
How to Quickly Scrape Instagram Profile Data?
Specialist in Anti-Bot Strategies
Instagram is one of the most popular social media platforms with millions of users around the world. Scraping Instagram Profile is beneficial to help businesses, developers, data analysis experts for marketing analysis, competition research or personal data management.
In this article, we will show you the process of scraping Instagram Profile in depth. We will explain how to create an Instagram scraper to extract data from Instagram profiles and post pages.
It's time to learn how to quickly scrape Ins data using the convenient Scraping API.
- #Method 1. Build your Python Instagram Profile Scraper
- #Method 2. Using Scraping API collect data easily
Why scrape Instagram profiles?
Instagram public data is huge and can provide all kinds of insights. Scraping profile data can provide you with valuable information about popular users around the world, helping you predict trends, track brand awareness, understand how to improve your Instagram performance, or help businesses to prospect and reach new customers by connecting with popular Instagram profiles with similar interests.
In addition, scraped Instagram data is a viable resource for sentiment analysis studies. This data can be found in posts and comments and can be used to gather public opinion on specific trends and news.
Method 1. Python Instagram Profile Scraper
Let’s start by scraping Instagram user profiles! Next, we will explain in depth how to scrape the profile information of Instagram user ladygaga. We can do it by following the steps below:
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
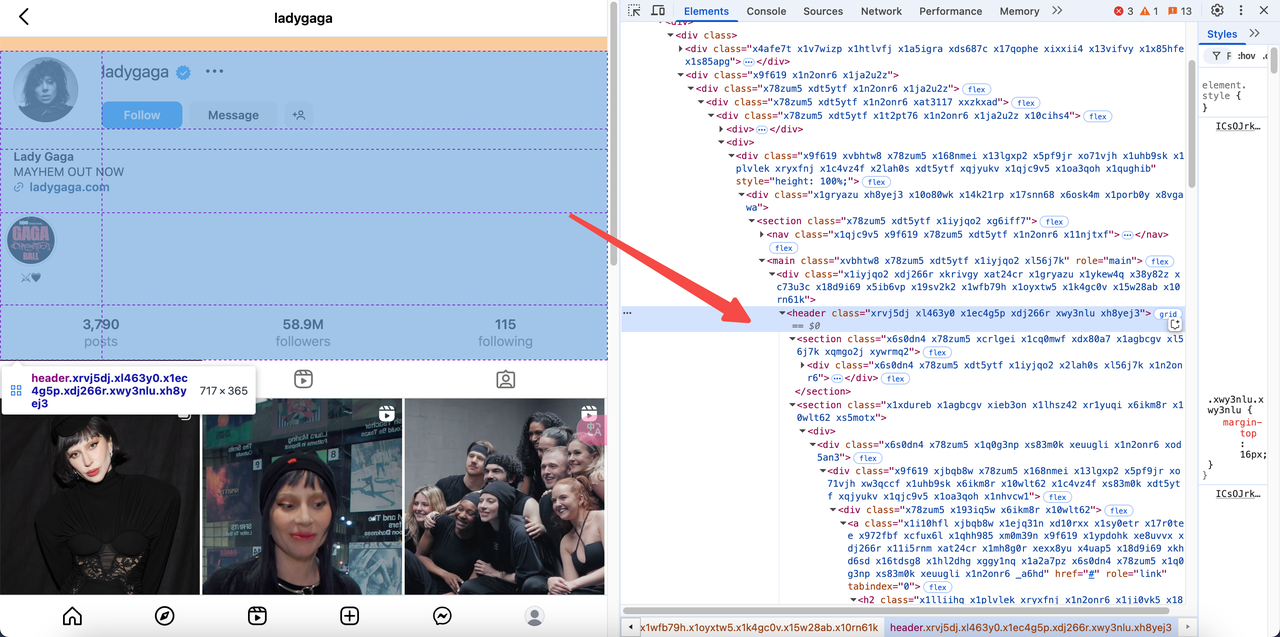
Step 1. Analyze the Target Page
- Visit the target URL: https://www.instagram.com/ladygaga/.
- Inspect the page source code to locate the embedded JSON data:
- Instagram embeds user information in a
scripttag with the formatwindow._sharedData. - We can extract this data by parsing the HTML.
Step 2. Install Required Libraries
Ensure the following Python libraries are installed:
pip install requests beautifulsoup4
Step 3. Set Request Headers
To simulate browser access, set the User-Agent and Referer headers to avoid being blocked by anti-scraping mechanisms.
Python
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}Step 4. Parse JSON Data
We need to extract the window._sharedData content from the script tag in the HTML and convert it into a Python dictionary.
Python
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON data not found in the page.")
return None
# Parse JSON data
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: Failed to parse JSON data.")
return NoneStep 5. Extract Required Fields
Retrieve the username, bio, follower count, post count, and other relevant information from the parsed JSON data.
Complete Code
Below is the full Python code, which you can use directly to scrape Lady Gaga's profile information:
Python
import requests
from bs4 import BeautifulSoup
import json
def scrape_instagram_profile(username):
url = f"https://www.instagram.com/ladygaga/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36",
"Referer": "https://www.instagram.com/"
}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"Error: Unable to fetch data for {username}. Status code: {response.status_code}")
return None
soup = BeautifulSoup(response.text, "html.parser")
script_tag = soup.find("script", type="application/ld+json")
if not script_tag:
print("Error: JSON data not found in the page.")
return None
# Parse JSON data
try:
data = json.loads(script_tag.string)
except json.JSONDecodeError:
print("Error: Failed to parse JSON data.")
return None
profile = {
"username": data["author"]["name"],
"bio": data["description"],
"follower_count": data["author"]["interactionStatistic"][0]["userInteractionCount"],
"post_count": data["author"]["interactionStatistic"][1]["userInteractionCount"]
}
return profile
# Example usage
if __name__ == "__main__":
username = "ladygaga"
profile_data = scrape_instagram_profile(username)
if profile_data:
print("Instagram Profile Data:")
print(json.dumps(profile_data, indent=4, ensure_ascii=False))Scraping Results
After running the code, the profile_data output will include the following fields:
JSON
{
"username": "ladygaga",
"bio": "Lady Gaga MAYHEM OUT NOW",
"follower_count": "58.9M",
"post_count": "3,790"
}Method 2. Scrapeless Scraping API (Recommend)
Scraping Instagram is pretty easy. However, Instagram is extremely restrictive about access to its public data. It only allows a few requests per day for non-logged-in users, beyond which it redirects requests to the login page.
How to avoid blocking Instagram scrapers? Scrapeless is your ideal scraping tool!
Scrapeless provides web scraping, web unblocking, and data extraction APIs for large-scale data collection.
- Anti-bot protection bypass: Avoid getting blocked while scraping the web!
- Rotating residential proxies: Prevent IP bans and geo-blocking.
- JavaScript rendering: Scrape dynamic web pages via cloud browsers.
- Python and Typescript SDKs, as well as Scrapy integrations.
Is this Instagram Scraping API free?
Yes. Scrapeless provides you with a $2 free credit. You can sign up directly to claim free credit. With Instagram profile Scraper, you can easily collect users information for free!
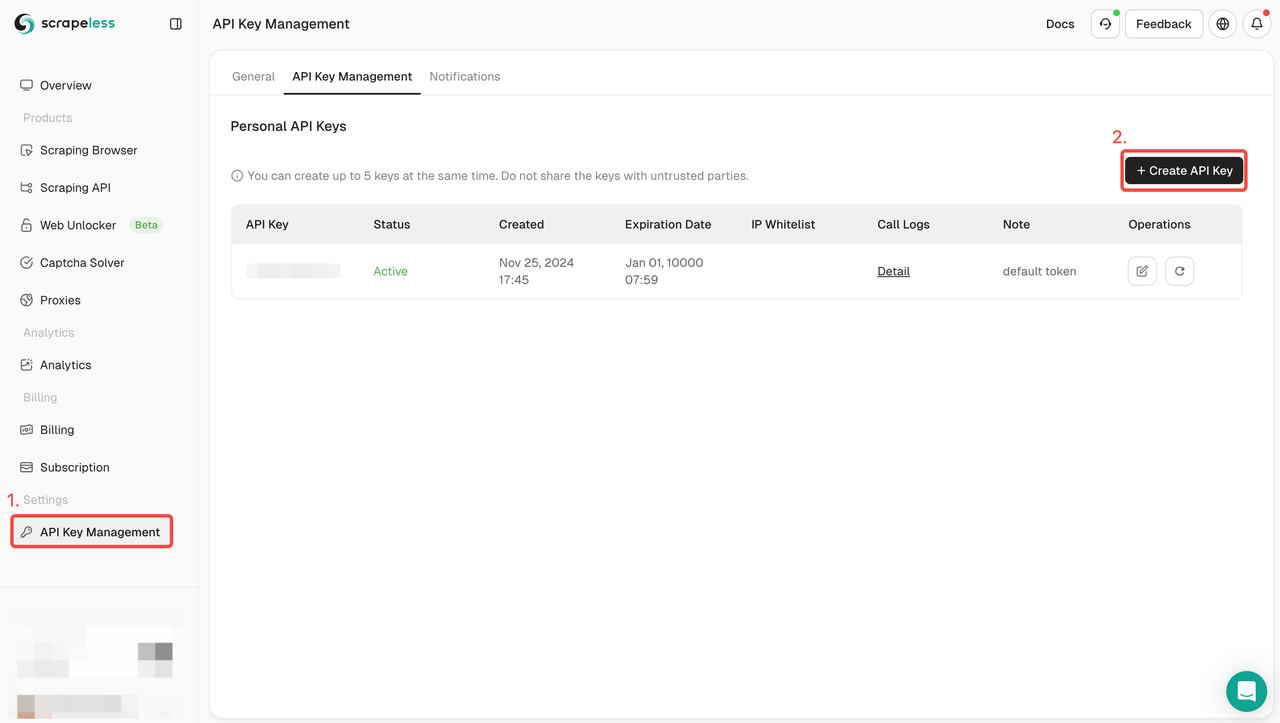
Step 1. Create your API Token
To get started, you’ll need to obtain your API Key from the Scrapeless Dashboard:
- Log in to the Scrapeless Dashboard.
- Navigate to API Key Management.
- Click Create to generate your unique API Key.
- Once created, simply click on the API Key to copy it.
The Bottom Lines
In this tutorial, we introduced 2 efficient ways to get Instagram profile data. We showed how to handle authentication, make requests, handle responses, and integrate proxy IPs for better stability and security.
Following this guide, you can easily start extracting Instagram profile data for personal or commercial use while maintaining privacy and avoiding issues such as rate limits.
To improve the efficiency of data collection, we recommend that you use the advanced scraping API, which only requires simple configuration parameters to complete data extraction!
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


