
How to Scrape Google Finance Ticker Quote Data in Python
Advanced Data Extraction Specialist
In the fast-paced world of finance, access to up-to-date and accurate stock market data is essential for investors, traders, and analysts. Google Finance is an invaluable resource that provides real-time stock quotes, historical financial data, news, and currency rates. Learning how to scrape this data using Python can be of great benefit to those looking to aggregate data, perform sentiment analysis, make market forecasts, or effectively manage risk.
Why Scrape Google Finance?
Scraping Google Finance can be beneficial for various reasons, including:
- Real-Time Stock Data – Access up-to-date stock prices, market trends, and historical performance.
- Automated Market Analysis – Collect financial data at scale for trend analysis, portfolio management, or algorithmic trading.
- Company Insights – Gather financial summaries, earnings reports, and stock performance for investment research.
- Competitor & Industry Research – Monitor competitors’ financial health and industry trends to make data-driven decisions.
- News & Sentiment Analysis – Extract news articles and updates related to specific stocks or industries for sentiment tracking.
What will be scraped
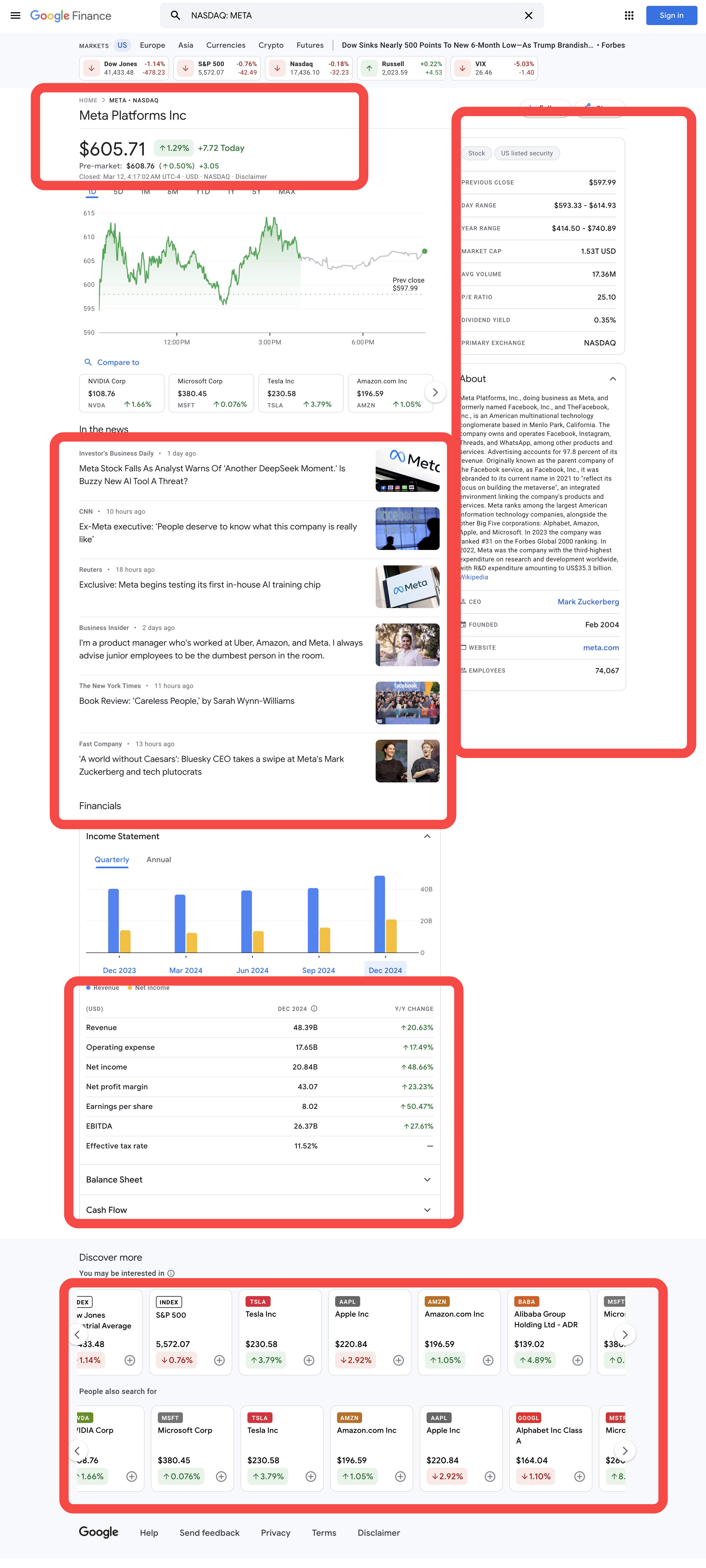
How to Scrape Google Finance Ticker Quote Data in Python
Step 1. Configure the environment
-
Python: The software is the core of running Python. You can download the version we need from the official website as shown below. However, it is not recommended to download the latest version. You can download 1.2 versions before the latest version.
-
Python IDE: Any IDE that supports Python will work, but we recommend PyCharm. It is a development tool specifically designed for Python. For the PyCharm version, we recommend the free PyCharm Community Edition
Note: If you are a Windows user, do not forget to check the "Add python.exe to PATH" option during the installation wizard. This will allow Windows to use Python and commands in the terminal. Since Python 3.4 or later includes it by default, you do not need to install it manually.
Now you can check if Python is installed by opening the terminal or command prompt and entering the following command:
python --versionStep 2. Install Dependencies
It is recommended to create a virtual environment to manage project dependencies and avoid conflicts with other Python projects. Navigate to the project directory in the terminal and execute the following command to create a virtual environment named google_lens:
python -m venv google_financeActivate the virtual environment based on your system:
- Windows:
language
google_finance_env\Scripts\activate- MacOS/Linux:
language
source google_finance_env/bin/activateAfter activating the virtual environment, install the required Python libraries for web scraping. The library for sending requests in Python is requests, and the main library for scraping data is BeautifulSoup4. Install them using the following commands:
language
pip install requests
pip install beautifulsoup4
pip install playwrightStep 3. Scrape Data
To extract stock information from Google Finance, we first need to understand how to use the website's URL to scrape the desired stock. Let's take the Nasdaq index as an example, which contains multiple stocks that we can get information from. To access the symbol of each stock, we can use the Nasdaq stock filter from this link. Now let's target META as our target stock. With the index and stock in hand, we can build the first snippet of the script.
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
language
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"Now we can use the Requests library to make an HTTP request on TARGET_URL and create a Beautiful Soup instance to scrape the HTML content.
language
make an HTTP request
page = requests.get(TARGET_URL)# use an HTML parser to grab the content from "page"
soup = BeautifulSoup(page.content, "html.parser")Before we start crawling, we first need to process the HTML element (TARGET_URL) by inspecting the web page.
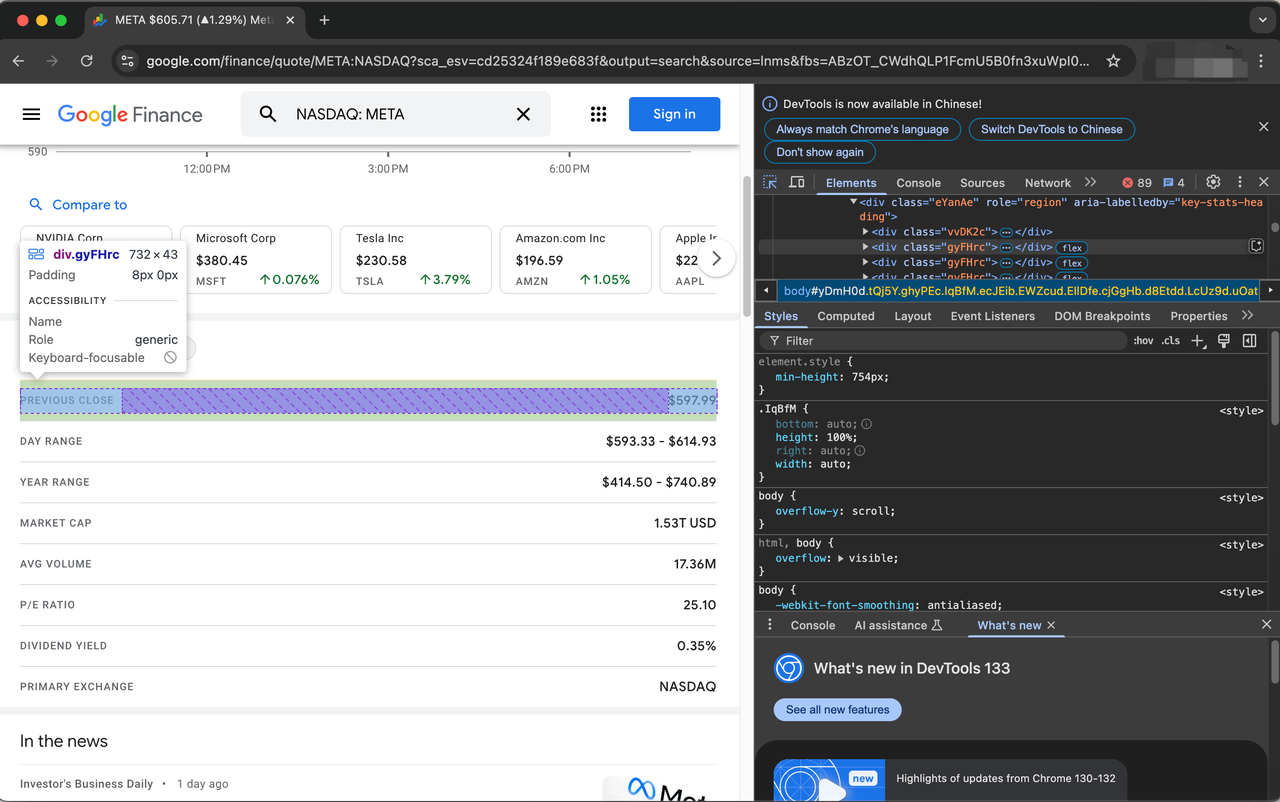
Items describing stocks are represented by the class gyFHrc. Inside each such element, there is a class that represents the item's title (e.g. "Last Closing Price") and the corresponding value (e.g. $597.99). The title can be obtained from the mfs7Fc class, while the value comes from the P6K39c class.
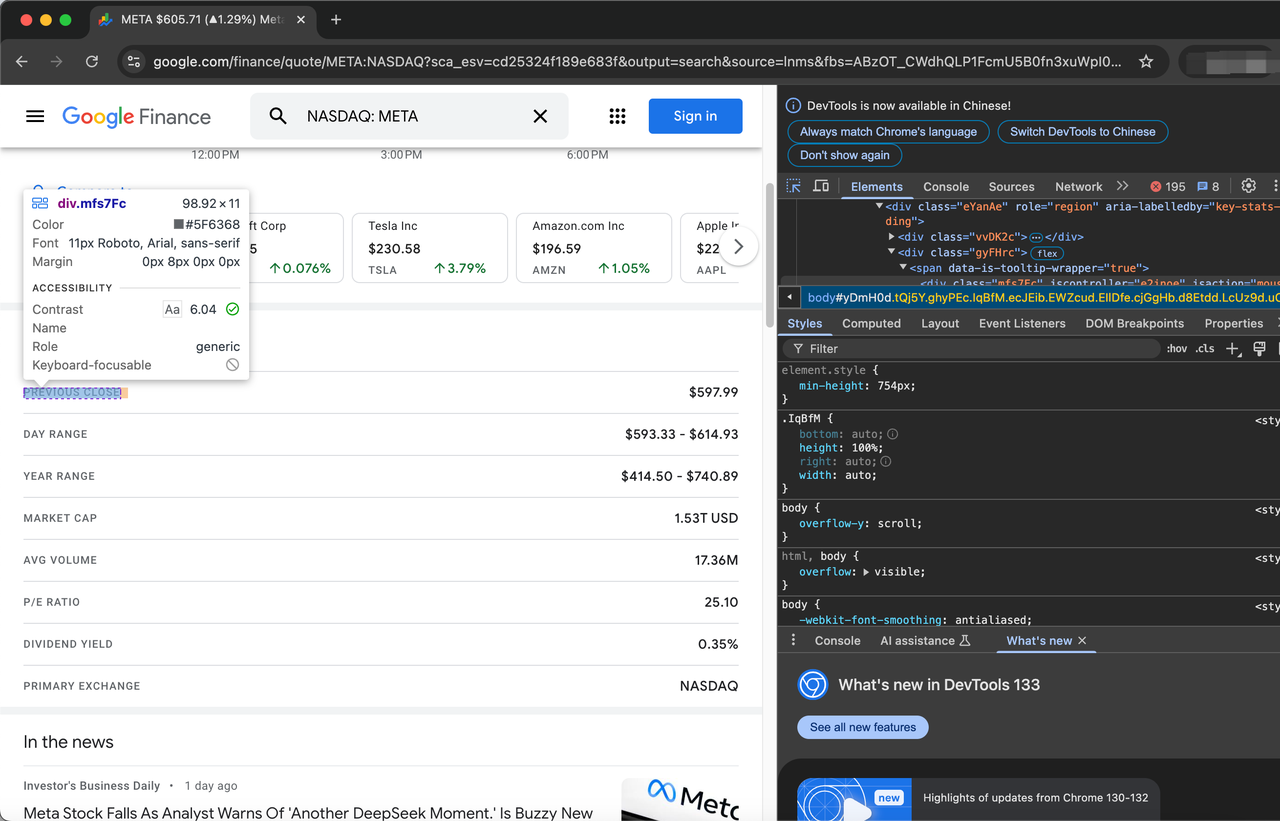
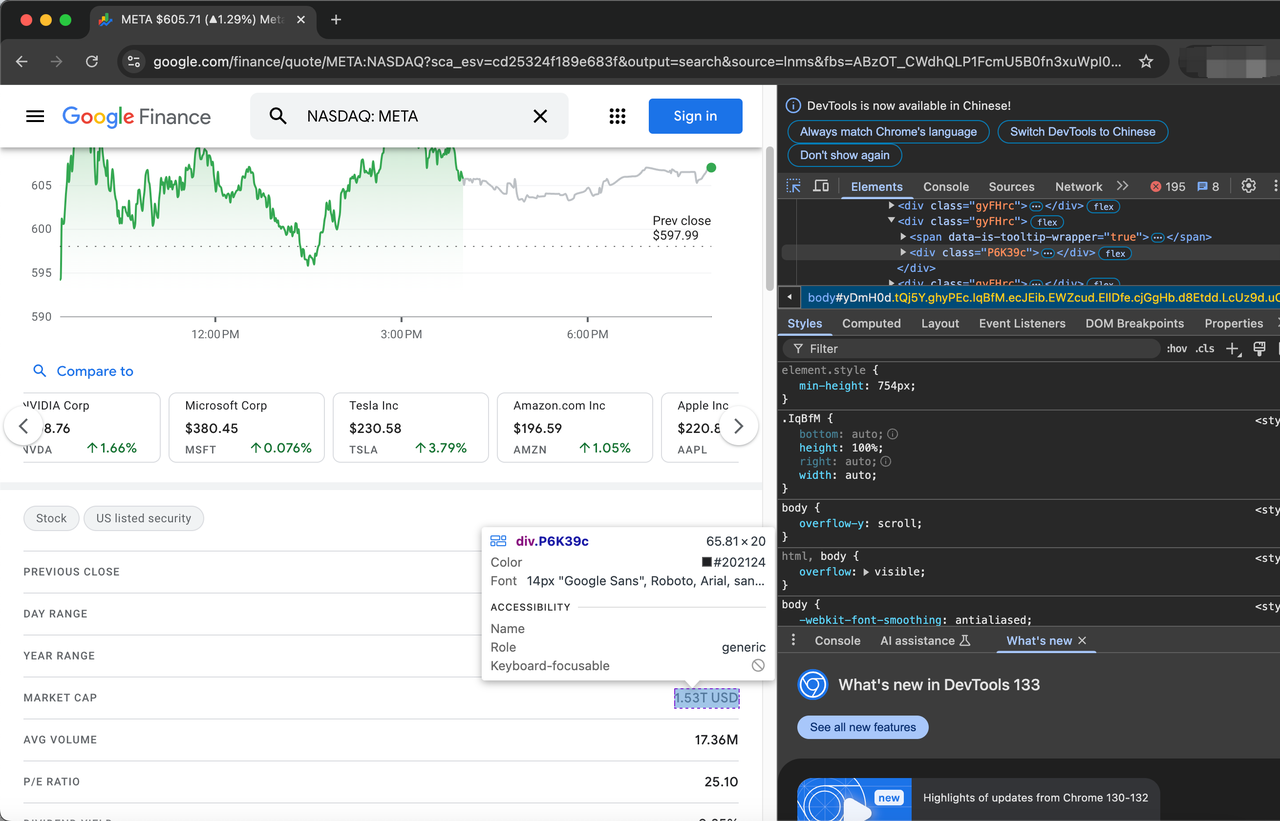
The complete list of items to be crawled is as follows:
- Previous Close
- Day Range
- Year Range
- Market Cap
- AVG Volume
- P/E Ratio
- Dividend Yield
- Primary Exchange
- CEO
- Founded
- Website
- Employees
Now let's see how to fetch these items using Python code.
# get the items that describe the stock
items = soup.find_all("div", {"class": "gyFHrc"})
# create a dictionary to store the stock description
stock_description = {}
# iterate over the items and append them to the dictionary
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_value
print(stock_description)This is just an example of a simple script that can be integrated into a trading bot, application, or a simple dashboard to track your favorite stocks.
Full Code
There are many more data attributes you can grab from the page, but for now, the full code looks a little like this.
language
import requests
from bs4 import BeautifulSoup
BASE_URL = "https://www.google.com/finance"
INDEX = "NASDAQ"
SYMBOL = "META"
LANGUAGE = "en"
TARGET_URL = f"{BASE_URL}/quote/{SYMBOL}:{INDEX}?hl={LANGUAGE}"# make an HTTP request
page = requests.get(TARGET_URL)# use an HTML parser to grab the content from "page"
soup = BeautifulSoup(page.content, "html.parser")# get the items that describe the stock
items = soup.find_all("div", {"class": "gyFHrc"})# create a dictionary to store the stock description
stock_description = {}# iterate over the items and append them to the dictionaryfor item in items:
for item in items:
item_description = item.find("div", {"class": "mfs7Fc"}).text
item_value = item.find("div", {"class": "P6K39c"}).text
stock_description[item_description] = item_valueThe following are some examples of the results:

Limitations when scraping Google Finance
Using the above method, you can create a small scraper, but if you are going to do large-scale scraping, this scraper will not continue to provide you with data. Google is very sensitive about data scraping and will eventually block your IP.
Once your IP is blocked, you will not be able to scrape anything and your data pipeline will eventually break. So, how to overcome this problem? There is a very simple solution and that is to use the Google Finance Scraping API.
Let's see how to scrape unlimited data from Google Finance using this API.
Why use Scrapeless Google Finance Scraping API
Data quality and accuracy
- High-precision data: Scrapeless SerpApi always provides accurate, reliable and up-to-date Google Finance data, ensuring that users can obtain the most authentic and useful market information.
- Real-time updates: Being able to obtain the latest data on Google Finance in real time, including real-time stock quotes, market trends, etc., is essential for users who need to make timely investment decisions.
Multi-language and location support
- Multi-language support: Supports multiple languages, and users can obtain financial data in different languages according to their needs to meet the needs of users in different regions around the world.
- Location customization: You can obtain customized search results based on specified geographic locations, device types and other parameters, which is very useful for analyzing market conditions in different regions or conducting localized market research.
Performance and cost advantages
- Super fast speed: With an average response time of only 1-2 seconds, Scrapeless SerpApi is one of the fastest search crawling APIs on the market, which can quickly provide users with the required data.
- Cost-effective: Scrapeless SerpApi provides Google Search APIs at only $0.1 per thousand queries. This pricing model is very cost-effective for large-scale data scraping projects.
Integration - Easy integration: Scrapeless SerpApi supports integration with a variety of popular programming languages (such as Python, Node.js, Golang, etc.), and users can easily embed it into their own applications or analysis tools.
Stability and reliability - High availability: Scrapeless SerpApi has high service availability and stability, which can ensure uninterrupted service to users during long-term and high-frequency data scraping.
- Professional support: Scrapeless SerpApi provides professional technical support and customer service to help users solve problems encountered during use and ensure that users can smoothly obtain and use data.
How to Scrape Google Finance data with Scrapeless
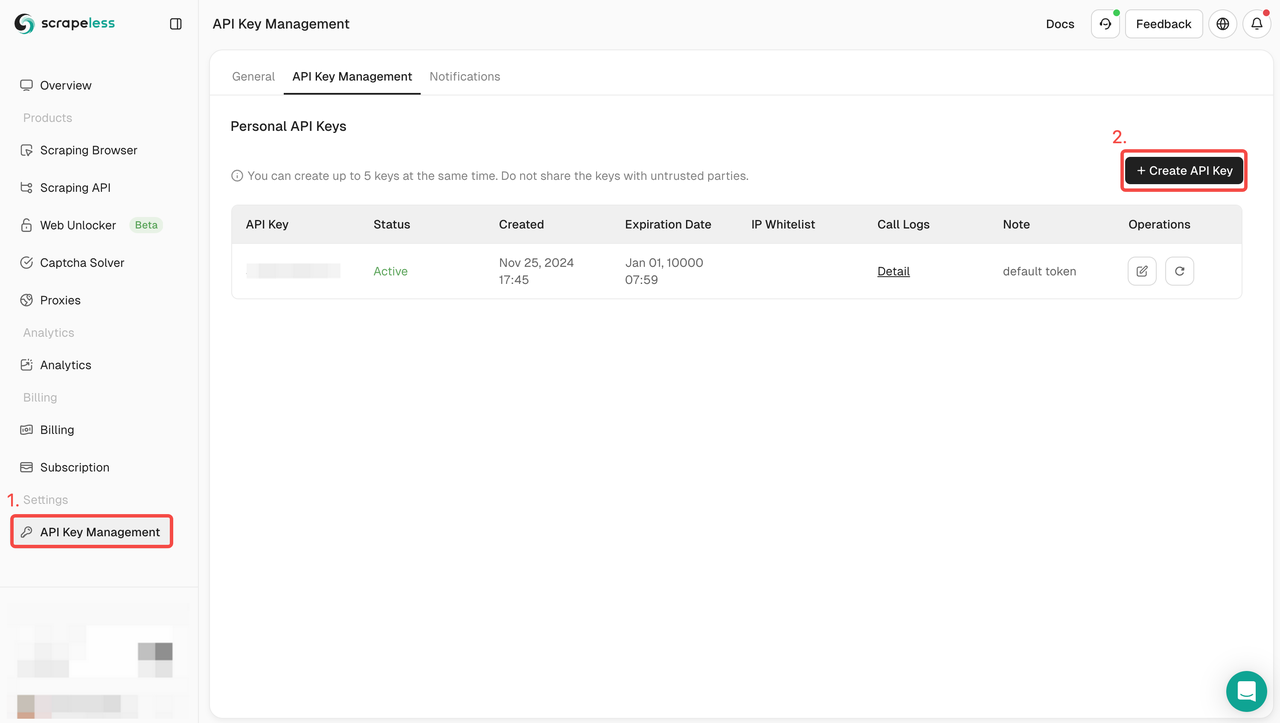
Step 1: Sign up for Scrapeless and get an API key
- If you don't have a Scrapeless account yet, visit the Scrapeless website and sign up. You can get 20,000 free search queries.
- Once signed up, log in to your dashboard.
- In the dashboard, navigate to API Key Management and click Create API Key. Copy the generated API key, which will be your authentication credential when calling the Scrapeless API.
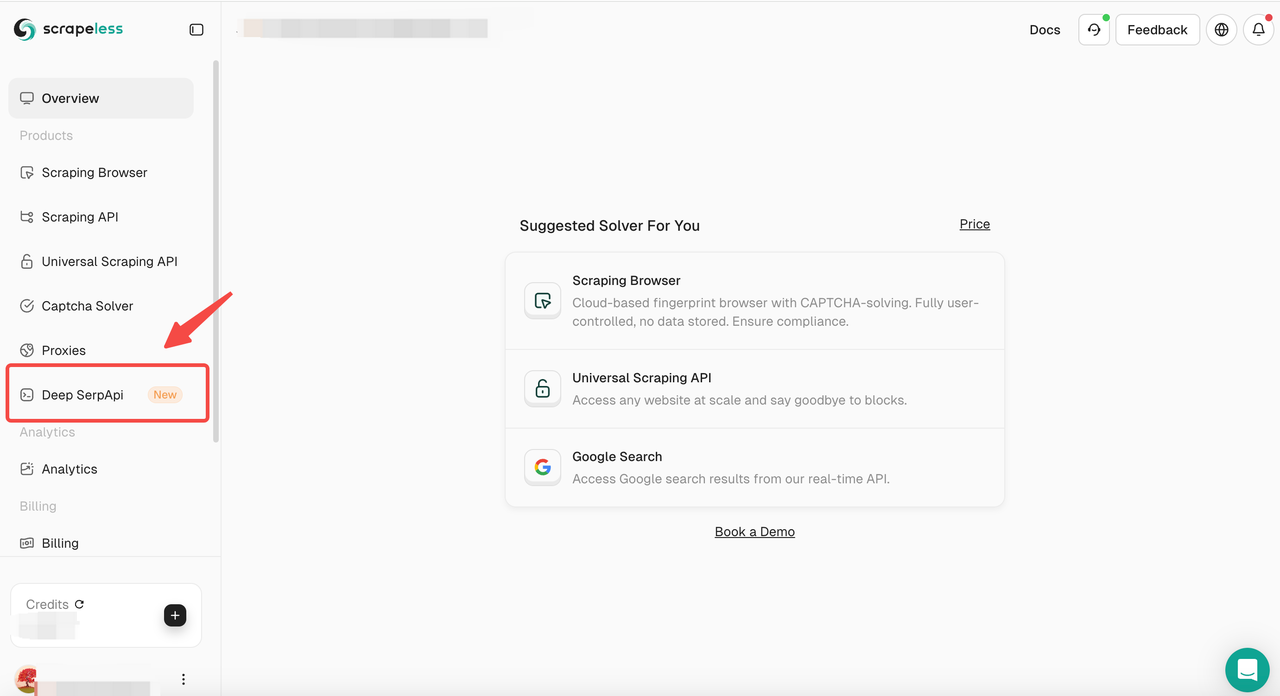
Step 2: Access the Deep SerpApi Playground
- Then navigate to the "Deep SerpApi" section.
Step 3: Set search parameters
- In the Playground, enter your search keyword, such as "GOOGL:NASDAQ".
- Set other parameters, such as Query term, language, time etc.
You can also click to view the official API documentation of Scrapeless to learn about the parameters of Google Finance.
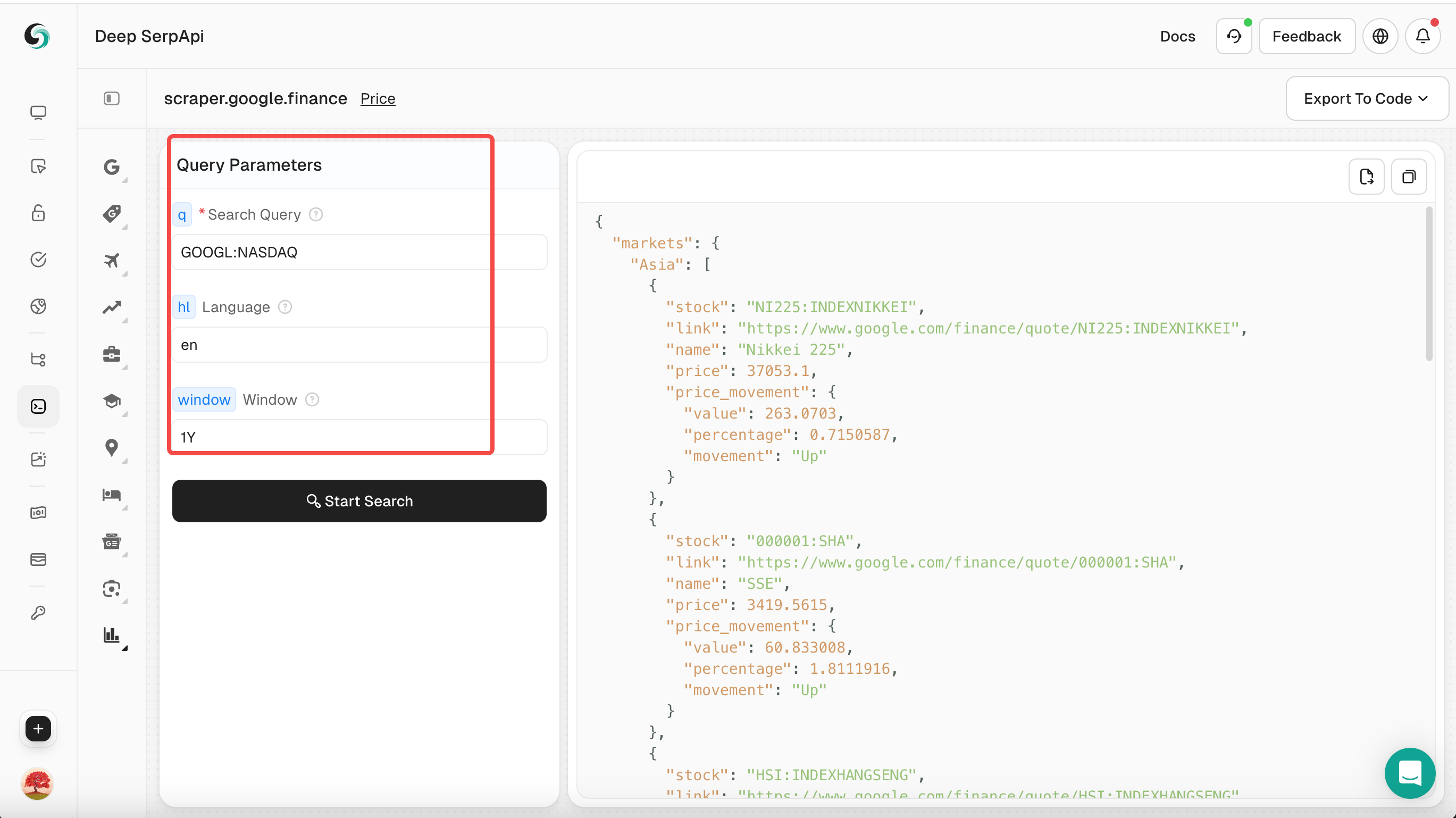
Step 4: Perform a search
- Click the "Start Search" button, and the Playground will send a request to the Deep Serp API and return structured JSON data.
Step 5: View and export data
- Browse the returned JSON data to view detailed information.
- If necessary, you can click "Copy" in the upper right corner to export the data to CSV or JSON format for further analysis.
Free developer support:
Integrate Scrapeless Deep SerpApi into your AI tool, application or project (we already support Dify, and will support Langchain, Langflow, FlowiseAI and other frameworks in the future).
Share your integration results on social media and you will get 1 to 12 months of free developer support, up to 500K usage per month.
Seize this opportunity to improve your project and enjoy more development support! You can also contact Liam via Discord for more details.
How to integrate the Scrapeless API
Here is the sample code for scraping Google Finance results using the Scrapeless API:
language
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your api key"
headers = {
"x-api-token": token
}
input_data = {
"q": "GOOG:NASDAQ",
"window": "MAX",
.....
}
payload = Payload("scraper.google.finance", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Adjust the query parameters as needed to get more precise results. For more information on API parameters, you can check out the Scrapeless official API documentation
You must replace YOUR-API-KEY with the API key you copied.
Additional Resources
How to Scrape Google News with Python
How to Bypass Cloudflare With Puppeteer
How to Scrape Google Lens Results with Scrapeless
Conclusion
In conclusion, scraping Google Finance ticker quote data in Python is a powerful technique for accessing real-time financial information. By utilizing libraries like requests and BeautifulSoup, or more advanced tools like Selenium, you can efficiently extract and analyze market data to inform your investment decisions. Remember to respect website terms of service and consider using official APIs when available for sustainable data access.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


