
How to Scrape TikTok User Info & Follower List
Advanced Data Extraction Specialist
In today's digital age, social media platforms like TikTok have become valuable resources for obtaining important data and insights. Whether you're a marketer, analyst, or researcher, extracting TikTok user information and follower lists can provide strong support for your work. However, manually collecting this data is not only tedious but also inefficient. Fortunately, with modern web scraping tools, you can quickly and accurately collect TikTok user data, follower lists, and other relevant information.
In this article, we will explore how to easily scrape TikTok user data and follower lists using Scrapeless, a powerful and user-friendly scraping tool. Whether you need to analyze user engagement, track social media influence, or conduct market research, Scrapeless can help you efficiently gather the TikTok data you need while ensuring your scraping activities are legal and compliant. Next, we will walk you through how to set up and use Scrapeless for TikTok data scraping.
What Are the Benefits of Scraping TikTok Data?
Scraping TikTok data provides a wealth of opportunities, especially for developers and marketers. Here are some key benefits:
- Market Research: Get insights into trends, viral content, and user behavior on TikTok.
- Competitor Analysis: Track competitors' engagement, popular content, and marketing strategies.
- Influencer Identification: Discover top influencers for effective partnership and influencer marketing.
- Business Insights: Analyze TikTok’s e-commerce features and shop performance for better sales strategies.
For developers, TikTok data scraping offers the ability to integrate real-time insights, track performance, and optimize content or marketing campaigns using real-time data feeds.
What Data Can Scrapeless Scrape from TikTok?
Scrapeless offers powerful capabilities that help users scrape various data from TikTok. Below are some key types of data that can be scraped using Scrapeless:
- User Profile Information
- Username
- Profile picture
- Bio
- Followers and Following Lists
- Number of followers
- Number of followings
- Basic information of followers
- Video Content Data
- Video title
- Video description
- Video tags
- Video length
- Engagement Data
- Likes
- Comments
- Shares
- Views
- Comment Data
- Comment content
- Commenter’s information (e.g., username)
In addition to the data listed above, Scrapeless also offers more customizable scraping options based on your needs, helping you gather even more valuable TikTok data.
How to Scrape TikTok Data Using Scrapeless
Scrapeless is a comprehensive and developer-friendly web scraping solution designed to provide easy access to large-scale data collection from various websites, including social media platforms like TikTok, e-commerce websites, and more.
With Scrapeless, developers can focus on their projects without worrying about complex coding or managing proxies. The platform handles all aspects of web scraping, from data extraction to bypassing anti-scraping measures, offering an efficient solution for businesses and developers alike.
Key Features of Scrapeless Scraping API
- No Coding Required:
Scrapeless is designed for both technical and non-technical users. With its easy-to-use API, developers don’t need to worry about setting up proxies, solving CAPTCHAs, or writing complex scraping scripts. This significantly reduces the time and effort required for web scraping projects.
- Easy Integration with API:
Scrapeless provides simple, well-documented API endpoints that can be integrated into a variety of programming languages such as Python, JavaScript, and Ruby. Developers can quickly implement these endpoints in their projects with minimal setup, thus shortening the development cycle.
- Bypass Anti-Scraping Protection:
One of the biggest challenges developers face when scraping data from websites is overcoming anti-scraping measures such as IP blocking, CAPTCHAs, and robot detection mechanisms. Scrapeless automatically handles these challenges, allowing you to focus on data extraction instead of dealing with these obstacles.
- Compliant and Ethical Data Collection:
Scrapeless is committed to ensuring that all data collection complies with legal standards and industry best practices. It enables developers to collect data in a way that respects the website's terms of service, ensuring that your scraping activities are both legal and ethical.
- Continuous Updates and Support:
Scrapeless continuously updates its features and API to keep up with changing web standards and user feedback. Developers have access to dedicated support to help resolve any issues or meet custom requirements.
How to Scrape TikTok User Info (Step-by-Step Guide)
Step 1: Prerequisites
Before we start, we need to do some preparatory work
Execute the following command to ensure that you have a Python environment; if not installed, please install the Python environment first
python --versionInstall related dependency packages
pip3 install beautifulsoup4 playwright csvOnce the installation is complete, you can create a Python file (scraper.py) in your Python IDE and get ready to start writing code.
Step 2: Capture Tiktok video page data information
For this example, we will use the Tiktok video information page as the target website
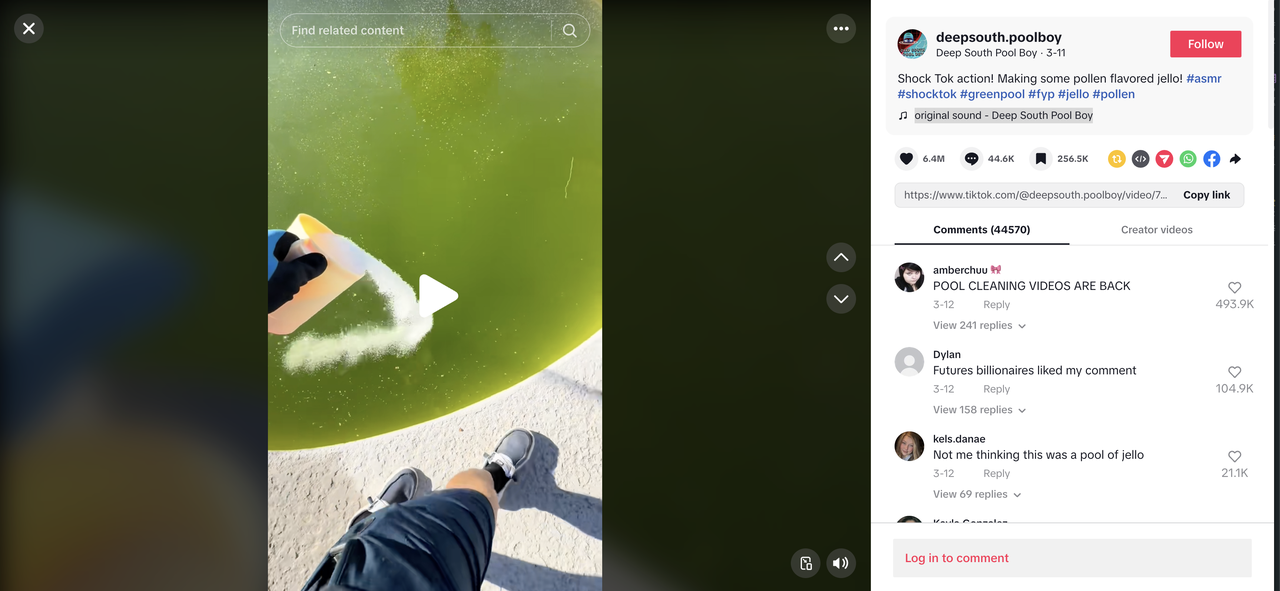
We will analyze the HTML structure of the page to explain how to crawl the user's
- nickname
- avatar
- topic tag
First, write the following code in the scraper.py file created earlier
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import csv
# define target website url
url = "https://www.tiktok.com/@deepsouth.poolboy/video/7480576464140635422"
# use playwright to scrape the website
with sync_playwright() as p:
# launch the browser
browser = p.chromium.launch(headless=False)
# create a new page
page = browser.new_page()
# navigate to the target website
page.goto(url)
# wait for the page to load
page.wait_for_load_state("load")
# get the page content
html = page.content()
# close the browser
browser.close()
soup = BeautifulSoup(html, "html.parser")In the above code, we first define the URL address of the target crawling website. Then we use the playwright library to access the target website and use its related API to obtain the HTML structure content of the website.
Based on the obtained HTML structure content, we now only need to analyze the DOM structure where the target information to be crawled is located, and extract the target field information through the API provided by playwright and the related tag attribute matching rules.
Get user nickname
First, we open the browser's developer tools. Press F12 to open the browser's debugging tool, and then use the element selector in the developer tools to select elements.
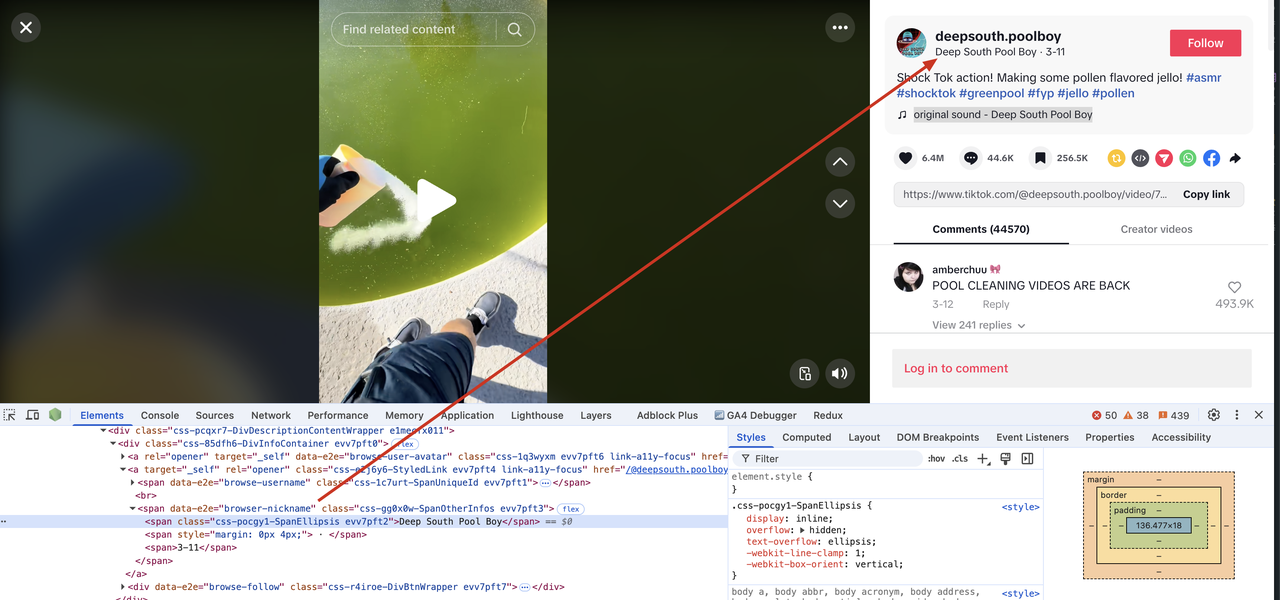
We can see that the user's nickname is in the span tag, and the span tag's data-e2e attribute value is browser-nickname. Let's modify the scraper.py file and add the following code
nick_name_container = soup.find("span", {"data-e2e": "browser-nickname"})
# get the first span tag text
nick_name = nick_name_container.find("span").text
print(nick_name)Note: Since our nickname is in the first child element under the target tag, after matching the target element, we also need to get the first child element under it.
You will see the following output

Get user avatar
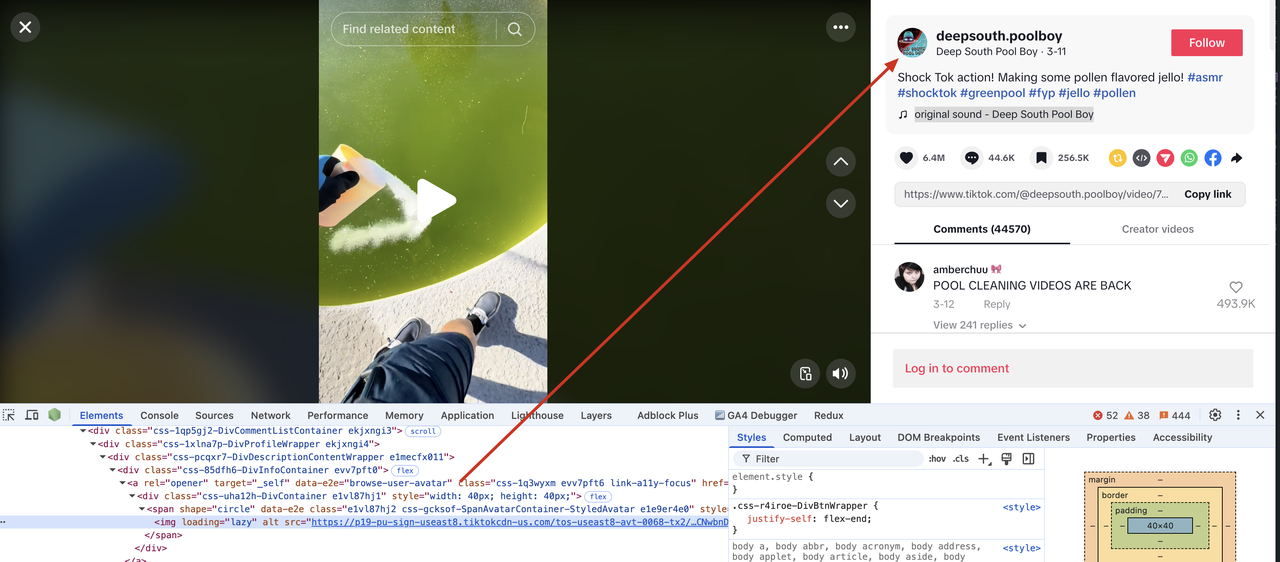
We can see that the user's avatar is in the img tag. Since the img tag does not have attribute information that can support unique selection, we need to first match its outer div tag, and the tag's data-e2e attribute value is browse-user-avatar. Let's modify the scraper.py file and add the following code.
carousel_container = soup.find("a", {"data-e2e": "browse-user-avatar"})
avatar = carousel_container.find("img").get("src")
print(avatar)You will see the following output

Get hashtags
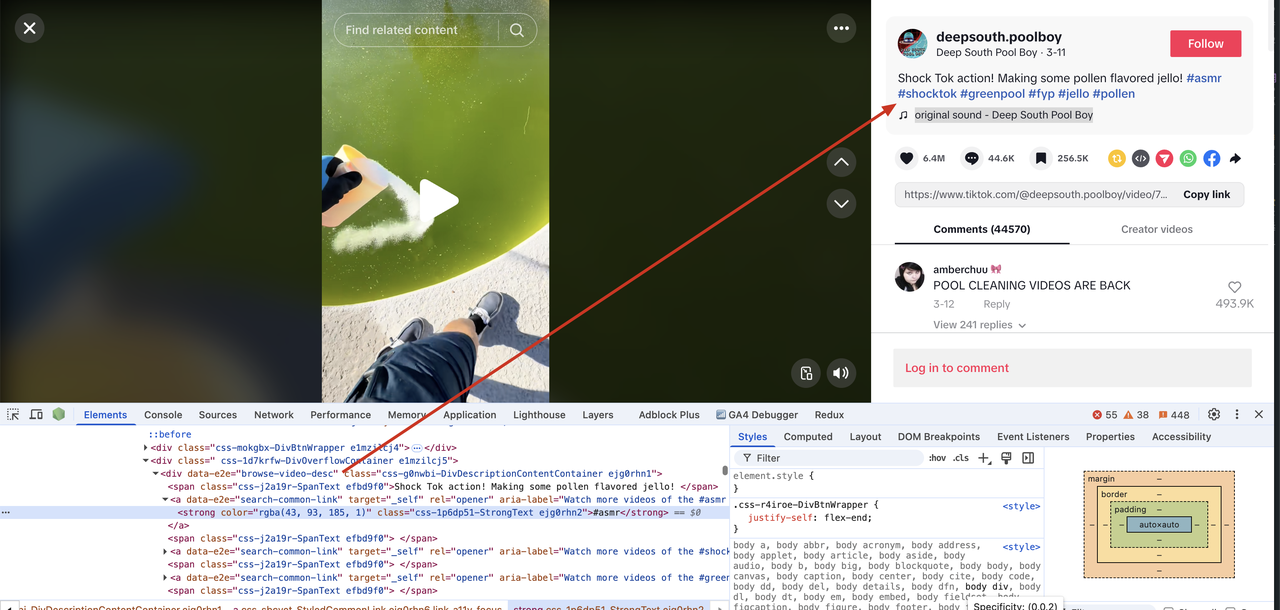
We can see that the topic tag information is quite special, it is combined with the video description information. Through further analysis, we need to first match the outer layer of the video description information, which can be matched with the div tag whose data-e2e attribute value is browse-video-desc. Then further extract the inner element a tag whose attribute data-e2e value is search-common-link, and finally further extract the value of the inner strong tag. Let's modify the scraper.py file and add the following code.
...
topic_tags = []
topic_tags_container = soup.find("div", {"data-e2e": "browse-video-desc"})
topic_search_tags = topic_tags_container.find_all("a", {"data-e2e": "search-common-link"})
for tag in topic_search_tags:
topic_tag_text = tag.find("strong").text.strip()
topic_tags.append(topic_tag_text)
print(topic_tags)You will see the following output

Export data
Based on the above step-by-step crawling code integration, the following is the complete code
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import csv
# define target website url
url = "https://www.tiktok.com/@deepsouth.poolboy/video/7480576464140635422"
# use playwright to scrape the website
with sync_playwright() as p:
# launch the browser
browser = p.chromium.launch(headless=False)
# create a new page
page = browser.new_page()
# navigate to the target website
page.goto(url)
# wait for the page to load
page.wait_for_load_state("load")
# get the page content
html = page.content()
# close the browser
browser.close()
soup = BeautifulSoup(html, "html.parser")
carousel_container = soup.find("a", {"data-e2e": "browse-user-avatar"})
avatar = carousel_container.find("img").get("src")
print(avatar)
nick_name_container = soup.find("span", {"data-e2e": "browser-nickname"})
# get the first span tag text
nick_name = nick_name_container.find("span").text
print(nick_name)
topic_tags = []
topic_tags_container = soup.find("div", {"data-e2e": "browse-video-desc"})
topic_search_tags = topic_tags_container.find_all("a", {"data-e2e": "search-common-link"})
for tag in topic_search_tags:
topic_tag_text = tag.find("strong").text.strip()
topic_tags.append(topic_tag_text)
print(topic_tags)
user_info_data = [{
"Avatar": avatar,
"Nick Name": nick_name,
"Topic Tags": topic_tags
}]
# export the data to a CSV file
with open("tiktok.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=user_info_data[0].keys())
writer.writeheader()
for data in user_info_data:
writer.writerow(data)We finally export the captured data into a tiktok.csv file. Finally, we can see the following file content:

How to Scrape TikTok Follower List with Python (Step-by-Step Guide)
Analyze the web page structure
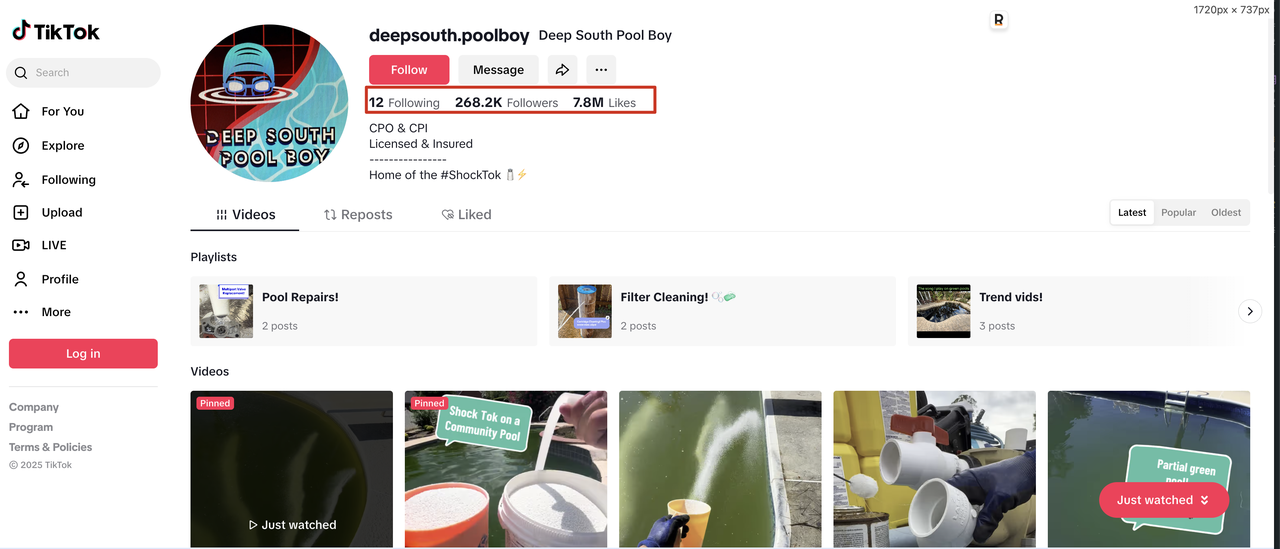
Before crawling the number of users’ followers, we need to analyze the data structure of the user’s personal homepage
First, we enter the target website page and check the user’s following information
Then we open the browser console and observe the rendered DOM structure of the page
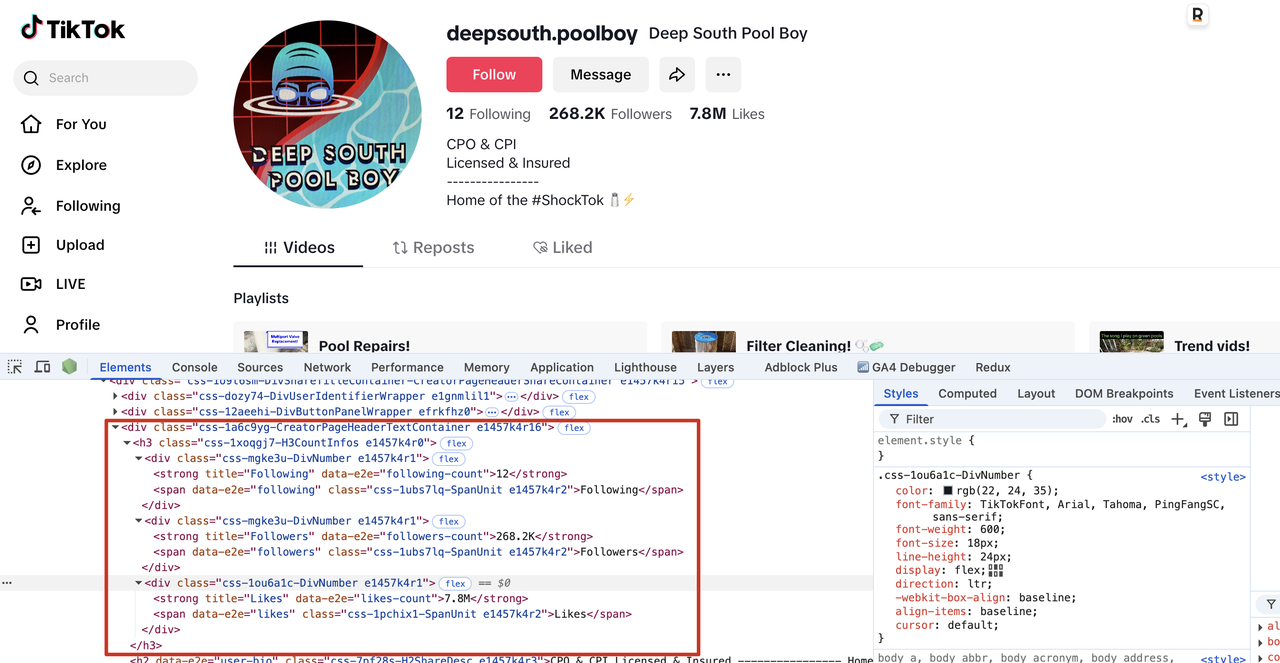
- Number of followers of a user: strong tag, its data-e2e attribute value is following-count
- Number of followers of a user: strong tag, its data-e2e attribute value is followers-count
- Number of likes of a user: strong tag, its data-e2e attribute value is likes-count
After analyzing the structure of the information, let's create a follower.py script and write the following code.
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import csv
# define target website url
url = "https://www.tiktok.com/@deepsouth.poolboy"
# use playwright to scrape the website
with sync_playwright() as p:
# launch the browser
browser = p.chromium.launch(headless=False)
# create a new page
page = browser.new_page()
# navigate to the target website
page.goto(url)
# wait for the page to load
page.wait_for_load_state("load")
# get the page content
html = page.content()
# close the browser
browser.close()
soup = BeautifulSoup(html, "html.parser")
following_count = soup.find("strong", {"data-e2e": "following-count"}).text.strip()
print(following_count)
followers_count = soup.find("strong", {"data-e2e": "followers-count"}).text.strip()
print(followers_count)
likes_count = soup.find("strong", {"data-e2e": "likes-count"}).text.strip()
print(likes_count)
follow_data = [{
"following_count": following_count,
"followers_count": followers_count,
"likes_count": likes_count
}]
# export the data to a CSV file
with open("follow_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=follow_data[0].keys())
writer.writeheader()
for data in follow_data:
writer.writerow(data)By combining the distribution code and finally exporting the crawled data into a csv file, we will see the following data information.

FAQ about TikTok Scraping
- Can I scrape TikTok follower data without coding?
Yes, you can scrape TikTok follower data without coding by using pre-built scraping tools like Scrapeless. These tools provide a user-friendly interface for non-technical users to collect follower data from TikTok.
- Is it legal to scrape data from TikTok?
Scraping data from TikTok can violate TikTok's Terms of Service, which prohibit unauthorized access to their platform. Make sure to comply with TikTok's policies and consider ethical guidelines when scraping data. Always be mindful of privacy regulations.
- What is the best way to scrape TikTok followers?
If you are a developer, Python is the most flexible choice; but if you are a non-technical user, Scrapeless provides a simpler and easier-to-use solution.
Conclusion
To wrap up, scraping TikTok user information and follower lists can be a powerful way to gather insights for marketing, analytics, or research purposes. By using the right tools and understanding the platform’s structure, you can efficiently collect valuable data while staying compliant with TikTok's terms of service. Whether you’re looking to track user engagement, analyze follower demographics, or study content performance, scraping can provide crucial data for your strategy. Remember to always use responsible scraping practices, respect user privacy, and be mindful of platform rules. By doing so, you can leverage TikTok's vast user data to enhance your campaigns and grow your presence online.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


