two methods for bypassing TLS fingerprinting: The first method involves manually modifying TLS parameters using Burp Suite and the burp-awesome-tls extension. The second method simplifies the process with Scrapeless, an automated solution designed to seamlessly bypass TLS-based detection mechanisms.
What is TLS Fingerprinting?
TLS (Transport Layer Security) secures communication between a client (like a browser or scraper) and a server. When connecting, the client sends a "Client Hello" message with details like TLS versions, cipher suites, and extensions. These form a TLS fingerprint, which websites like those protected by Cloudflare or Akamai use to spot scrapers. For example, a Python scraper using OpenSSL has a different fingerprint than Chrome, making it easy to block.
For Scrapeless users, this means even with proxies or Captcha solutions, mismatched fingerprints can lead to failed requests. Let’s fix that.
Common Methods to Evade TLS Fingerprinting
Several techniques can help bypass TLS fingerprinting:
Modifying TLS configurations: Altering client hello parameters to mimic real browsers.
Using browser-native TLS stacks: Employing real browser TLS implementations instead of automation frameworks.
TLS tunneling and proxies: Routing traffic through intermediaries that present legitimate TLS fingerprints.
Method 1:Using Burp Suite to Modify TLS Fingerprints
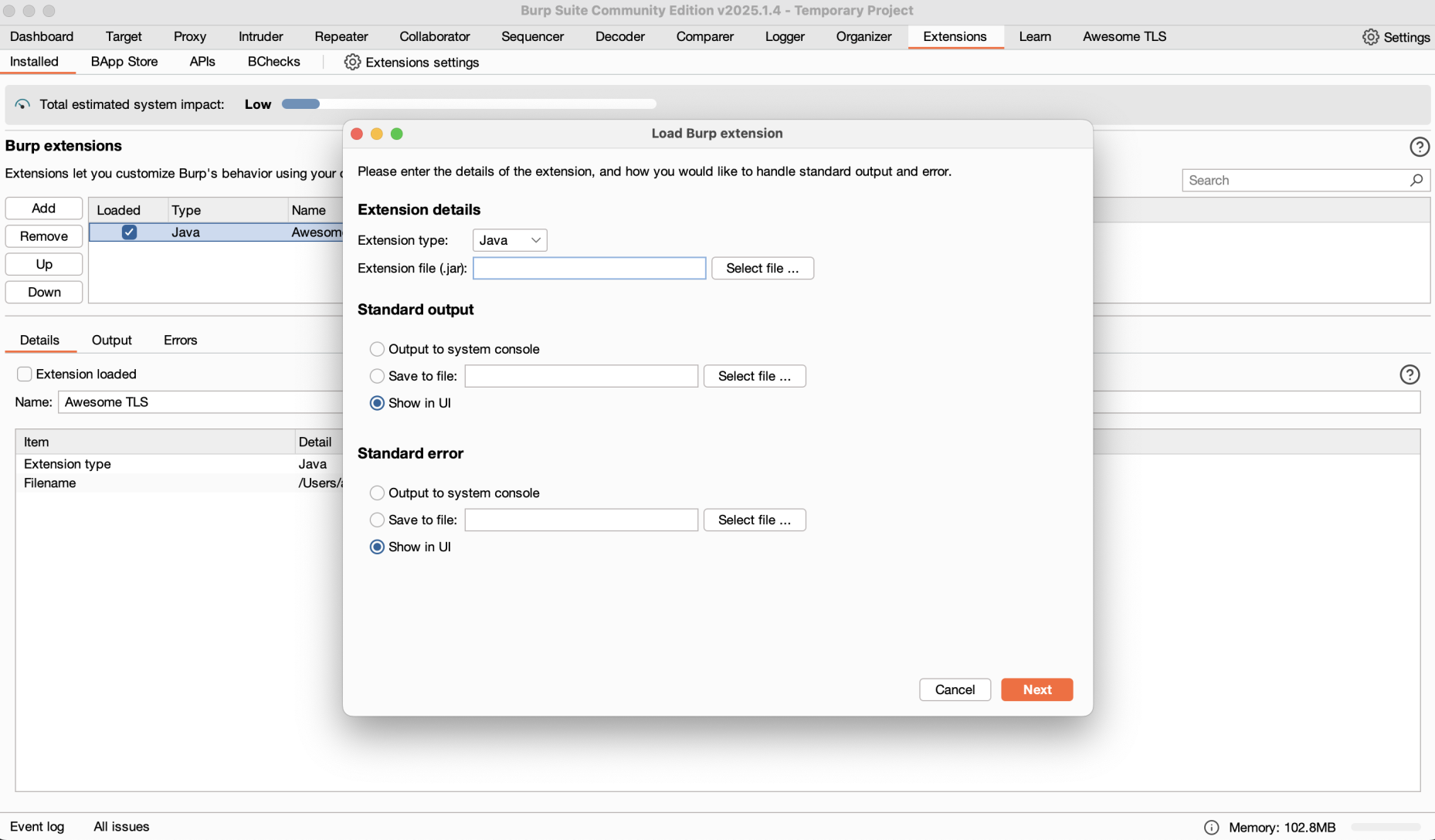
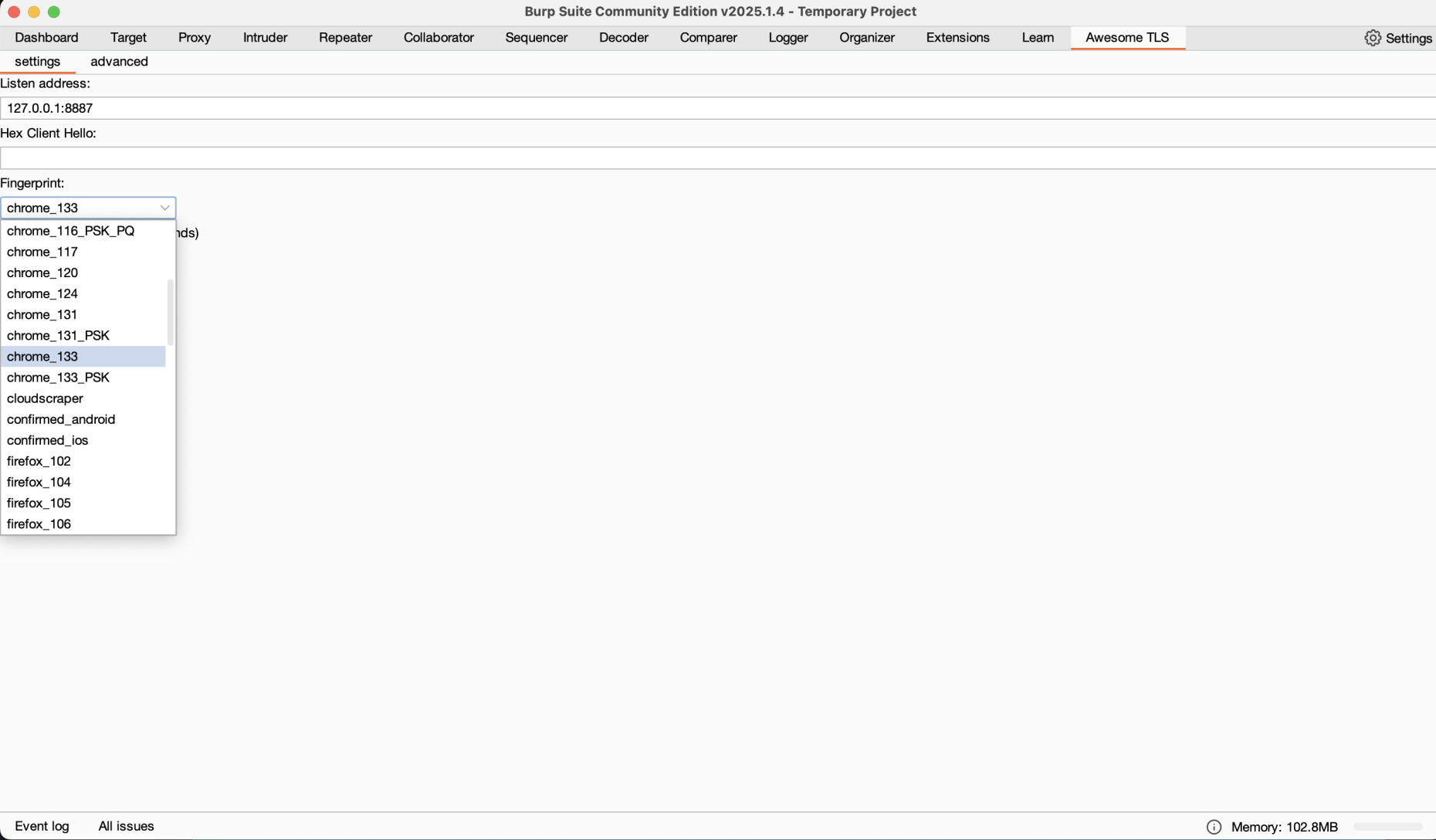
Burp Suite is a versatile proxy tool, originally for security testing, that can intercept and modify web traffic. Paired with the burp-awesome-tls extension, it lets you mimic the TLS fingerprints of browsers like Chrome or Firefox. This tricks anti-bot systems into thinking your scraper is a legitimate user.
Here’s how to configure Burp Suite and burp-awesome-tls to spoof TLS fingerprints. Each step includes a clear screenshot description.
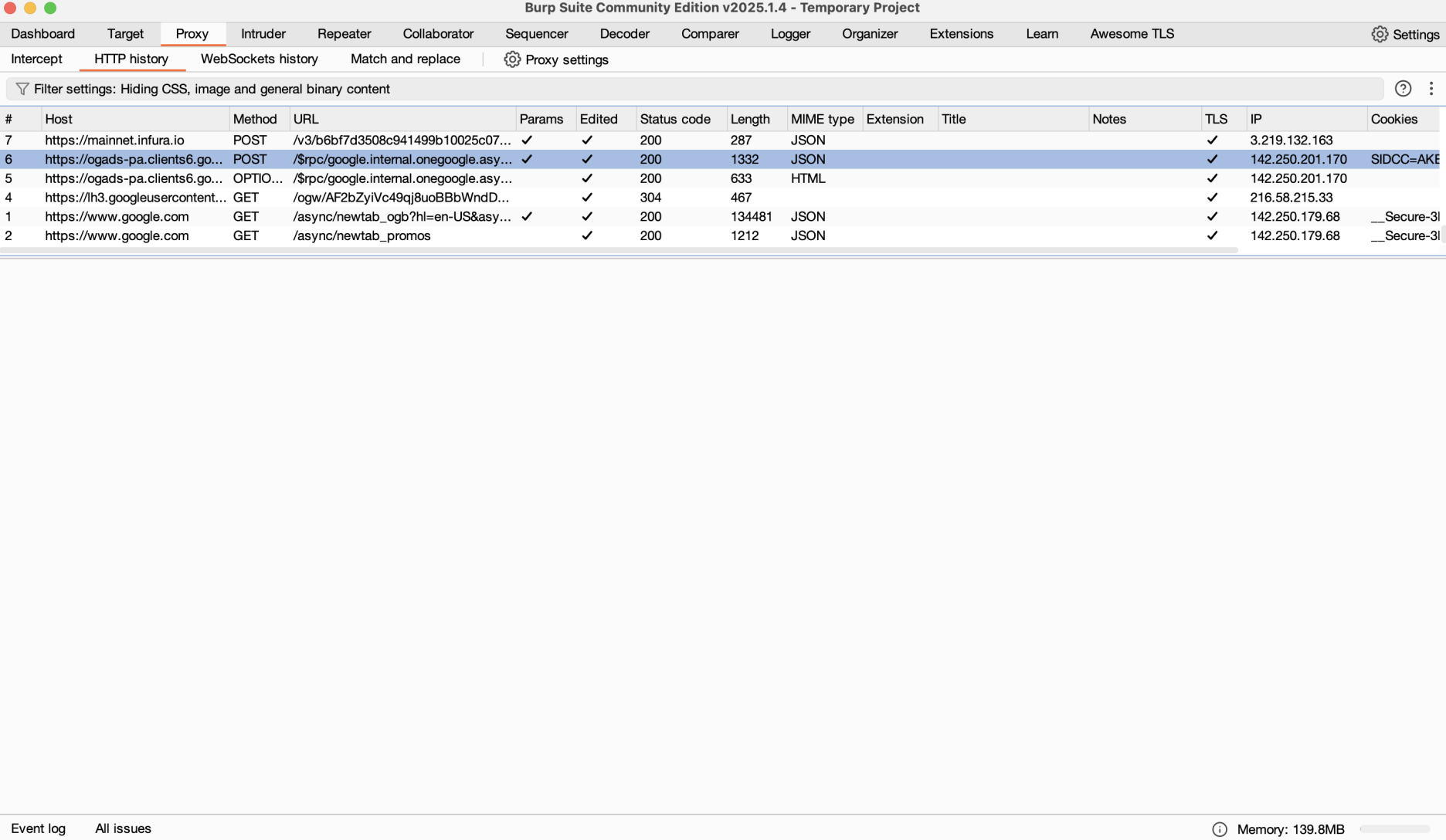
Step 1: Install Burp Suite
Download: Get Burp Suite from the PortSwigger website (Community or Professional).
Install: Follow the setup instructions for your OS.
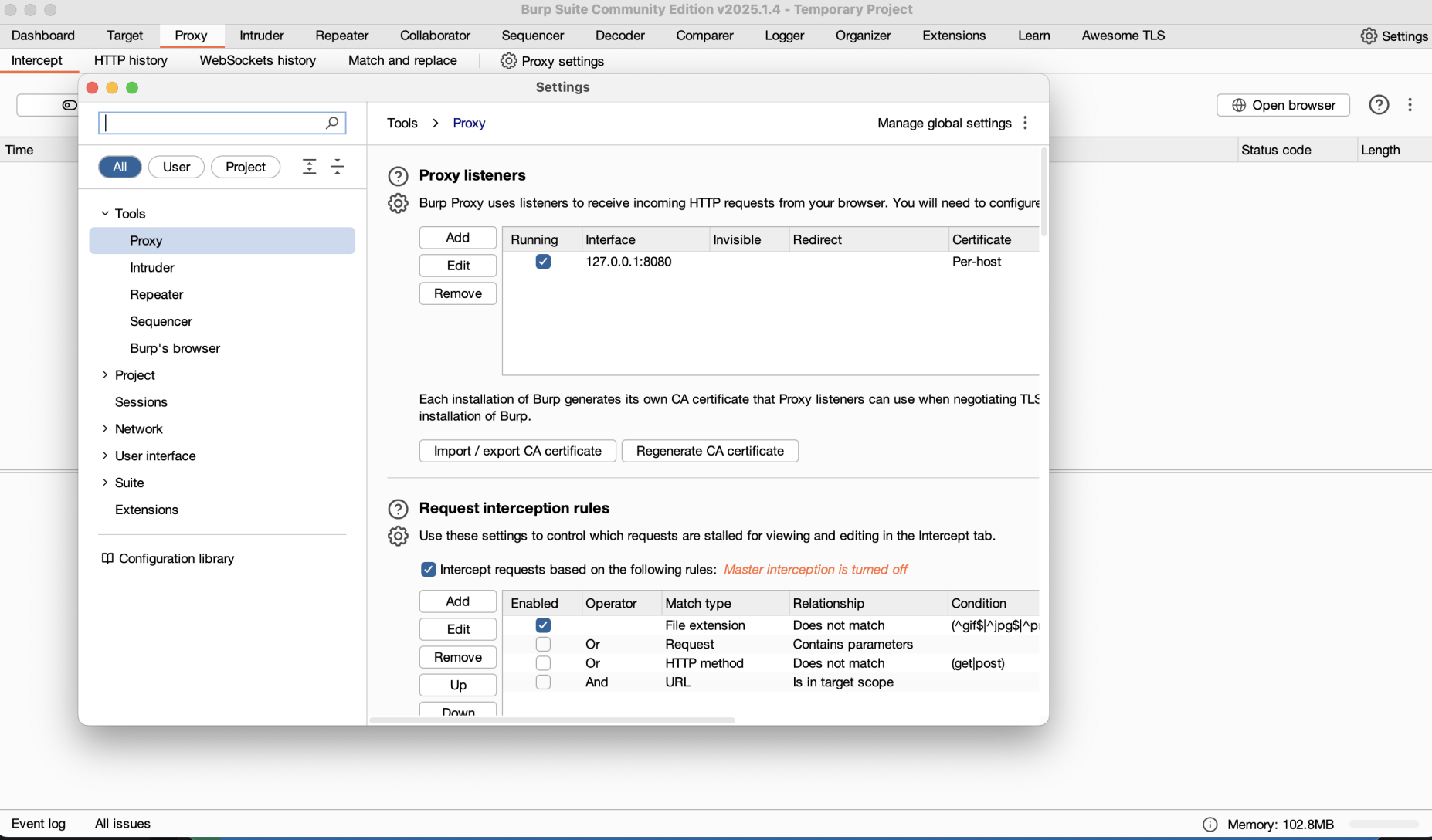
Run It: Execute and watch the request in Burp’s “Proxy” > “HTTP history.”
Verify: Ensure the TLS fingerprint matches your chosen browser.
Method 2: Using Scrapeless for Bypassing TLS Fingerprinting
Scrapeless is a dedicated tool designed to circumvent advanced fingerprinting techniques, including TLS-based detection. Unlike Burp Suite, which requires manual configurations, Scrapeless automates the entire process, ensuring a seamless bypass of fingerprinting mechanisms.
Key Benefits of Scrapeless:
Authentic Browser TLS Fingerprints: Scrapeless emulates real browser TLS handshakes, making it indistinguishable from human traffic.
Automatic Configuration: No need for manual adjustments; Scrapeless handles everything internally.
Stealth Mode: In addition to TLS evasion, it also bypasses other fingerprinting techniques such as JavaScript-based detection.
Scalability: Suitable for large-scale web scraping and penetration testing.
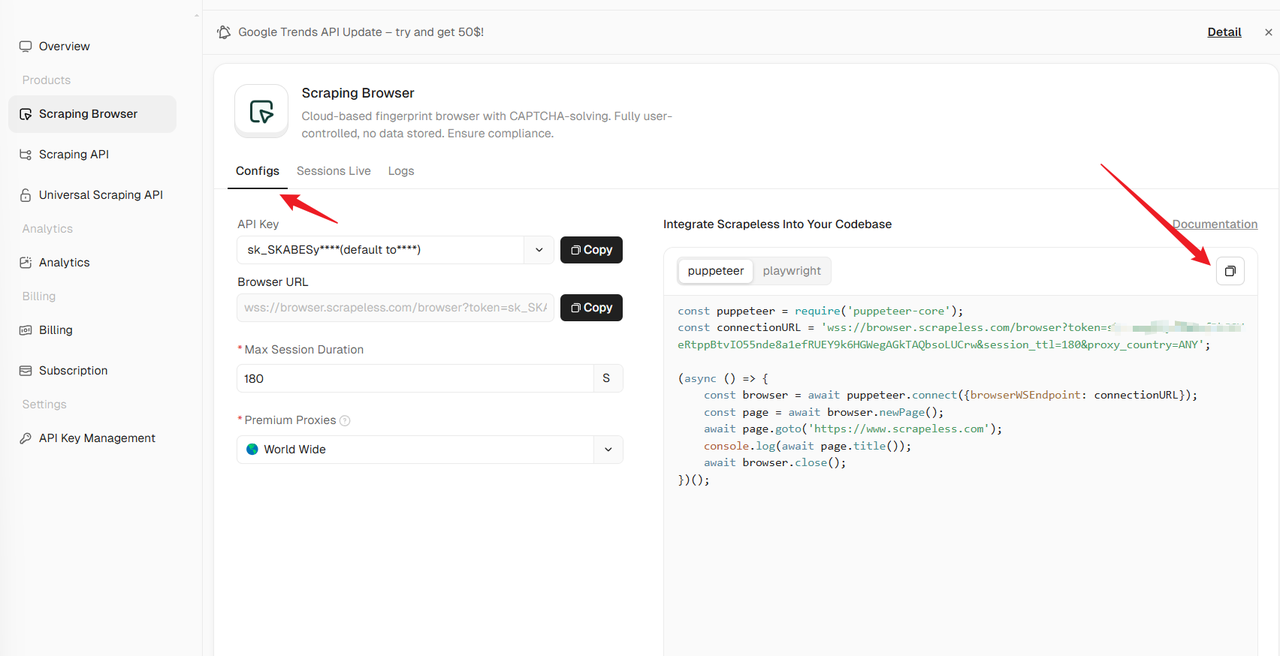
How to Use Scrapeless for Bypassing TLS Fingerprinting
Paste the code into your IDE and customize it based on your scraping requirements (e.g., target URL, data extraction logic).
Run the script to initiate the browser session. Scrapeless will automatically handle TLS fingerprinting bypass by using a real browser environment with randomized fingerprints.
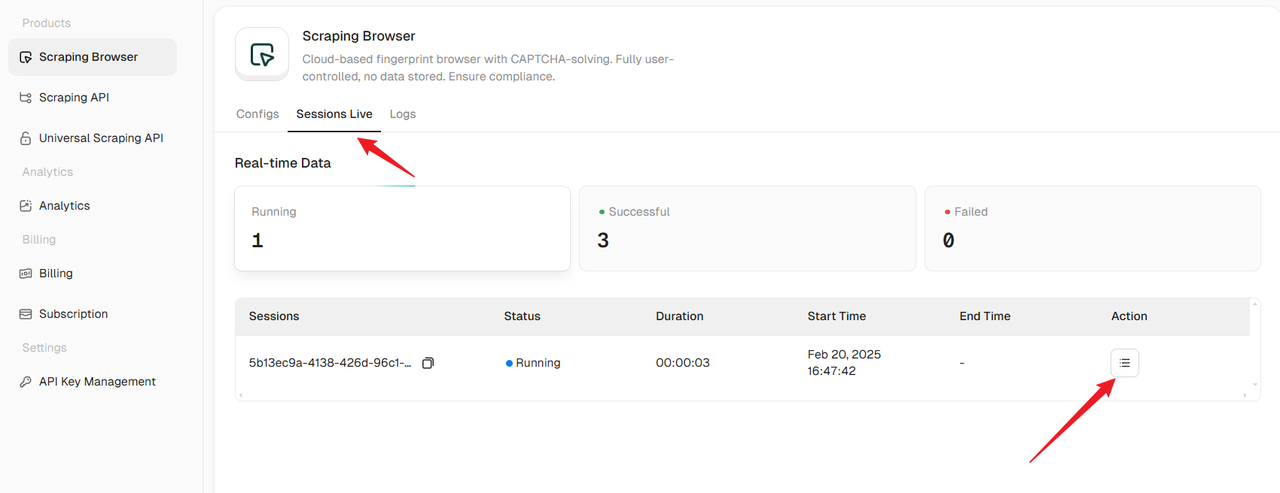
Step 2: Monitor Browser Sessions in Real-Time
Access the Sessions Live Tab
After running the script, go to the Sessions Live tab in the Scrapeless dashboard.
Here, you can see a list of active browser sessions, including their status, IP address, and session duration.
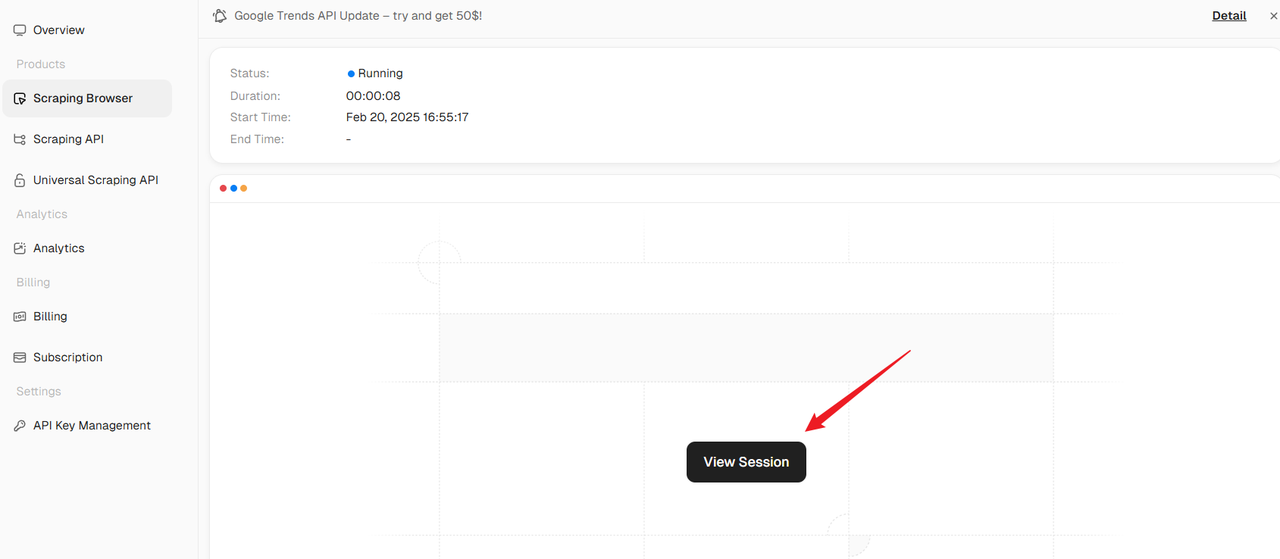
View Session Details
Click the "View Session" button in the Action column to access detailed information about a specific browser session.
You can also preview the browser's real-time activity, which is useful for debugging and ensuring the scraping process is running smoothly.
Step 3: Analyze Logs for Debugging and Optimization
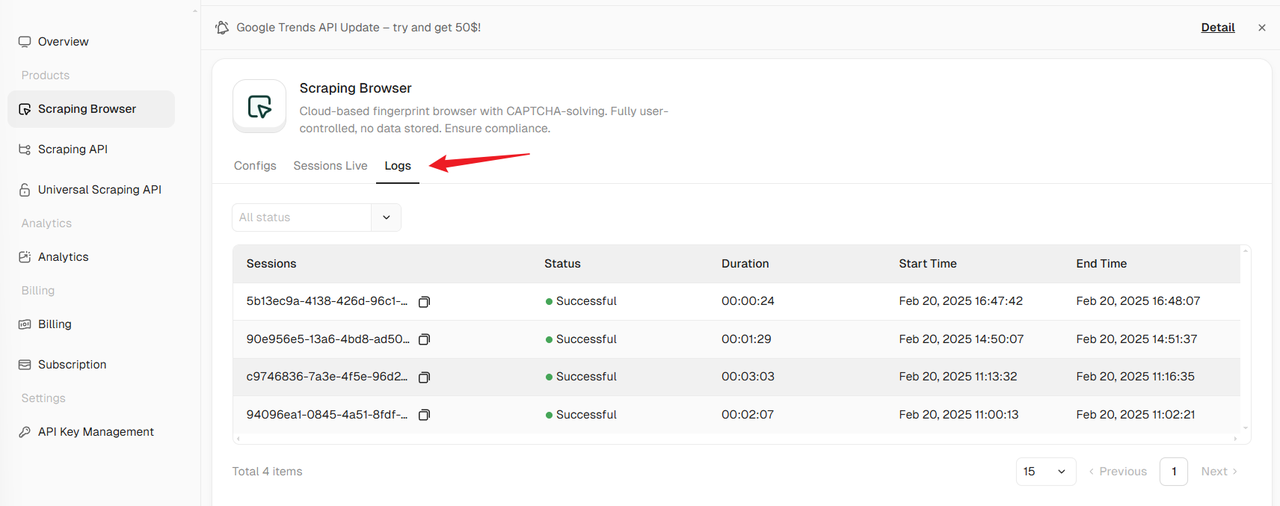
Access the Logs Tab
Navigate to the Logs tab to review historical data from past browser sessions.
Logs include details such as request headers, response codes, and error messages, which are critical for identifying and resolving issues.
Optimize Your Scraping Workflow
Use the logs to analyze patterns, such as frequent IP blocks or TLS fingerprinting detection.
Adjust your script or Scrapeless settings (e.g., increase session_ttl, rotate proxies more frequently) to improve success rates.
🔹 Try Scrapeless now to make your web crawling more efficient and more hidden!
➡️ Click here to get Scrapeless, easily bypass TLS fingerprint detection, and improve the success rate of crawling and penetration testing!
Key Tips for Bypassing TLS Fingerprinting with Scrapeless
Use Randomized Browser Fingerprints: Scrapeless automatically rotates browser fingerprints, including TLS handshake parameters, to avoid detection.
Leverage Global Proxies: Set proxy=WorldWide to distribute requests across multiple IPs, reducing the risk of being flagged.
Monitor Session Health: Regularly check the Sessions Live tab to ensure your browser sessions are running as expected.
Scrapeless prioritizes ethical scraping:
Follow robots.txt: Respect site rules.
Rate Limit: Don’t overload servers.
Privacy: Comply with GDPR, CCPA, etc.
Use these tools responsibly to scrape confidently.
Wrap-Up
Bypassing TLS fingerprinting is crucial for penetration testers, security researchers, and web scrapers. While Burp Suite and burp-awesome-tls offer a degree of control, Scrapeless provides a more reliable and automated solution. With its ability to mimic real browser TLS stacks seamlessly, Scrapeless stands out as the best choice for evading TLS-based detection mechanisms.
If you're looking for an efficient and scalable way to bypass TLS fingerprinting with minimal setup, try Scrapeless today and enhance your web scraping or security testing workflow! Visit the official Scrapeless website to get started.
Note: This guide has been thoroughly tested by our team at the time of writing. However, since websites frequently update their code and structure, some steps may no longer work as expected. We only scrape publicly available data and strictly prohibit scraping personal information, login-restricted data, or engaging in any actions that violate website terms of service. Please ensure that your data collection practices comply with legal regulations and website policies.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.