
How to Scrape TikTok to Obtain Video Information?
Expert Network Defense Engineer
TikTok is one of the leading social media platforms with massive traffic. Just imagine how much valuable data TikTok can provide!
In this article, we'll explain how to scrape TikTok video information. Additionally, we'll demonstrate scraping this data through TikTok's hidden API or embedded JSON datasets. Let's get started!
Why Scrape TikTok?
TikTok boasts enormous social engagement, making it possible to gather various insights for different use cases:
Trend Analysis
Trends on TikTok change rapidly, making it challenging to keep up with users' latest preferences. Scraping TikTok effectively captures these trend shifts and their impact, allowing for improved marketing strategies aligned with user interests.
Lead Generation
Scraping TikTok data enables businesses to identify marketing opportunities and new customers. This can be achieved by pinpointing influencers whose follower demographics match relevant business sectors.
Sentiment Analysis
TikTok web scraping serves as an excellent source for collecting text data from comments, which can be analyzed through sentiment models to gather opinions on specific topics.
Challenges of Scraping TikTok
TikTok scraping refers to the process of extracting publicly available data from TikTok. While it may involve both manual and automated activities, it's typically an automated process executed by web crawlers or custom scripts that interact with TikTok's API (Application Programming Interface).
The data may include various types of information such as:
- User Profiles: Information about TikTok users, including profile names, bios, and follower counts.
- Demographics: Data related to user characteristics like age, gender, location, and interests.
- Videos: Short videos posted by users, including captions, likes, comments, shares, and views.
- Hashtags: Keywords or phrases used to categorize TikTok content.
- Comments: Text responses submitted by users, including text content, timestamps, and like counts.
- Engagement Metrics: Information on how users interact with content (likes, comments, shares, views).
- Trends: Data about popular topics, themes, or styles on TikTok.
How to Build Your TikTok Scraper?
Let's simplify things! We now formally begin the step-by-step process of scraping TikTok video data. It's time to experience the tremendous value TikTok has to offer!
Before commencing the actual scraping process, let's first examine TikTok's video content structure together. This will enable us to more efficiently locate the required information and complete the data extraction in a more straightforward manner.
What Data Can We Scrape from Videos?
- Video URL
- Video Description
- Music Name
- Release Date
- Tags
- Views
- Likes Count
- Comments Count
- Shares Count
- Bookmarks Count
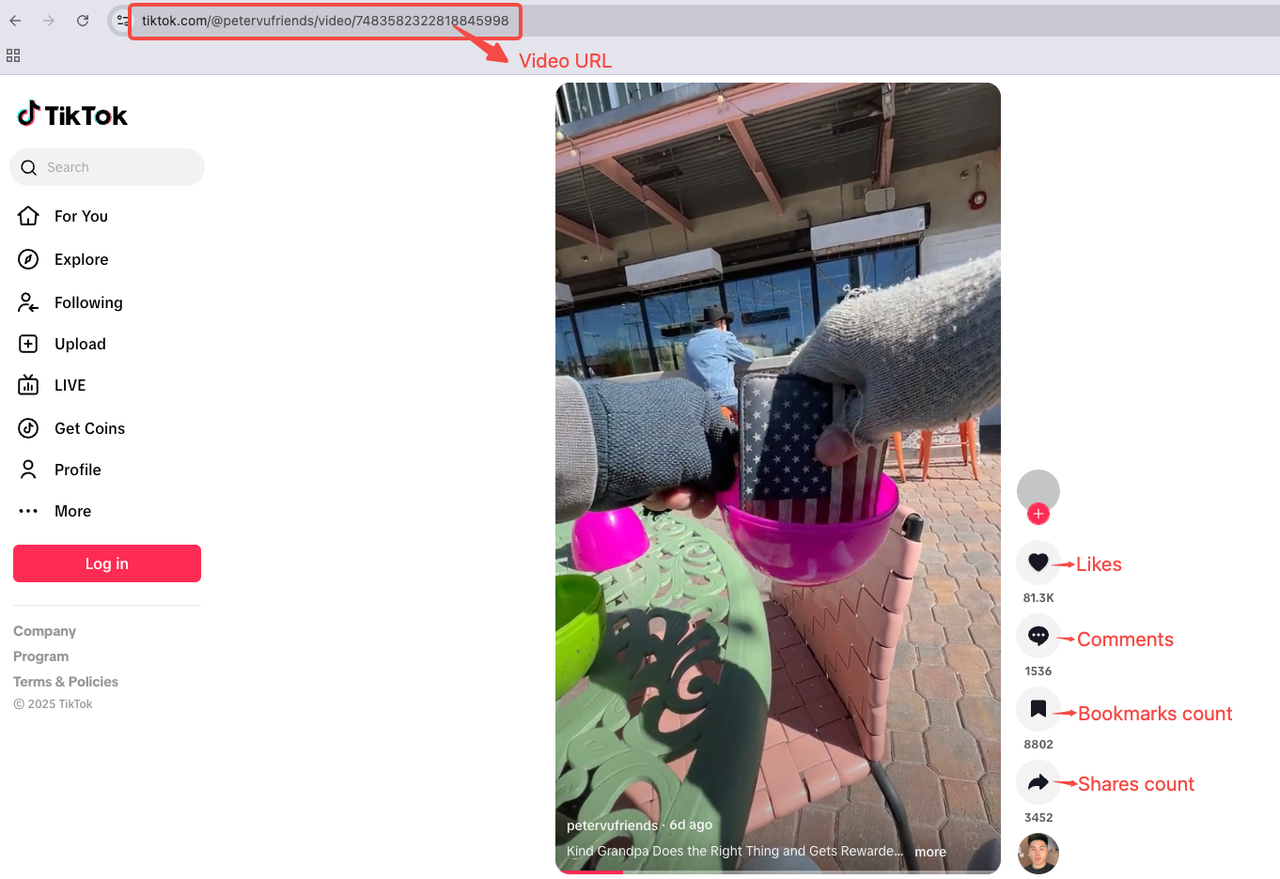
Video Page Analysis
To make data scraping more intuitive, we will analyze the following video as a reference: https://www.tiktok.com/@petervufriends/video/7476546872253893934.
We firmly protect the privacy of the website. All data in this blog is public and is only used as a demonstration of the crawling process. We do not save any information and data.
How to Locate the Data We Need?
Let’s dive deep into the HTML structure! Here’s what we need to extract from this video:
View Count
The view count is typically prominently displayed on the video page. Simply open the developer tools and locate the relevant tag:
Python
<strong data-e2e="video-views" class="video-count css-dirst9-StrongVideoCount e148ts222">281.4K</strong>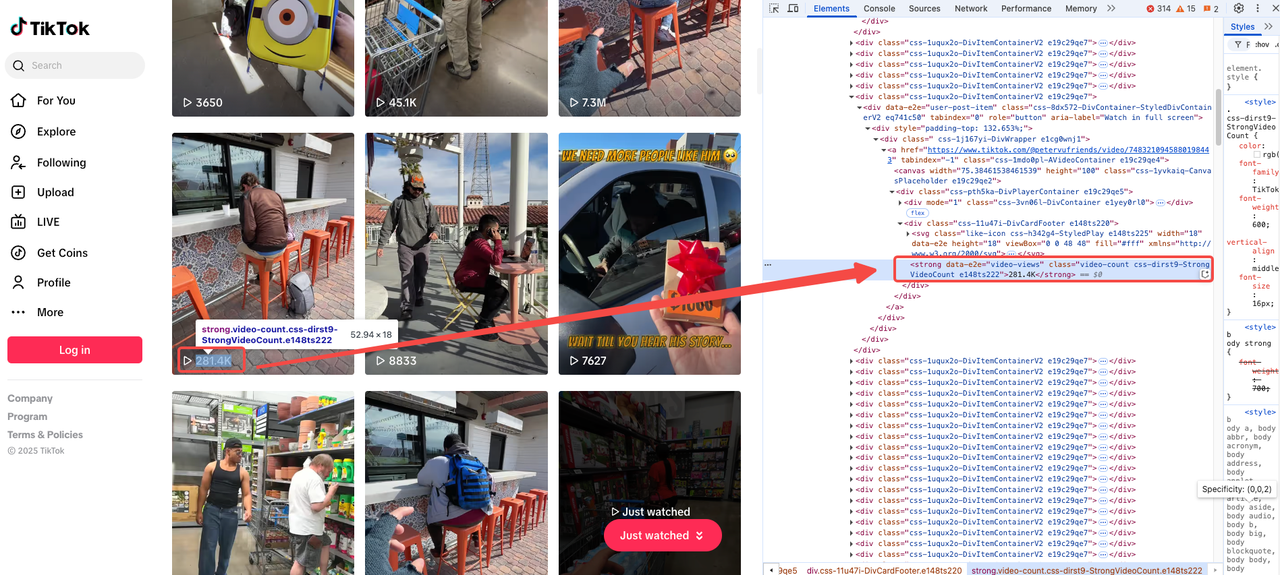
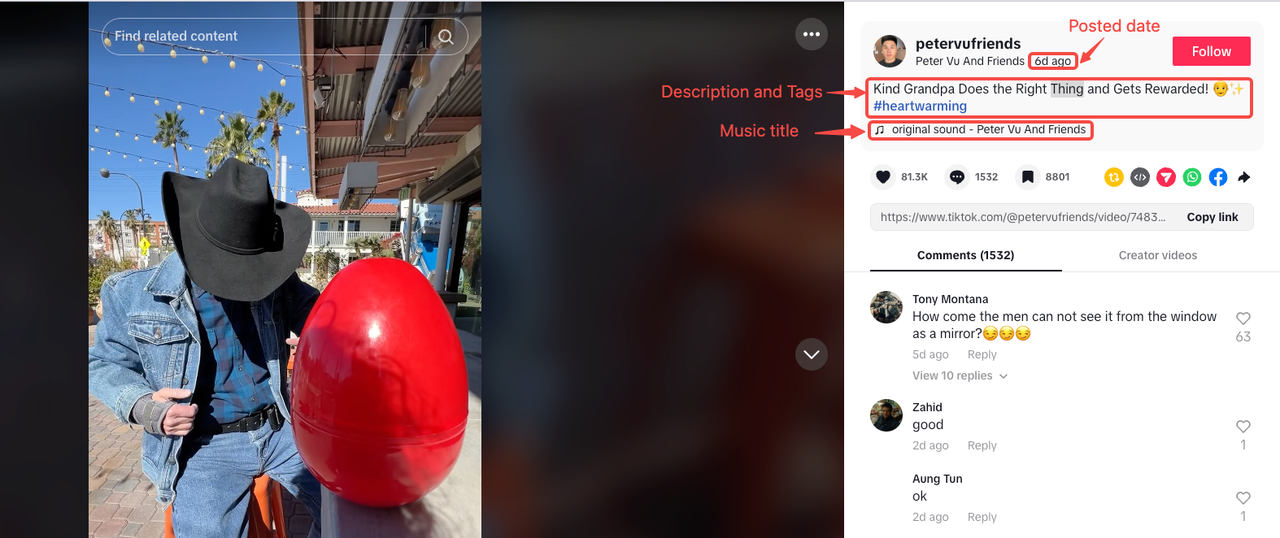
Video Description & Tags
As we initially observed, the video description and tags usually appear in the same section. However, some videos may not have descriptions or tags.
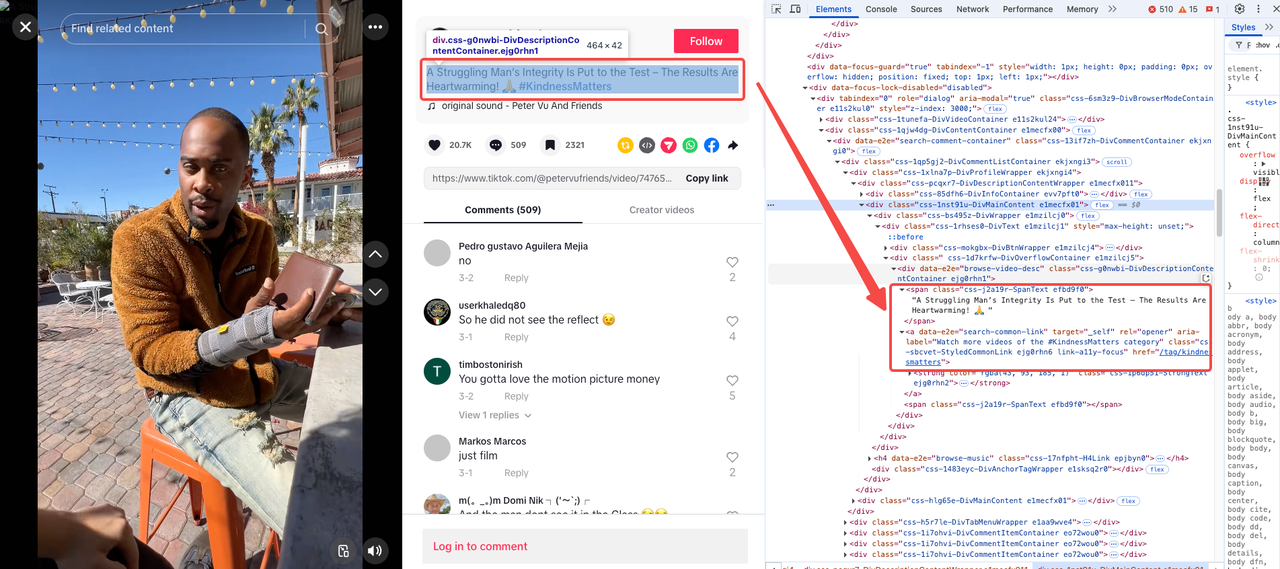
- Video description is inside a
<span>with a unique class:css-j2a19r-SpanText. - Video tags are separate but share the same attribute:
data-e2e="search-common-link".
Music Title
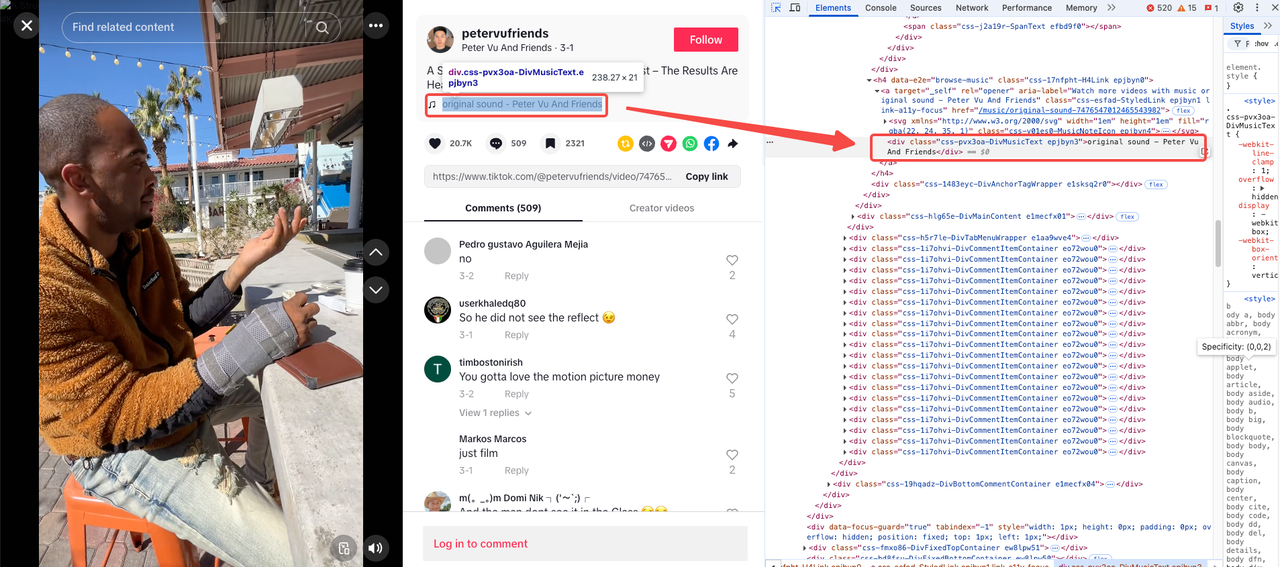
Upload Date
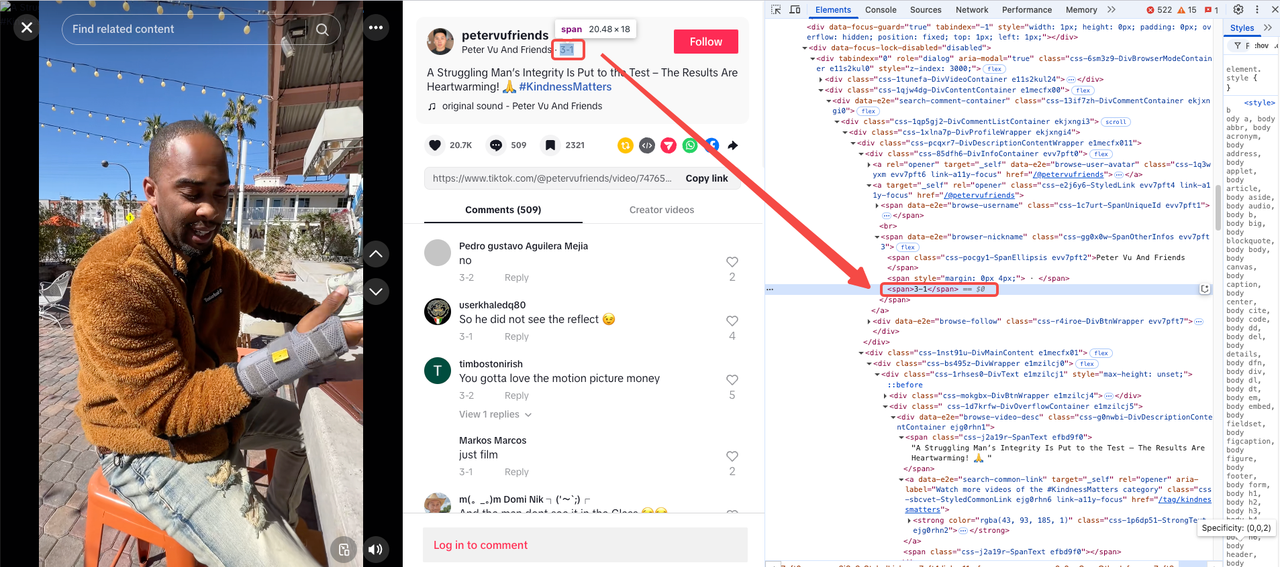
The date is isolated as the last <span> within a parent element containing the attribute: data-e2e="browser-nickname".
Like, Comment, and Bookmark Counts
These metrics usually appear together, and you can find them under the same collection:
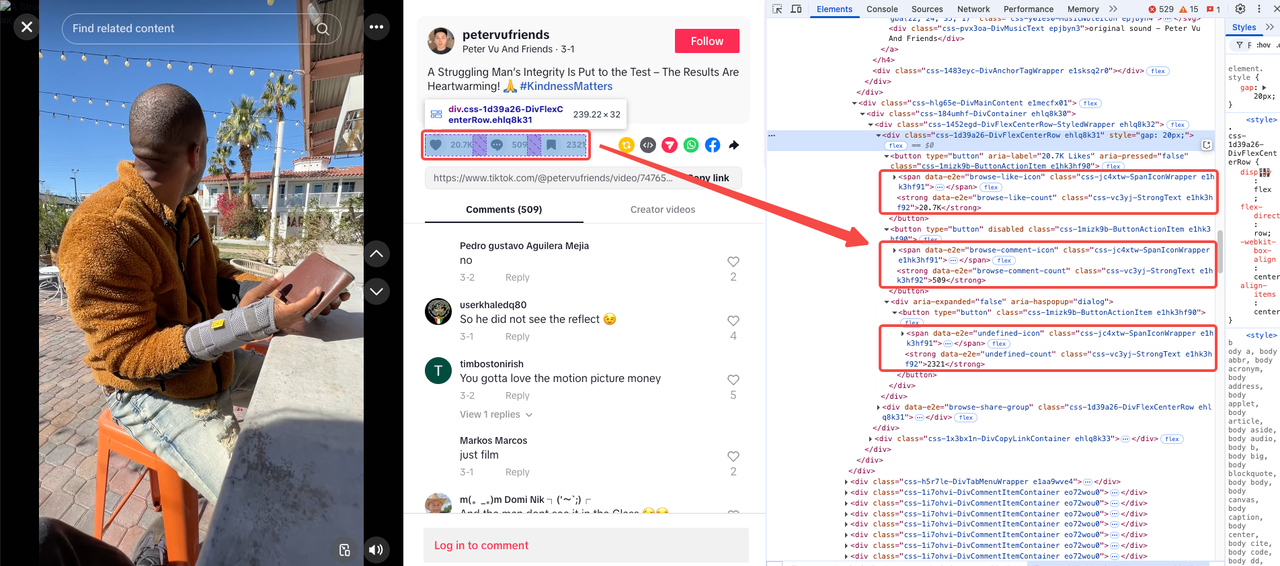
To simplify your scraping process, here’s a summary of the essential selectors:
- Video URL:
<meta property="og:url"> - Video Description:
['span.css-j2a19r-SpanText'] - Music Title:
['.css-pvx3oa-DivMusicText'] - Upload Date:
['span[data-e2e="browser-nickname"] span:last-child'] - Tags:
[data-e2e="search-common-link"] - View Count:
[data-e2e="video-views"] - Like Count:
[data-e2e="like-count"] - Comment Count:
[data-e2e="comment-count"] - Share Count:
[data-e2e="share-count"] - Bookmark Count:
[data-e2e="undefined-count"]
Congratulations! You now fully understand how to locate the necessary data. Next, let’s officially build the scraper!
Complete Scraping Code
Skipping unnecessary explanations—here's the ready-to-use scraping code for immediate implementation:
Python
from playwright.async_api import async_playwright
import asyncio, random, json, logging, time, os, yt_dlp
from urllib.parse import urlparse
# Configure logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('tiktok_scraper.log'),
logging.StreamHandler()
]
)
class TikTokScraper:
def __init__(self):
self.DOWNLOAD_VIDEO = True
self.SAVE_DIR = "downloaded_videos"
self.USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
self.VIEWPORT = {'width': 1280, 'height': 720}
self.TIMEOUT = 300 # 5 minute timeout
async def random_sleep(self, min_seconds=1, max_seconds=3):
"""Random Delay"""
delay = random.uniform(min_seconds, max_seconds)
logging.info(f"Sleeping for {delay:.2f} seconds...")
await asyncio.sleep(delay)
async def handle_captcha(self, page):
"""Handling verification codes"""
try:
captcha_dialog = page.locator('div[role="dialog"]')
if await captcha_dialog.count() > 0 and await captcha_dialog.is_visible():
logging.warning("CAPTCHA detected. Please solve it manually.")
await page.wait_for_selector('div[role="dialog"]', state='detached', timeout=self.TIMEOUT*1000)
logging.info("CAPTCHA solved. Resuming...")
await self.random_sleep(0.5, 1)
except Exception as e:
logging.error(f"Error handling CAPTCHA: {str(e)}")
async def extract_video_info(self, page, video_url):
"""Extract video details"""
logging.info(f"Extracting info from: {video_url}")
try:
await page.goto(video_url, wait_until="networkidle")
await self.random_sleep(2, 4)
await self.handle_captcha(page)
# Waiting for key elements to load
await page.wait_for_selector('[data-e2e="like-count"]', timeout=10000)
video_info = await page.evaluate("""() => {
const getTextContent = (selectors) => {
for (let selector of selectors) {
const element = document.querySelector(selector);
if (element && element.textContent.trim()) {
return element.textContent.trim();
}
}
return 'N/A';
};
const getTags = () => {
const tagElements = document.querySelectorAll('a[data-e2e="search-common-link"]');
return Array.from(tagElements).map(el => el.textContent.trim());
};
return {
likes: getTextContent(['[data-e2e="like-count"]', '[data-e2e="browse-like-count"]']),
comments: getTextContent(['[data-e2e="comment-count"]', '[data-e2e="browse-comment-count"]']),
shares: getTextContent(['[data-e2e="share-count"]']),
bookmarks: getTextContent(['[data-e2e="undefined-count"]']),
views: getTextContent(['[data-e2e="video-views"]']),
description: getTextContent(['span.css-j2a19r-SpanText']),
musicTitle: getTextContent(['.css-pvx3oa-DivMusicText']),
date: getTextContent(['span[data-e2e="browser-nickname"] span:last-child']),
author: getTextContent(['a[data-e2e="browser-username"]']),
tags: getTags(),
videoUrl: window.location.href
};
}""")
logging.info(f"Successfully extracted info for: {video_url}")
return video_info
except Exception as e:
logging.error(f"Failed to extract info from {video_url}: {str(e)}")
return None
def download_video(self, video_url):
"""Download Video"""
if not os.path.exists(self.SAVE_DIR):
os.makedirs(self.SAVE_DIR)
ydl_opts = {
'outtmpl': os.path.join(self.SAVE_DIR, '%(id)s.%(ext)s'),
'format': 'best',
'quiet': False,
'no_warnings': False,
'ignoreerrors': True
}
try:
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(video_url, download=True)
filename = ydl.prepare_filename(info)
logging.info(f"Video successfully downloaded: {filename}")
return filename
except Exception as e:
logging.error(f"Error downloading video: {str(e)}")
return None
async def scrape_single_video(self, video_url):
"""Scrape the single short"""
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
viewport=self.VIEWPORT,
user_agent=self.USER_AGENT,
)
page = await context.new_page()
result = {}
try:
# Extract shorts information
video_info = await self.extract_video_info(page, video_url)
if not video_info:
raise Exception("Failed to extract video info")
result.update(video_info)
# Download TikTok shorts
if self.DOWNLOAD_VIDEO:
filename = self.download_video(video_url)
if filename:
result['local_path'] = filename
except Exception as e:
logging.error(f"Error scraping video: {str(e)}")
finally:
await browser.close()
return result
def save_results(self, data, filename="tiktok_video_data.json"):
"""Save the results to a JSON file"""
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=2, ensure_ascii=False)
logging.info(f"Results saved to {filename}")
async def main():
# Initialize the crawler
scraper = TikTokScraper()
# Target TikTok short's URL
video_url = "https://www.tiktok.com/@petervufriends/video/7476546872253893934" # Just as an reference
# scrape the short
video_data = await scraper.scrape_single_video(video_url)
# save the scraping result
if video_data:
scraper.save_results(video_data)
logging.info("\nScraping completed. Results:")
for key, value in video_data.items():
logging.info(f"{key}: {value}")
else:
logging.error("Failed to scrape video data")
if __name__ == "__main__":
asyncio.run(main())Scraping Result
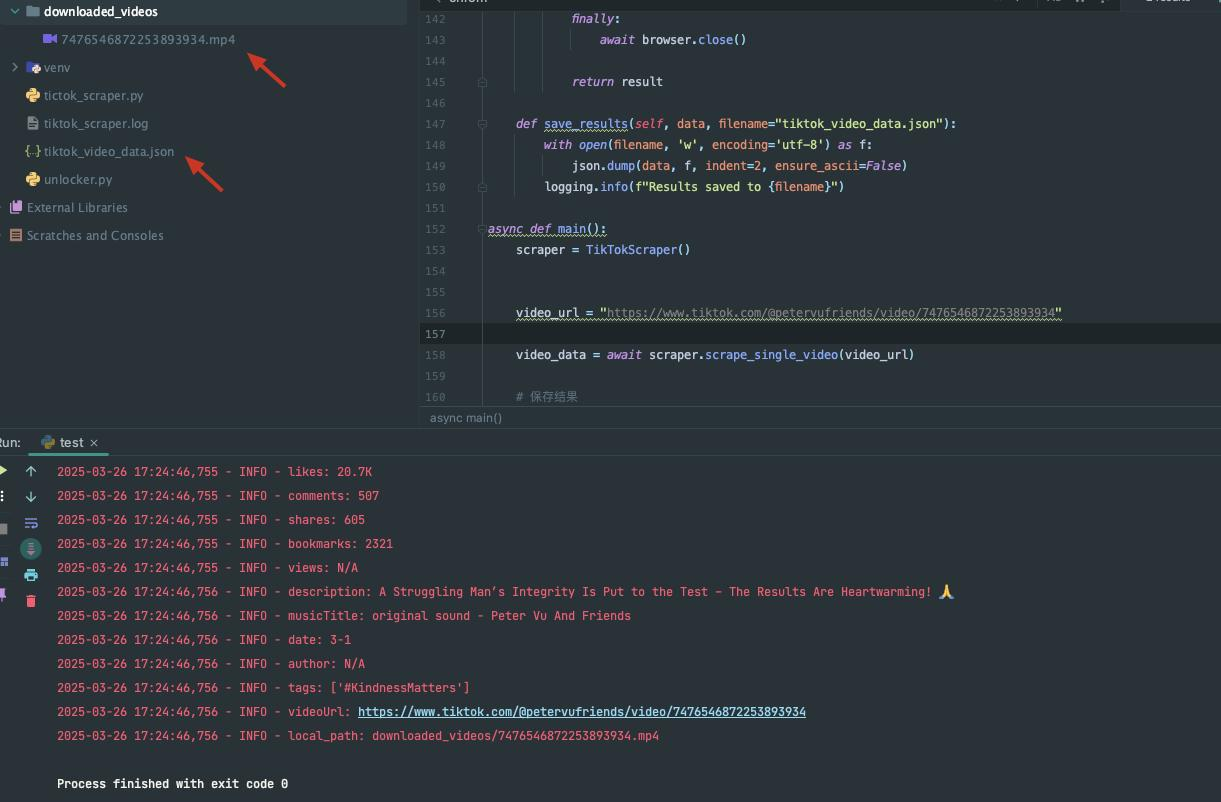
Obviously, we need complex programming and measures: set delays, bypass CAPTCHA, etc. to achieve data crawling. So how to quickly obtain TikTok data? Powerful third-party Scraping API is your best choice!
Scraping API: Collect TikTok Data Easily
Why use an API to retrieve Walmart product details?
1. Improved Efficiency
Manual search for product data is slow and error-prone. API allows automatic retrieval of Walmart product information, ensuring fast and consistent data collection.
2. Accurate, real-time data
The Scrapeless API extracts data directly from Walmart product pages, ensuring that the retrieved information is up-to-date and accurate. This prevents errors caused by delayed manual entry or outdated sources.
3. Applicable to various business scenarios
- Price monitoring: Compare competitor prices and adjust pricing strategies.
- Inventory tracking: Check product availability to optimize supply chain management.
- Review analysis: Analyze customer feedback to improve products and services.
- Market research: Identify popular products and make informed business decisions.
What does TikTok Scraper do?
This TikTok data scraper is a powerful unofficial TikTok API that provides you with large-scale TikTok data for your own data projects, business reports, and as a basis for new applications. With this best TikTok scraper, you can get:
- All results from the selected hashtag including details: popular videos, timestamps, views, shares, comments, and number of videos, etc.
- All posts from the selected user profile including details: name, nickname, ID, bio, followers/following, plays, shares, and comments, etc.
- Individual video posts with specific video URLs.
- Video and music related data.
Scraping TikTok data using API
Step 1. Create your API Token
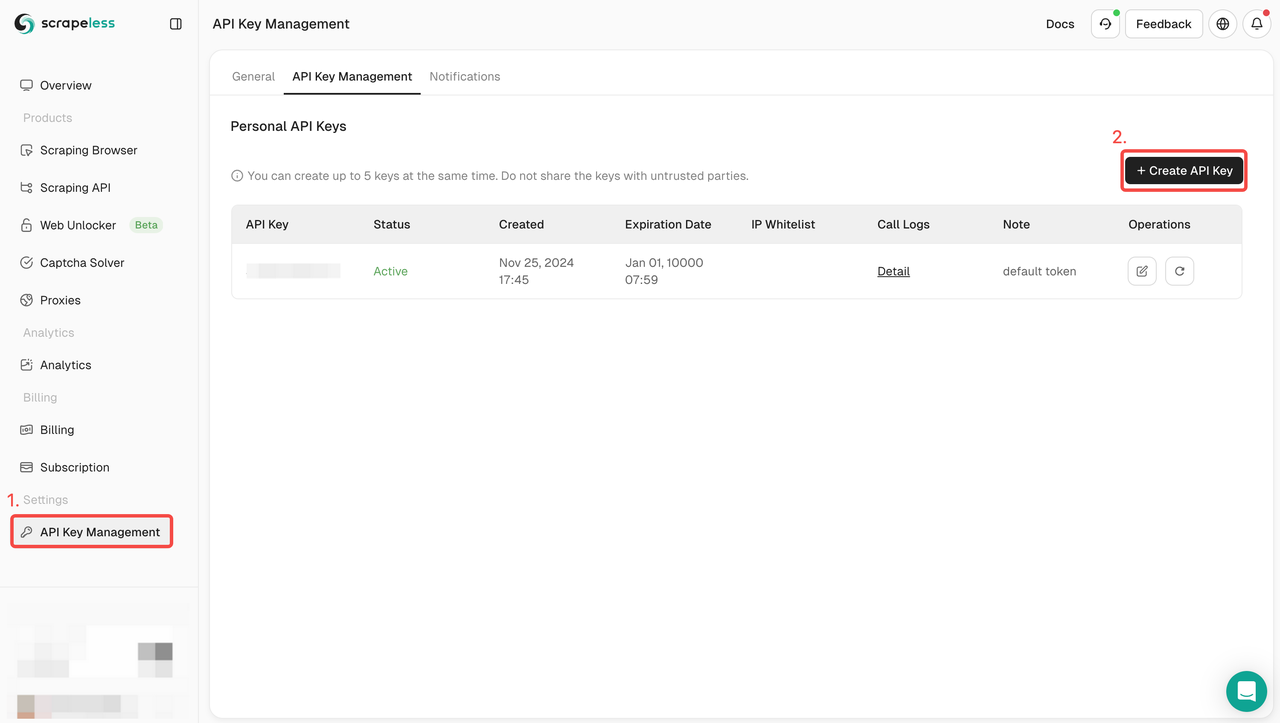
To get started, you’ll need to obtain your API Key from the Scrapeless Dashboard:
- Log in to the Scrapeless Dashboard.
- Navigate to API Key Management.
- Click Create to generate your unique API Key.
- Once created, simply click on the API Key to copy it.
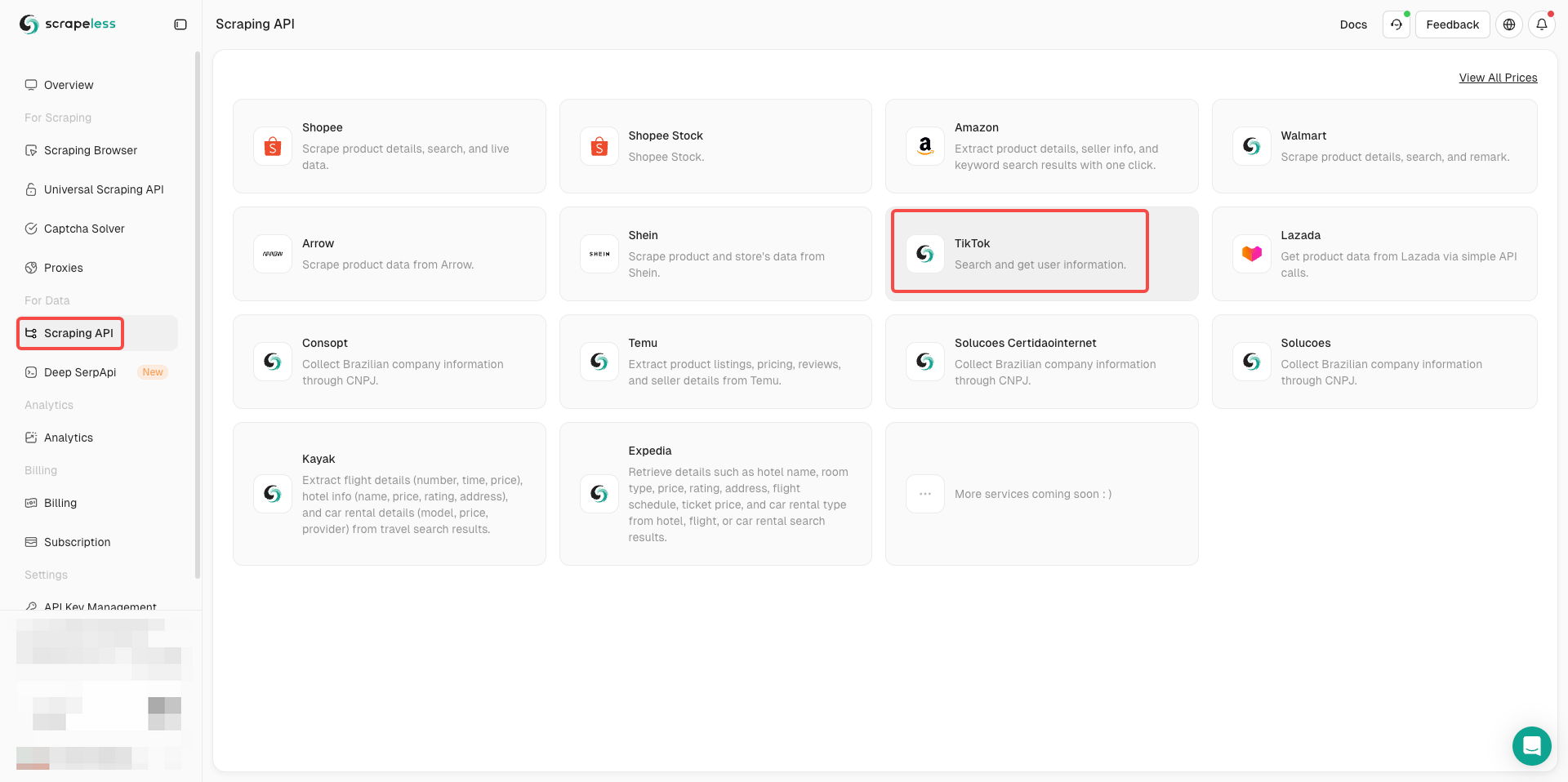
Step 2. Enter TikTok API
- Click Scraping API under For Data
- Find TikTok and enter
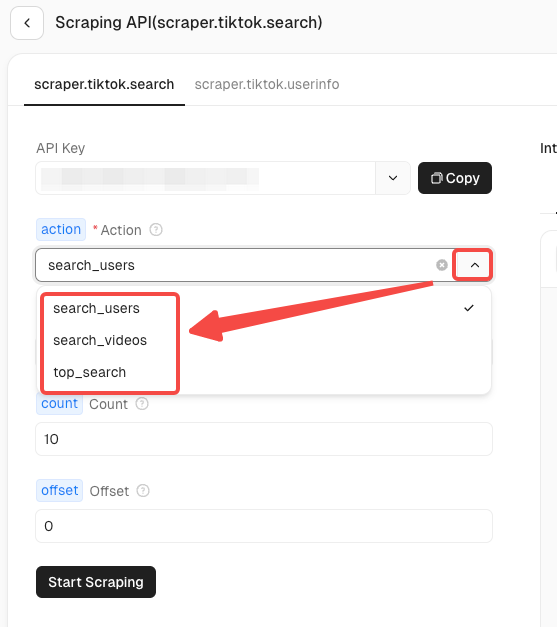
Step 3. Request parameter configuration
The TikTok actor currently has two scraping scenarios:
- TikTok search info: Scrape video search results for specific keywords.
- TikTok user info: Scrape profile information of a specified user.
There will be different action requests in each scenario. You can click the folding arrow to find the data information you need to scrape accurately. Take TikTok search info as an example:
Are you ready? After understanding the basic information, we can officially start scraping data!
- Now you only need to complete the parameter configuration on the left side of the actor according to your needs
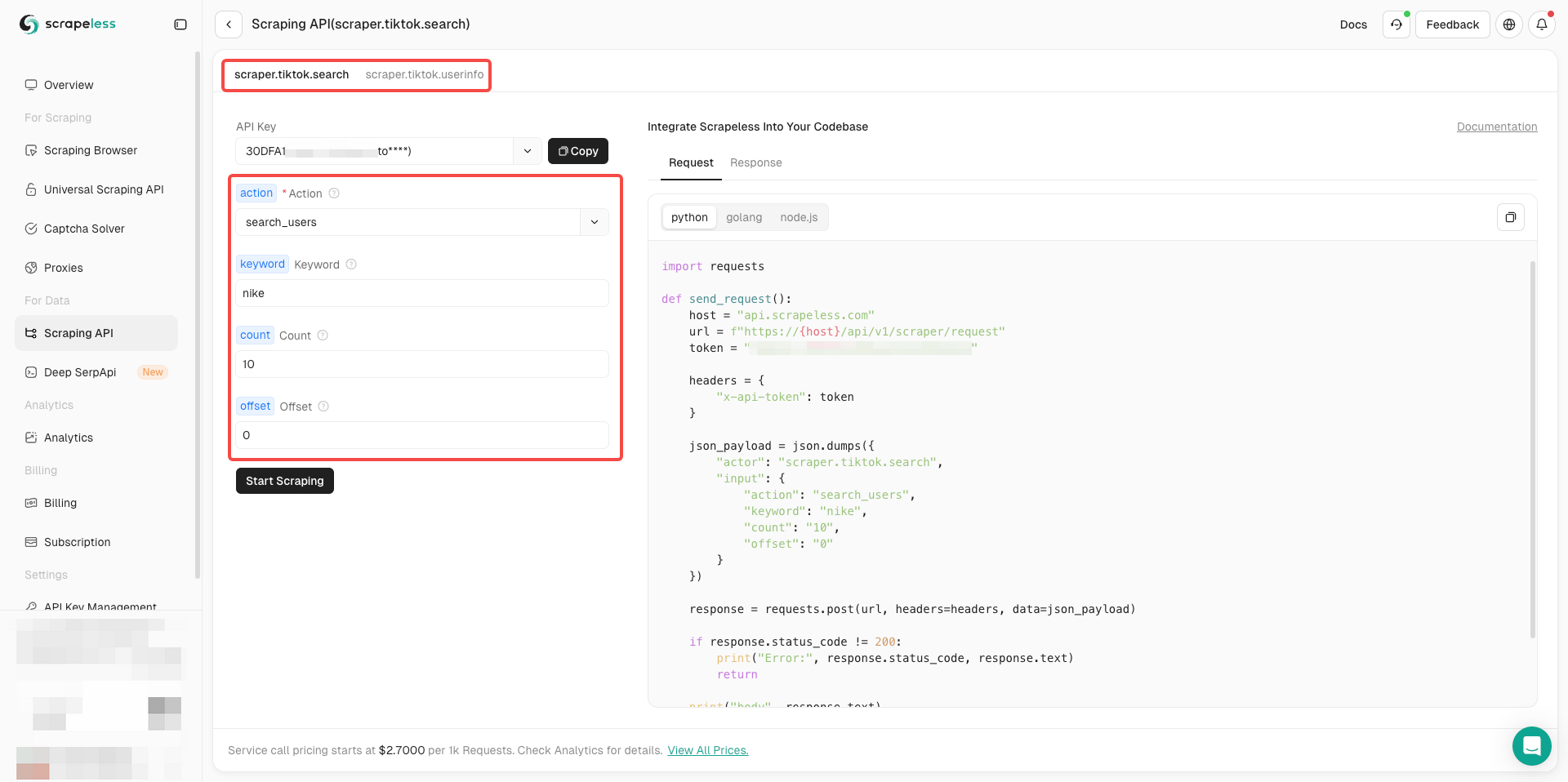
- After confirming that everything is correct, just click Star Scraping to easily get the scraping results.
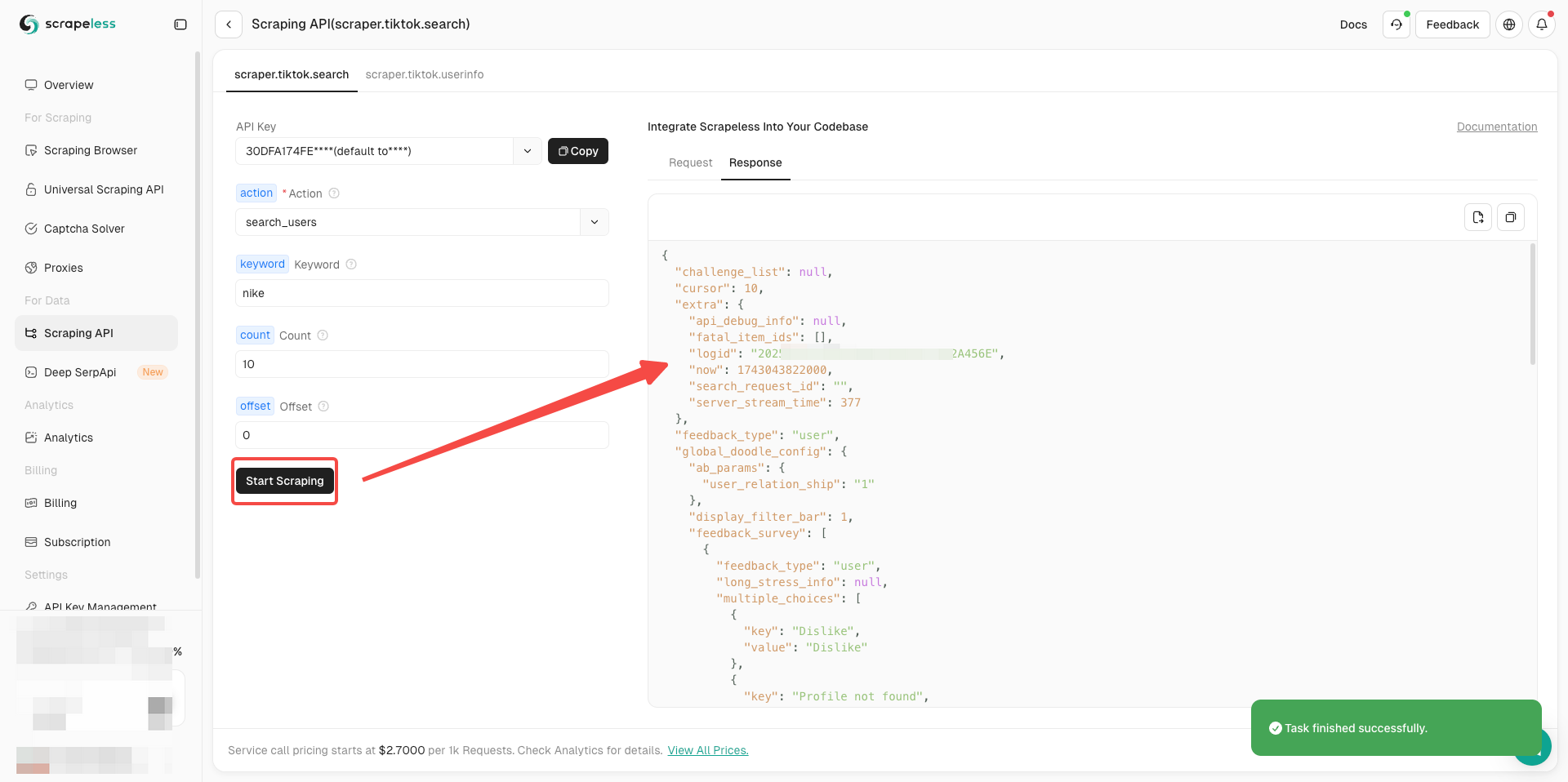
Get the TikTok Video Data Now!
From now on, you should have a working scraper that can extract data from TikTok. This is a great start, but you can definitely go further.
Whether you are analyzing TikTok trends, conducting research, or satisfying your data curiosity, you now have powerful tools to explore the TikTok data warehouse without many headaches.
The Scrapeless Scraping API saves you from the hassle of complex code. Simply configure a few parameters to get the latest data instantly.
At Scrapeless, we only access publicly available data while strictly complying with applicable laws, regulations, and website privacy policies. The content in this blog is for demonstration purposes only and does not involve any illegal or infringing activities. We make no guarantees and disclaim all liability for the use of information from this blog or third-party links. Before engaging in any scraping activities, consult your legal advisor and review the target website's terms of service or obtain the necessary permissions.


