
Scrape Google Jobs to easily make Job Lists using Scrapeless
Advanced Data Extraction Specialist
Finding the right job data quickly can be a challenge, but with the right tools, it becomes effortless. Scraping job listings from Google Jobs can help businesses, job boards, and developers gather accurate, up-to-date job information. By automating the process, you can easily compile comprehensive job lists, filter by location or job type, and integrate this data into your platform. In this article, we’ll show you how to scrape Google Jobs efficiently and create job lists that are both relevant and accurate.
What is Google Jobs?
Google Jobs is a specialized job search engine provided by Google that aggregates job listings from a variety of sources, including job boards, company websites, and staffing agencies. Launched in 2017, Google Jobs aims to simplify the job search process by offering a one-stop platform for users to discover job opportunities across different industries and locations.
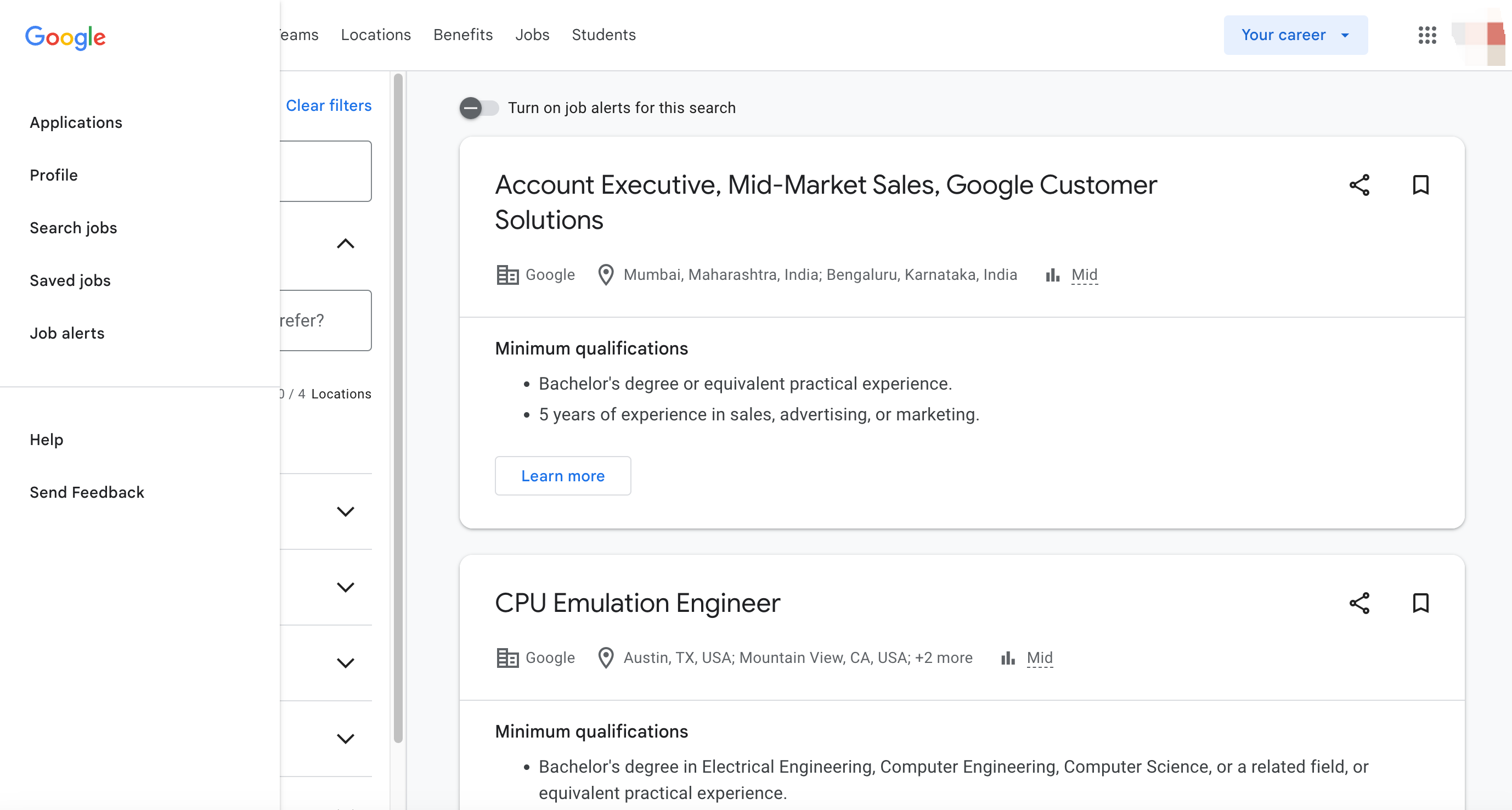
Why Scrape Google Jobs?
Scraping Google Jobs offers several advantages for businesses, job seekers, and job boards alike. Here are some of the key reasons why you should consider scraping Google Jobs data:
1. Comprehensive Job Listings
Google Jobs aggregates job listings from multiple trusted sources, making it a one-stop shop for job data.
2. Customizable Search
You can filter job results based on specific criteria like location, job title, and salary range, which gives you tailored results for your audience.
3. Time-Saving Automation
By automating the scraping of Google Jobs, you can ensure that your website or app always has up-to-date job listings, eliminating the need for manual updates.
4. Competitive Edge
If you're running a job board or a recruitment website, having access to Google Jobs data can provide a competitive edge by offering comprehensive job listings that attract job seekers.
Scrape Google Jobs to Easily Make Job Lists Using Python
Finding the right jobs can be a daunting task, but with Scrapeless, you can quickly and efficiently collect job postings from Google Jobs and integrate them into your own tools. In this article, we'll walk you through how to use the Scrapeless API to scrape job data and create your own job listings.
Scrapeless is a powerful and easy-to-use web scraping tool that allows you to collect structured data from a variety of sources, including Google Jobs, without having to handle the complexities of scraping on your own.-

Advantages of Scrapeless
-
Accurate and comprehensive data: Provides accurate job information, covering key content such as job title, company name, work location, salary range, job description, etc.
-
Supports multi-parameter customization: Allows developers to use more than 10 customized parameters, such as job type (full-time, part-time, etc.), experience requirements, industry field, etc., to accurately filter target job data.
-
Multi-region coverage: Can capture Google Jobs search results in different countries and regions to meet global business expansion needs.
-
Format specification: Output data in standardized JSON format, which is convenient for developers to integrate and process in different systems and programs.
-
Easy to integrate: Provides a simple API interface, which is convenient for developers to call and integrate using common programming languages (such as Python, Java, etc.).
-
Real-time update: Ensure that the obtained job data is real-time and reflects the latest recruitment information in a timely manner.
Sign up now and receive $2 in free credits to try out all our powerful features. Don’t miss out
Step 1: Build a Google Job data crawling environment
First, we need to build a data crawling environment and prepare the following tools:
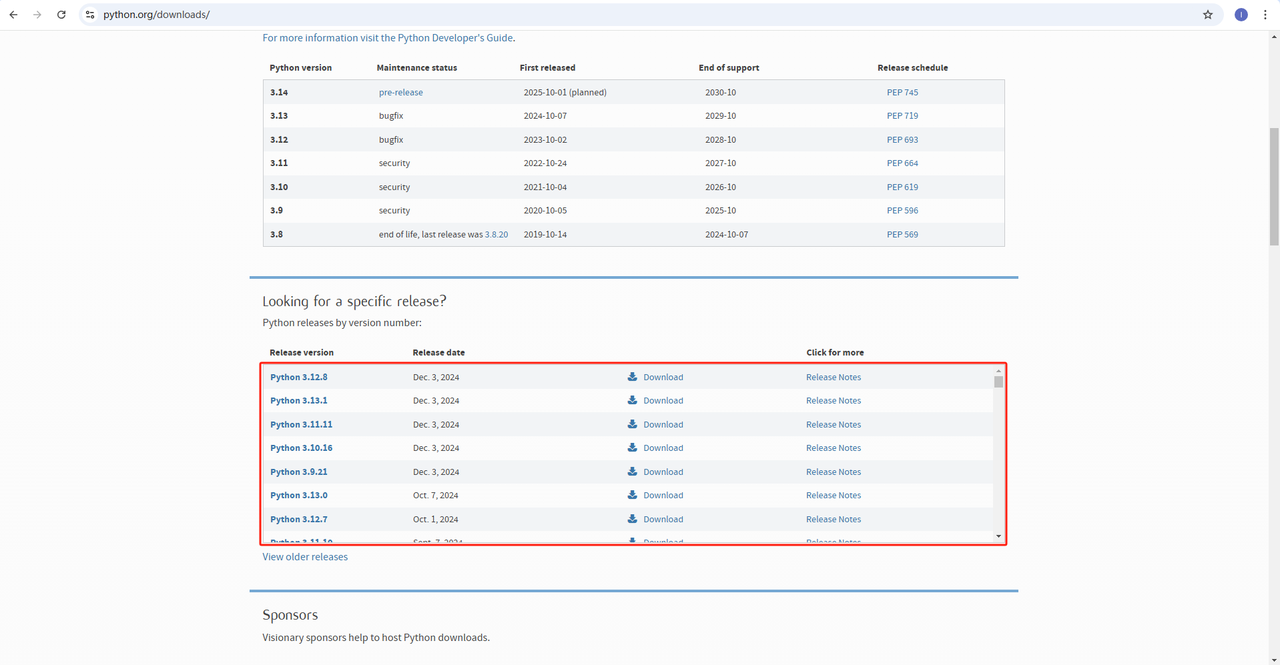
1. Python: This is the core software for running Python. You can download the version we need from the official website link, as shown in the figure below, but it is recommended not to download the latest version. You can download 1-2 versions before the latest version.
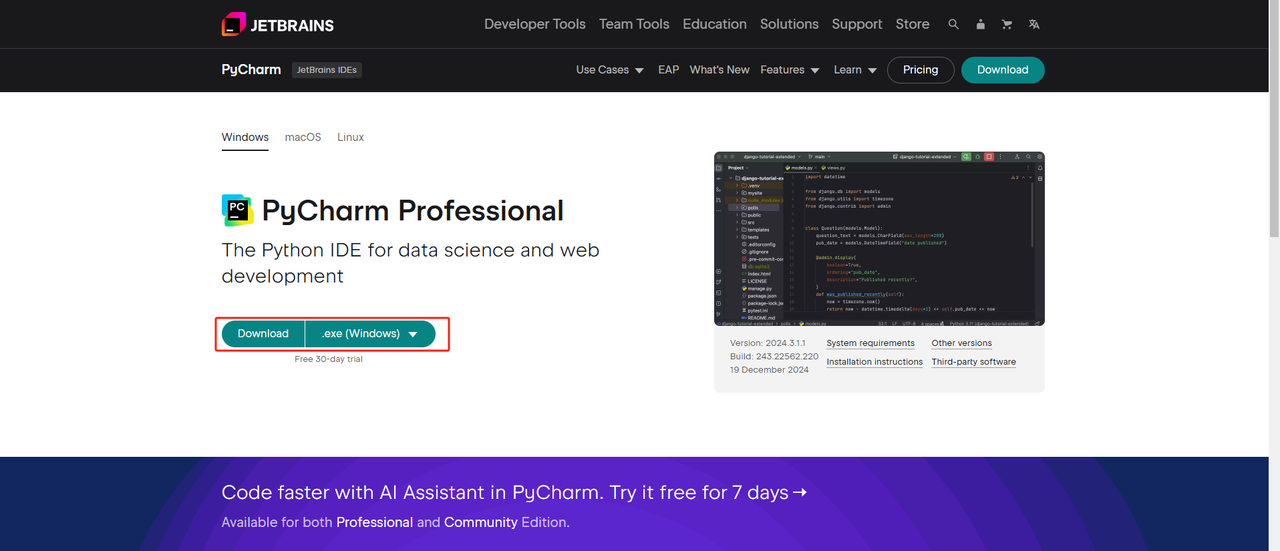
2. Python IDE: Any IDE that supports Python will do, but we recommend PyCharm, which is an IDE development tool software designed specifically for Python. Regarding the PyCharm version, we recommend the free PyCharm Community Edition.
3. Pip: You can use the Python Package Index to install the libraries you need to run your programs with a single command.
Note: If you are a Windows user, don't forget to check the "Add python.exe to PATH" option in the installation wizard. This will allow Windows to use Python and commands in the terminal. Since Python 3.4 or later includes it by default, you don't need to install it manually.
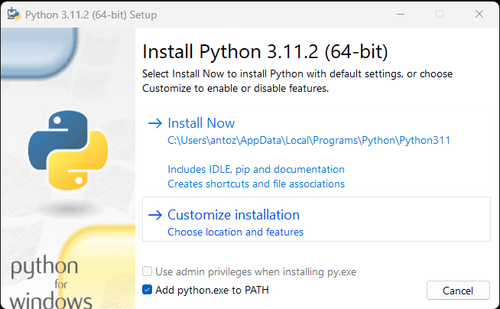
Through the above steps, the environment for crawling Google Job data is set up. Next, you can use the downloaded PyCharm combined with Scraperless to crawl Google Job data.
Step 2: Use PyCharm and Scrapeless to scrape Google Jobs data
- Launch PyCharm and select File>New Project… from the menu bar.
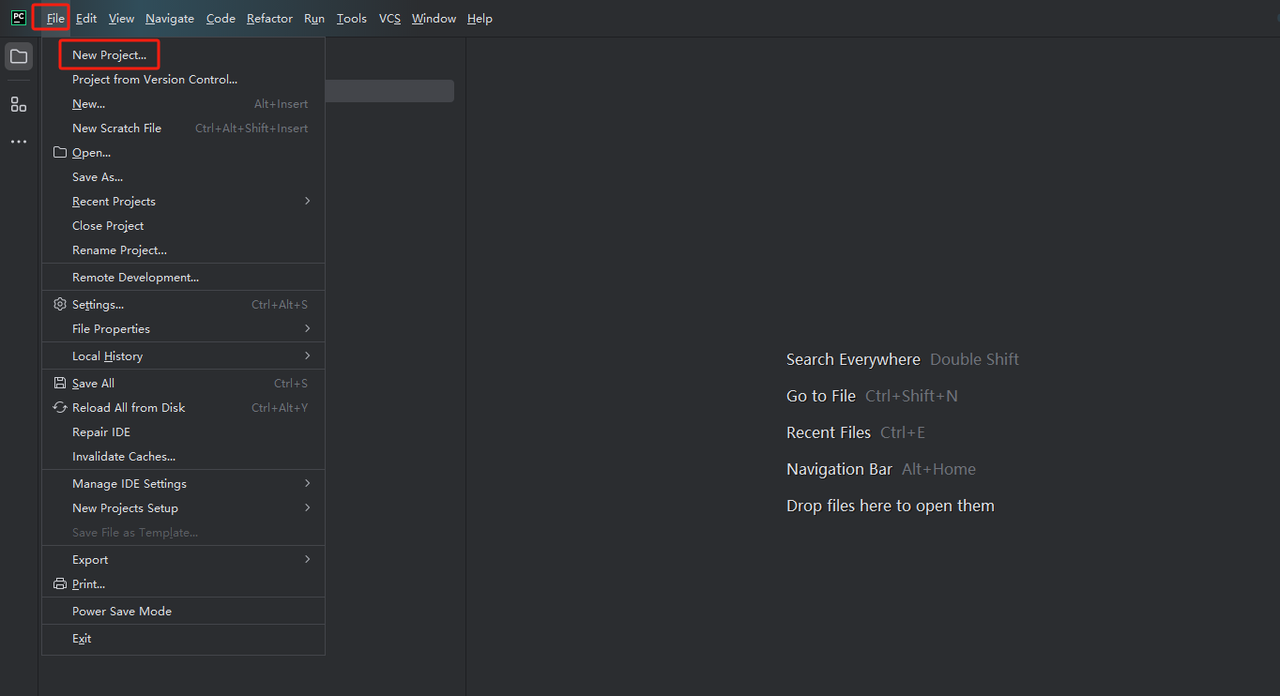
- Then, in the window that pops up, select Pure Python from the left menu and set up your project as follows:
Note: In the red box below, select the Python installation path downloaded in the first step of environment configuration
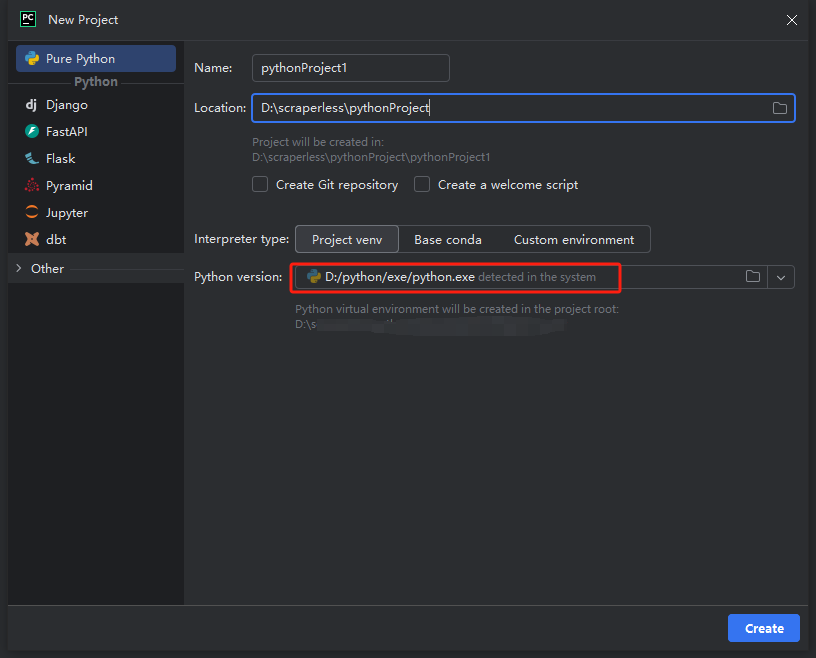
- You can create a project called python-scraper, check the "Create main.py welcome script option in the folder" and click the "Create" button. After PyCharm sets up the project for a while, you should see the following:
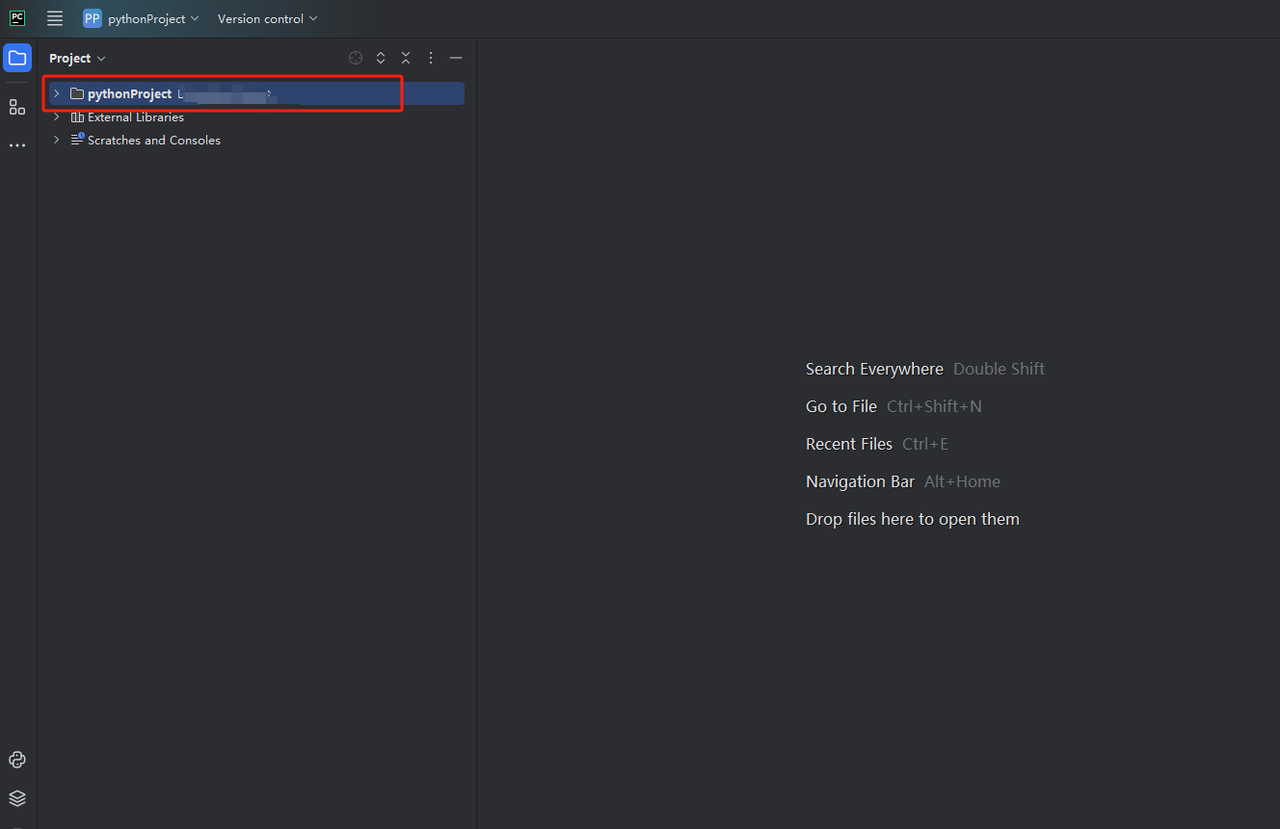
- Then, right-click to create a new Python file.
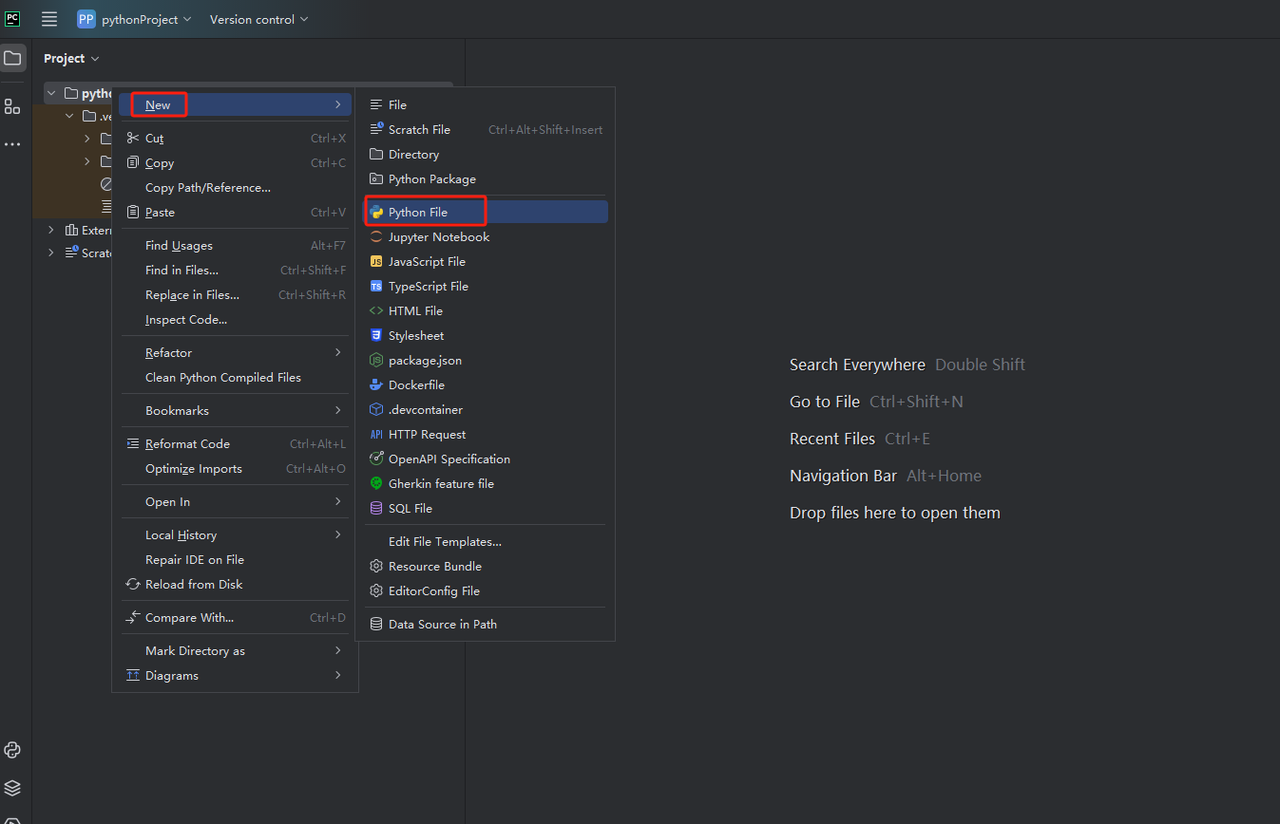
- To verify that everything is working correctly, open the Terminal tab at the bottom of the screen and type: python main.py. After launching this command you should get: Hi, PyCharm.
Step 3: Get Scrapeless API Key
Now you can directly copy the Scrapeless code into PyCharm and run it, so you can get the JSON format data of Google Job. However, you need to get the Scrapeless API key first. The steps are as follows:
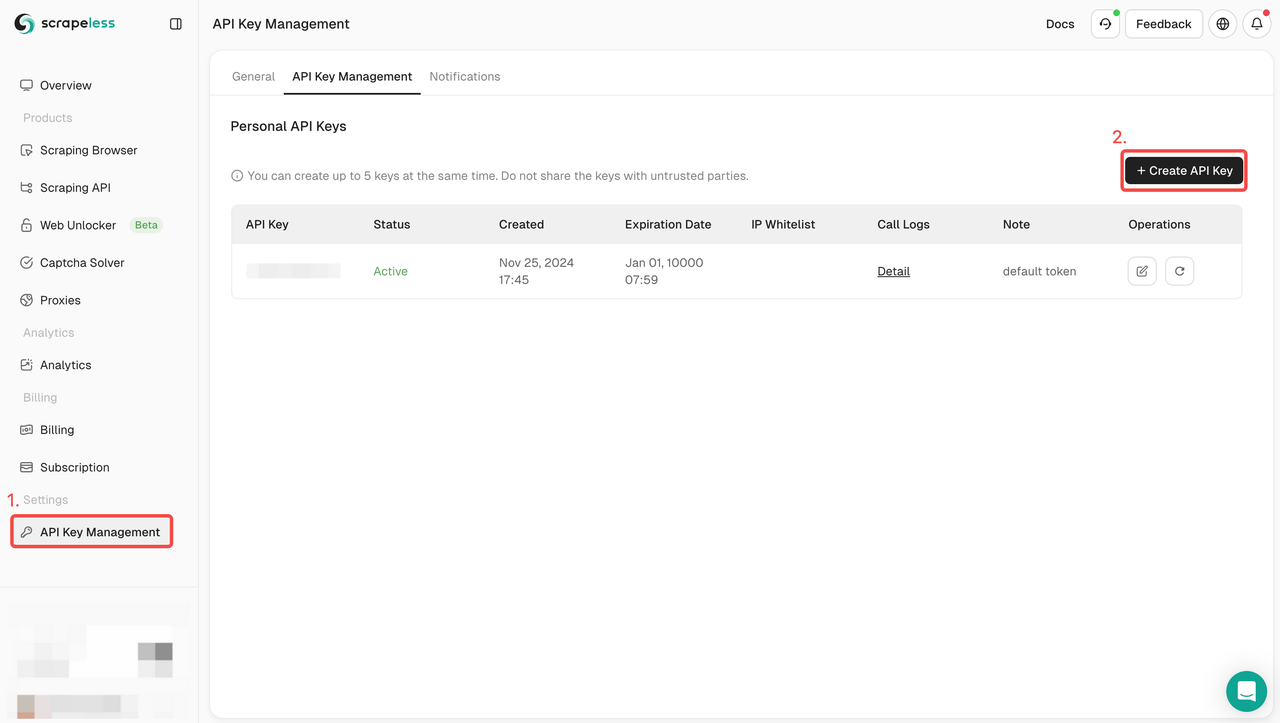
- If you don’t have an account yet, please sign up for Scrapeless. After signing up, log in to your dashboard.
- In your Scrapeless dashboard, navigate to API Key Management and click on Create API Key. You will get your API Key. Just put your mouse on it and click it to copy it. This key will be used to authenticate your request when calling the Scrapeless API.
Step 4: Understand Scrapeless API parameters
The Scrapeless API provides various parameters that you can use to filter and refine the data you want to retrieve. Here are the main API parameters for scraping Google Job information:
| Parameters | Required | Description |
|---|---|---|
| engine | TRUE | Set parameter to google_jobs to use the Google Jobs API engine. |
| q | TRUE | Parameter defines the query you want to search. |
| uule | FALSE | Parameter is the Google encoded location you want to use for the search. uule and location parameters can't be used together. |
| google_domain | FALSE | Parameter defines the Google domain to use. Defaults to google.com. Head to the Google domains page for a full list of supported Google domains. |
| gl | FALSE | Parameter defines the country to use for the Google search. It's a two-letter country code (e.g., us for United States, uk for United Kingdom, fr for France). Head to the Google countries page for a full list of supported Google countries. |
| hl | FALSE | Parameter defines the language to use for the Google Jobs search. It's a two-letter language code (e.g., en for English, es for Spanish, fr for French). Head to the Google languages page for a full list of supported Google languages. |
| next_page_token | FALSE | Parameter defines the next page token. It is used for retrieving the next page of results. Up to 10 results are returned per page. The next page token can be found in the SerpApi JSON response: pagination -> next_page_token. |
| lrad | TRUE | Defines search radius in kilometers. Does not strictly limit the radius. |
| ltype | TRUE | Parameter will filter the results by work from home. |
| uds | TRUE | Parameter enables to filter search. It's a string provided by Google as a filter. uds values are provided under the section: filters with uds, q and link values provided for each filter. |
Step 5: How to integrate the Scrapeless API into your scraping tool
Once you have the API key, you can start integrating the Scrapeless API into your own scraping tool. Here is an example of how to call the Scrapeless API and retrieve data using Python and requests.
Sample code for crawling Google Job information using the Scrapeless API:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"engine": "google_jobs",
"q": "barista new york",
}
payload = Payload("scraper.google.jobs", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()Step 6: Analyze the result data
The result data of the Scrapeless API will contain detailed information in JSON format. The following is a partial example of the result data. The specific information can be viewed in the API documentation.
{
"filters": [
{
"name": "Salary",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=Barista+new+york+salary&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQIDRAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRh8EK4tyFmWRymX9upubXBbjB9KOIUC88GpIatv-n-DLX9TtKJXNMMIdYO2nQxb4xNzjttr0Uu43Lm-GmXHPL687fgvBmKH8qj2H7a2iTdJo0v3e37tUrY02SF9SsGMZ3e6PQT6rfudnU2eFoPJICzOXs6zcIod6Pfwk5wDtpqw_NEY9J",
"q": "Barista new york salary"
}
},
{
"name": "Remote",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista%2Bnew%2Byork+remote&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQxKsJegQICxAB&ictx=0",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RR9uegVYgQNm0A_FIwPHdCgp6BeV4cyixUjw1hgRDJQE5JaCKrpdXj8qAqGf0tBZYFos3UXw0dnkvxmLPGYpQ1yE9796a05FNrMXiTref7_yMgP5WfYbP3wPdvk9Hpbv8q3y-R1UTsn-dAlNF5N6OicWqVsFU",
"q": "barista+new+york remote"
}
},
{
"name": "Date posted",
"options": [
{
"name": "Yesterday",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york since yesterday&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAC",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRnjGLk826jw_-m_gI8QkMG3DU62Ft1lBDpjQtJxI9n5nlvphZ_FhozuiZa-pL3OlfNFOvId9p73T3jFBmYJw05hbE-N1E2J12Se4S2XNj_H36-FruHX4cIe_j8ucbIbgQDsccD5Ht0tt1_fw91zMseXuY-BwyvhnOJiTzcgUbCOHZIRrKI_unZuhz8K9n1iIpXWV3AWpk95QNoL9B0qFURXiTlhykG63NrQz80D-aaM61vCTXQbTneARk4u1P870m6qmrYlxzFIesLLxnrvkOGKouA-AdW2wQ-2NEBupAK1JbQkL9sm7bwG6gYn0jjt-9oEOUaw",
"q": "barista new york since yesterday"
}
},
{
"name": "Last 3 days",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last 3 days&uds=ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg&udm=8&sa=X&ved=2ahUKEwiD1tP_mtGLAxUFvokEHZrtEVQQkbEKegQIDhAD",
"parameters": {
"uds": "ABqPDvztZD_Nu18FR6tNPw2cK_RRd1B6K-OJf2BQH1wRTP-WvlEGmt8-DwYPt192b7rPO2QTcWR6ib4kDRMCnL5tVQO8zO8RIE3h2OD731flcyiUpJA7ZkSb5ZOOKftaPnoXuSflVkzggT4i1-LmAD9fzly5xZp6y4SnVxMgTtvd2-WpYQVk-HlJi9DiLqRclx-08Fctyj76ilhCrPNTcmeYWmuT3xuop_zwqsM1_UfNSL0c8bLdkX1nPpadMD-n5uhcQ4y6Rbc4e50nyyw5-sVgk4XWD1razm6vSiNlcXlYeWYJ3osuWXRrHChhUVY3tXnTCv8I1_94wzPzrFNfwp_-qsGrzzJMWg",
"q": "barista new york in the last 3 days"
}
},
{
"name": "Last week",
"link": "https://www.google.com/search?sca_esv=7833c6f0638101e1&gl=us&hl=en&q=barista+new+york in the last Key fields in the results:
- title:job title.
- company:company offering the job
- link:link to the job posting
- location:job location
- date_posted:date the job was posted
You can now use this data to build a job board, send notifications, or integrate job data into your existing website or application.
Looking for an easy way to collect job listings?
Start using Scrapeless' Google Jobs API today! Get accurate, real-time job data effortlessly and streamline your job search process. Try it now and see the difference!
How to use Deep SerpApi to scrape Google Jobs data
If you don't want to build the crawling parameters and code yourself, you can consider using Scrapeless Deep SerpApi.
Deep SerpAPI provides a cost-effective solution to help developers quickly obtain Google search results page (SERP) data. Its pricing plan is very competitive, with prices as low as $0.1 per 1,000 queries, applicable to more than 20 search results scenarios of Google.
Advantages of Deep SerpAPI
- Lowest price: Deep SerpAPI is priced as low as $0.1/k. It is the lowest price on the market.
- Easy to use: No need to write complex code, just get data through API calls.
- Real-time: Each request can instantly return the latest search results to ensure the timeliness of the data.
- Global support: Through global IP addresses and browser clusters, ensure that search results are consistent with the experience of real users.
- Rich data types: Supports more than 20 search types, such as Google Search, Google Maps, Google Shopping, etc.
- High success rate: Provides up to 99.995% service availability (SLA).
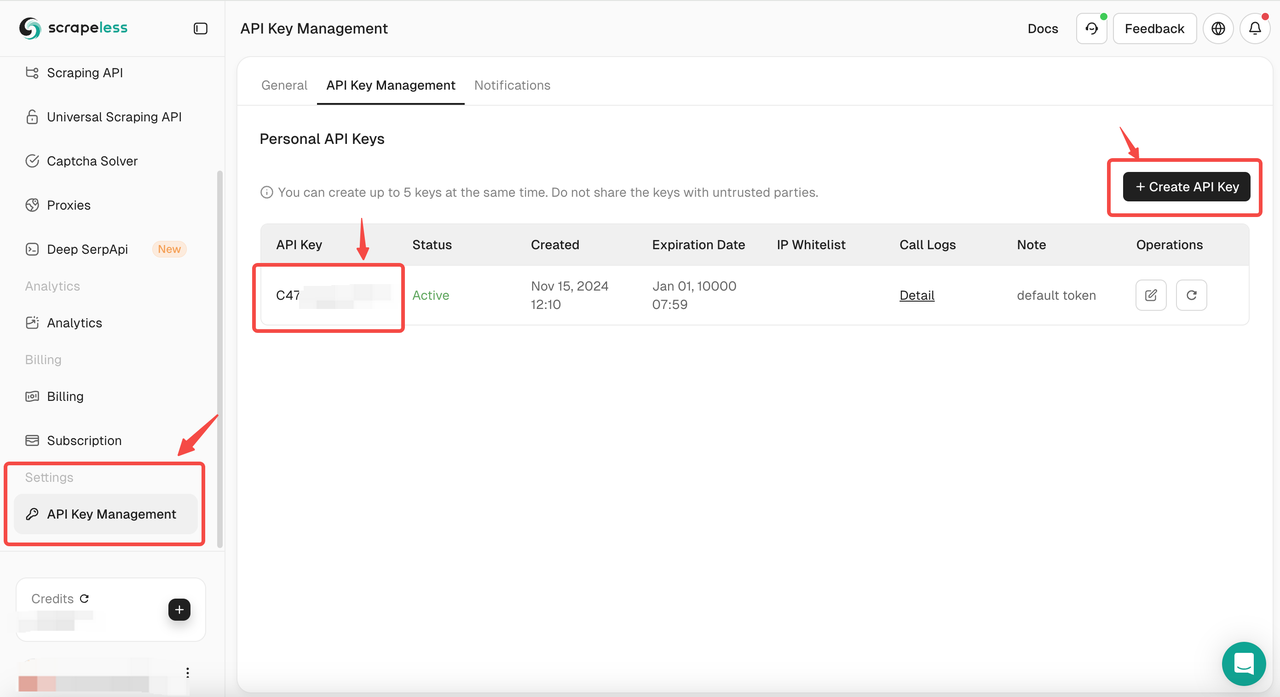
1. Sign Up and Access the API Key
- After signing up for free on Scrapeless, you can get 20,000 free search queries.
- Navigate to API Key Management. Then click Create to generate a unique API key. Once created, just click on AP to copy it.
2. Access the Deep SerpApi Playground
- Then navigate to the "Deep SerpApi" section.
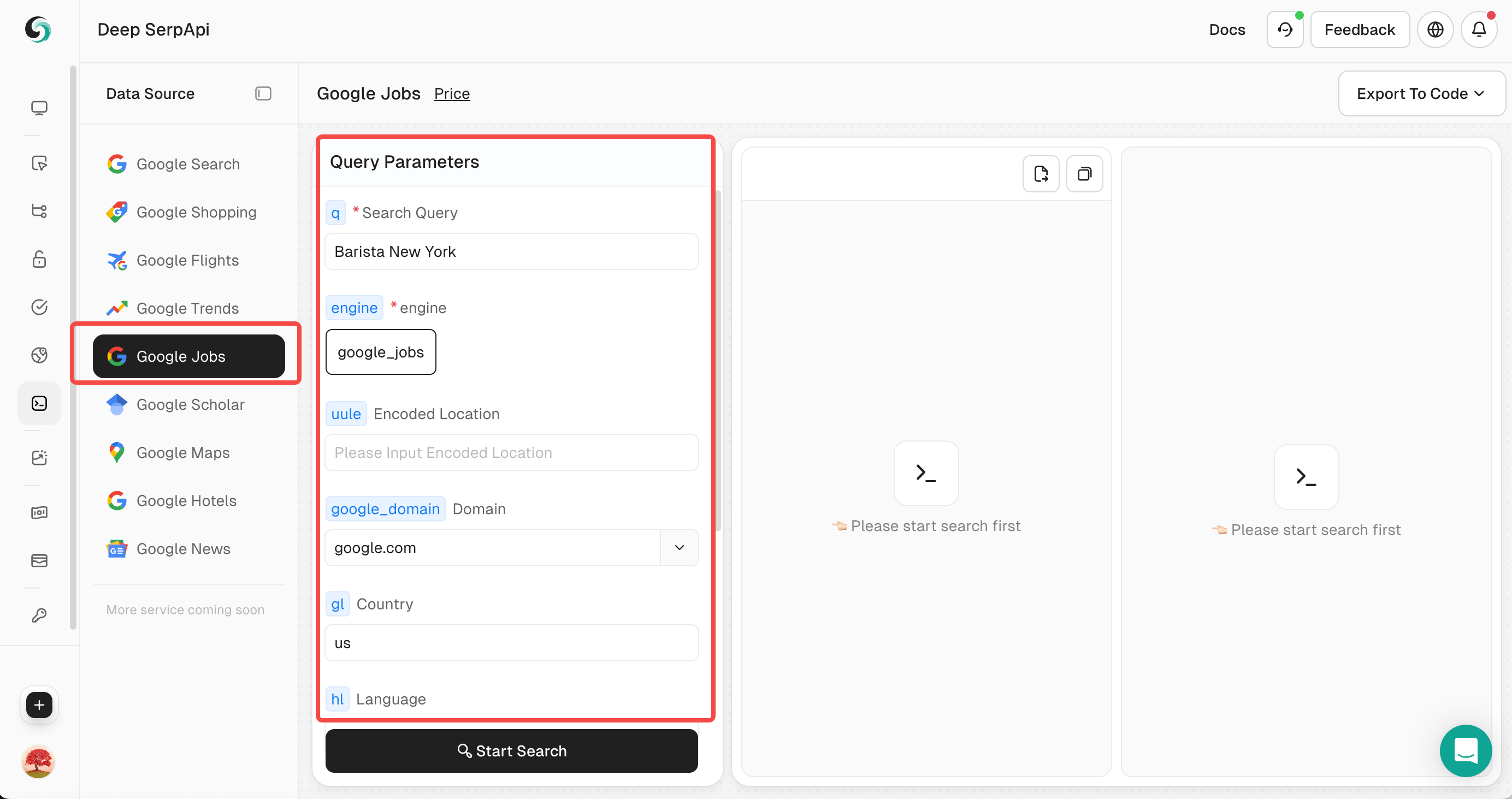
3. Set search parameters
- In the Playground, enter your search keyword, such as "Barista New York".
- Set other parameters, such as country, language, Location, Work From Home, Filter Search etc.
You can also click to view the official API documentation of Scrapeless to learn about the parameters of Google Shopping.
4. Perform a search
- Click the "Start Search" button, and the Playground will send a request to the Deep Serp API and return structured JSON data.
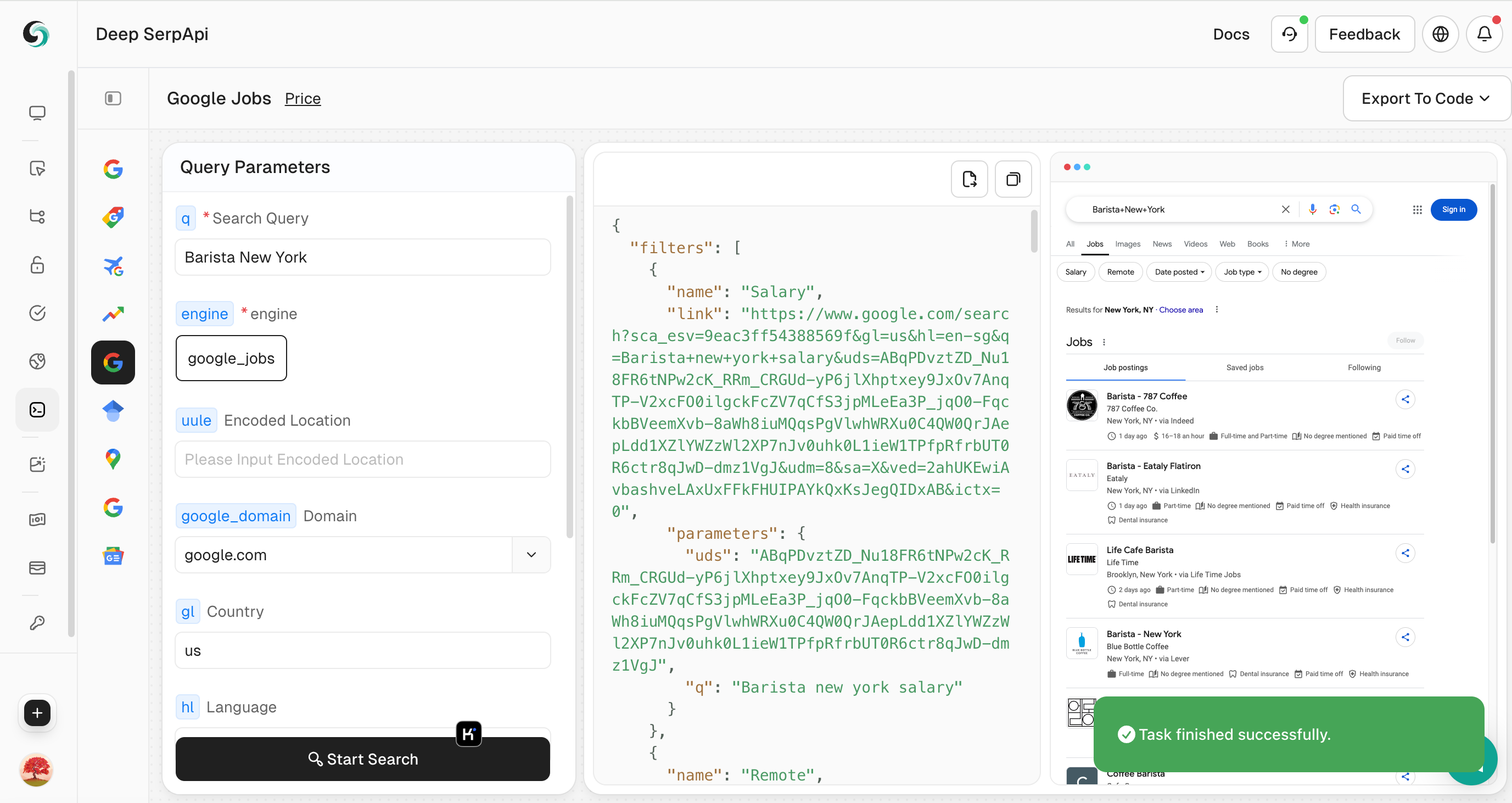
5. View and export data
- Browse the returned JSON data to view detailed information.
- If necessary, you can click "Export to Code" in the upper right corner to export the data to CSV or JSON format for further analysis.
Explore Other Popular Data Sources for Recruitment and Job Market Analysis
In addition to Google Jobs, many other platforms also provide valuable recruitment data and industry trends, which are suitable for more extensive recruitment data analysis. For example, Crunchbase, Indeed, and LinkedIn are all important data sources for recruitment and talent market analysis.
- Crunchbase provides detailed information about startups, corporate financing, industry trends, etc., which is very helpful for studying company recruitment needs and market trends.
- Indeed is one of the world's largest recruitment platforms, with rich job information, salary data and industry trends, which is suitable for job analysis, salary forecasting and talent market research.
- LinkedIn provides global professional social networks and recruitment data, which can help analyze talent flow, skill requirements and job development trends.
If your business is not limited to Google Jobs crawling, you can also consider using tools such as Scrapeless to obtain recruitment data from these platforms to further enrich your recruitment analysis and market research.
If you have similar crawling needs, or want to learn how to use Scrapeless tools to crawl data from Crunchbase, Indeed, LinkedIn and other platforms, please contact us. We will provide customized solutions to help you efficiently complete data crawling and analysis.
🎺🎺Exciting Announcement!
Developer Support Program: Integrate Scrapeless Deep SerpApi into your AI tools, applications or projects. [We already support Dify, and will soon support Langchain, Langflow, FlowiseAI and other frameworks]. Then share your results on GitHub or social media, and you will receive free developer support for 1-12 months, up to $500 per month.
FAQ
Q1: How do I get an API key for Scrapeless?
Sign up at scrapeless.com, log in to your dashboard, and generate an API key under the API Key Management section.
Q2: Can I scrape jobs from other websites?
Yes, Scrapeless supports scraping a variety of job posting sites and many other types of data. The Google Jobs API is just one example.
Q3: Can I scrape Google jobs for free?
Scrapeless offers a limited free trial. To continue, you'll need a paid plan, which gives you access to higher limits and more advanced features.
Q4: What else does Scrapeless offer?
In addition to Google Jobs, Scrapeless can scrape many types of data, including Google Maps, Google Flights, Google Trends, and more.
Conclusion
Scraping Google jobs with the Scrapeless API is a powerful and easy way to collect job postings for your own projects. With just a few lines of code, you can integrate Scrapeless into your scraper and automate the job data extraction process.
By leveraging Scrapeless’s capabilities, you can quickly craft job listings from Google’s job search engine, saving time and focusing on building your job board or application.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


